 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
May 13, 2026Traditional retrieval pipelines optimize utility through stages of candidate retrieval and reranking, where ranking operates over a predefined candidate set. Large Language Models (LLMs) broaden this into a generative process: given a candidate pool, an LLM can generate a subset and order it within a single autoregressive pass. However, this flexibility introduces a new optimization challenge: the model must search a combinatorial output space while receiving utility feedback only after the full ranked list is generated. Because this feedback is defined over the completed sequence, it cannot distinguish whether a poor result arises from failing to generate a relevant subset or from failing to rank that subset correctly. This credit assignment gap makes end-to-end optimization unstable and sample-inefficient. Existing systems often address this by separating candidate generation from ranking. However, such decoupling remains misaligned with downstream utility because ranking is limited by the candidate set it receives. To bridge this gap, we propose a unified framework that performs both within a single autoregressive rollout and optimizes them end-to-end via factorized group-relative policy optimization (F-GRPO). Our framework factorizes the policy into candidate generation and ranking while sharing a single LLM backbone, and jointly trains them with an order-invariant coverage reward and a position-aware utility reward. To address the resulting phase-specific credit assignment problem, we use separate group-relative advantages for generation and ranking within a two-phase sequence-level objective. Across sequential recommendation and multi-hop question answering benchmarks, F-GRPO improves top-ranked performance over GRPO and decoupled baselines, outperforms supervised alternatives, and remains competitive with strong zero-shot rerankers, with no architectural changes at inference time.
MASS-DPO: Multi-negative Active Sample Selection for Direct Policy Optimization
May 11, 2026Multi-negative preference optimization under the Plackett--Luce (PL) model extends Direct Preference Optimization (DPO) by leveraging comparative signals across one preferred and multiple rejected responses. However, optimizing over large negative pools is costly, and many candidates contribute redundant gradients due to their similar effects on policy updates. We introduce MASS-DPO, a multi-negative active sample selection method that derives a PL-specific Fisher-information objective for selecting compact, informative negative subsets within each prompt. The resulting log-determinant objective selects negatives that contribute complementary information for policy updates, yielding compact subsets that retain the full pool's information while reducing redundancy. In practice, this favors negatives whose gradients cover different update directions, reducing redundant signal from near-duplicate candidates while preserving the most useful training information. Across four benchmarks spanning recommendation and multiple-choice QA and three model families, MASS-DPO consistently exceeds or matches existing methods in accuracy, improves Recall/NDCG and margin-based optimization dynamics, and delivers stronger alignment with substantially fewer negatives.
Skill-R1: Agent Skill Evolution via Reinforcement Learning
May 10, 2026Agentic large language models often rely on skills, reusable natural language procedures that guide planning, action, and tool use. In practice, skills are typically improved through prompt engineering or by aligning the task LLM itself, which is costly, model-specific, and often infeasible for closed-source models. Skill optimization is not a one-step problem but a recurrent process with two coupled levels of credit assignment: a useful skill must improve rollout quality under current conditioning, while a useful revision must turn observed outcomes into a better skill for the next round. We propose Skill-R1, a reinforcement learning framework for instance-level recurrent skill optimization from verifiable rewards. Rather than updating the task LLM, Skill-R1 trains a lightweight skill generator that conditions on the task context, prior rollouts, and their verified outcomes to produce skills that steer a frozen task LLM. This preserves black-box compatibility with both open- and closed-source models while making adaptation substantially cheaper than model-level updates. Skill-R1 proceeds over multiple generations: at each step, the current skill induces rollouts whose verified outcomes are fed back to produce the next revision. To optimize this recurrent process, we introduce a bi-level group-relative policy optimization objective combining intra-generation and inter-generation advantages. The intra-generation term compares rollouts under shared skill conditioning, while the inter-generation term rewards revisions that improve behavior across successive generations. Together, these provide a principled objective for directional skill evolution rather than one-shot self-refinement. Empirically, Skill-R1 achieves consistent gains over no-skill baselines and standard GRPO across benchmarks with verifiable rewards, with particularly strong improvements on complex, multi-step tasks.
WS-GRPO: Weakly-Supervised Group-Relative Policy Optimization for Rollout-Efficient Reasoning
Feb 19, 2026Group Relative Policy Optimization (GRPO) is effective for training language models on complex reasoning. However, since the objective is defined relative to a group of sampled trajectories, extended deliberation can create more chances to realize relative gains, leading to inefficient reasoning and overthinking, and complicating the trade-off between correctness and rollout efficiency. Controlling this behavior is difficult in practice, considering (i) Length penalties are hard to calibrate because longer rollouts may reflect harder problems that require longer reasoning, penalizing tokens risks truncating useful reasoning along with redundant continuation; and (ii) supervision that directly indicates when to continue or stop is typically unavailable beyond final answer correctness. We propose Weakly Supervised GRPO (WS-GRPO), which improves rollout efficiency by converting terminal rewards into correctness-aware guidance over partial trajectories. Unlike global length penalties that are hard to calibrate, WS-GRPO trains a preference model from outcome-only correctness to produce prefix-level signals that indicate when additional continuation is beneficial. Thus, WS-GRPO supplies outcome-derived continue/stop guidance, reducing redundant deliberation while maintaining accuracy. We provide theoretical results and empirically show on reasoning benchmarks that WS-GRPO substantially reduces rollout length while remaining competitive with GRPO baselines.
AMPS: Adaptive Modality Preference Steering via Functional Entropy
Feb 13, 2026Multimodal Large Language Models (MLLMs) often exhibit significant modality preference, which is a tendency to favor one modality over another. Depending on the input, they may over-rely on linguistic priors relative to visual evidence, or conversely over-attend to visually salient but facts in textual contexts. Prior work has applied a uniform steering intensity to adjust the modality preference of MLLMs. However, strong steering can impair standard inference and increase error rates, whereas weak steering is often ineffective. In addition, because steering sensitivity varies substantially across multimodal instances, a single global strength is difficult to calibrate. To address this limitation with minimal disruption to inference, we introduce an instance-aware diagnostic metric that quantifies each modality's information contribution and reveals sample-specific susceptibility to steering. Building on these insights, we propose a scaling strategy that reduces steering for sensitive samples and a learnable module that infers scaling patterns, enabling instance-aware control of modality preference. Experimental results show that our instance-aware steering outperforms conventional steering in modulating modality preference, achieving effective adjustment while keeping generation error rates low.
Evaluation on Entity Matching in Recommender Systems
Jan 23, 2026Entity matching is a crucial component in various recommender systems, including conversational recommender systems (CRS) and knowledge-based recommender systems. However, the lack of rigorous evaluation frameworks for cross-dataset entity matching impedes progress in areas such as LLM-driven conversational recommendations and knowledge-grounded dataset construction. In this paper, we introduce Reddit-Amazon-EM, a novel dataset comprising naturally occurring items from Reddit and the Amazon '23 dataset. Through careful manual annotation, we identify corresponding movies across Reddit-Movies and Amazon'23, two existing recommender system datasets with inherently overlapping catalogs. Leveraging Reddit-Amazon-EM, we conduct a comprehensive evaluation of state-of-the-art entity matching methods, including rule-based, graph-based, lexical-based, embedding-based, and LLM-based approaches. For reproducible research, we release our manually annotated entity matching gold set and provide the mapping between the two datasets using the best-performing method from our experiments. This serves as a valuable resource for advancing future work on entity matching in recommender systems.
In-context Ranking Preference Optimization
Apr 21, 2025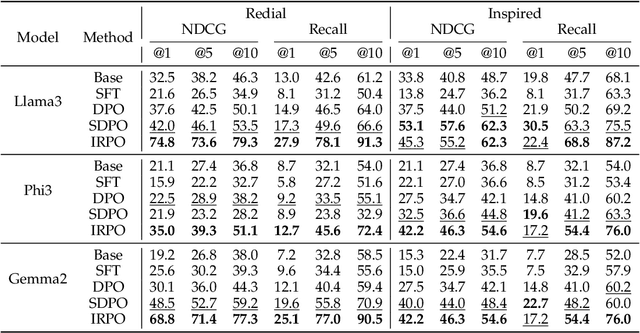
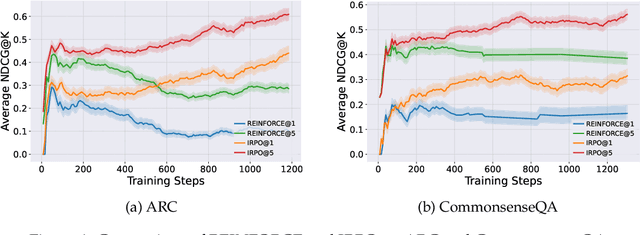
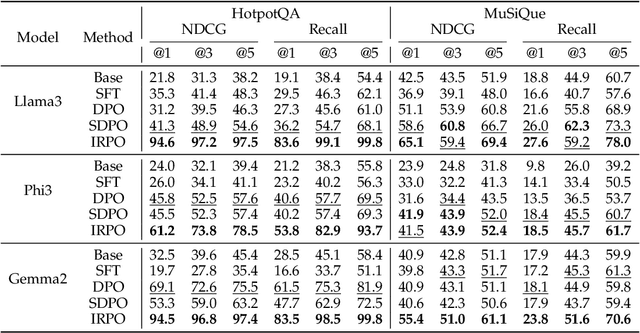
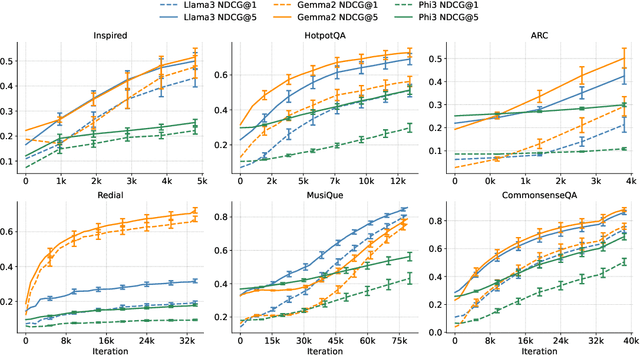
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.
From Reviews to Dialogues: Active Synthesis for Zero-Shot LLM-based Conversational Recommender System
Apr 21, 2025



Conversational recommender systems (CRS) typically require extensive domain-specific conversational datasets, yet high costs, privacy concerns, and data-collection challenges severely limit their availability. Although Large Language Models (LLMs) demonstrate strong zero-shot recommendation capabilities, practical applications often favor smaller, internally managed recommender models due to scalability, interpretability, and data privacy constraints, especially in sensitive or rapidly evolving domains. However, training these smaller models effectively still demands substantial domain-specific conversational data, which remains challenging to obtain. To address these limitations, we propose an active data augmentation framework that synthesizes conversational training data by leveraging black-box LLMs guided by active learning techniques. Specifically, our method utilizes publicly available non-conversational domain data, including item metadata, user reviews, and collaborative signals, as seed inputs. By employing active learning strategies to select the most informative seed samples, our approach efficiently guides LLMs to generate synthetic, semantically coherent conversational interactions tailored explicitly to the target domain. Extensive experiments validate that conversational data generated by our proposed framework significantly improves the performance of LLM-based CRS models, effectively addressing the challenges of building CRS in no- or low-resource scenarios.