 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective X Training: Feedback Conditioning Improves Scaling Across all LLM Training Stages
May 19, 2026We tackle the question of how to scale more efficiently across the many, ever-growing stages of current LLM training pipelines. Our guiding intuition stems from the fact that the dynamics of later stages of the pipeline, e.g. post-training, can be used to inform earlier stages such as pre-training. To this end, we propose Introspective Training (or IXT), inspired by offline reward-conditioned reinforcement learning and applicable to any stage of training. IXT uses a thinking reward model to annotate data with natural language critique based feedback, enabling quality aware training from the earliest stages of the pipeline. Models are then trained by prefix-conditioning the data with the generated feedback -- ensuring that not all tokens are treated equally starting much earlier in training than usual. Comprehensive experiments on 7.5-12B transformer-based dense LLMs trained from scratch all the way up to 18 Trillion tokens seen show that our method: bends scaling curves resulting in up to 2.8x more compute efficiency generally; and reaches performance levels unachievable for models trained otherwise in domains such as math and code.
MASS-DPO: Multi-negative Active Sample Selection for Direct Policy Optimization
May 11, 2026Multi-negative preference optimization under the Plackett--Luce (PL) model extends Direct Preference Optimization (DPO) by leveraging comparative signals across one preferred and multiple rejected responses. However, optimizing over large negative pools is costly, and many candidates contribute redundant gradients due to their similar effects on policy updates. We introduce MASS-DPO, a multi-negative active sample selection method that derives a PL-specific Fisher-information objective for selecting compact, informative negative subsets within each prompt. The resulting log-determinant objective selects negatives that contribute complementary information for policy updates, yielding compact subsets that retain the full pool's information while reducing redundancy. In practice, this favors negatives whose gradients cover different update directions, reducing redundant signal from near-duplicate candidates while preserving the most useful training information. Across four benchmarks spanning recommendation and multiple-choice QA and three model families, MASS-DPO consistently exceeds or matches existing methods in accuracy, improves Recall/NDCG and margin-based optimization dynamics, and delivers stronger alignment with substantially fewer negatives.
Reasoning Through Chess: How Reasoning Evolves from Data Through Fine-Tuning and Reinforcement Learning
Apr 06, 2026How can you get a language model to reason in a task it natively struggles with? We study how reasoning evolves in a language model -- from supervised fine-tuning (SFT) to reinforcement learning (RL) -- by analyzing how a set of theoretically-inspired datasets impacts language model performance in chess. We find that fine-tuning a model to directly predict the best move leads to effective RL and the strongest downstream performance -- however, the RL step elicits unfaithful reasoning (reasoning inconsistent with the chosen move). Alternatively, training on multi-move trajectories yields comparable downstream performance with faithful reasoning and more stable RL. We show that RL induces a substantial positive shift in the distribution of move quality and reduces hallucination rates as a side effect. Finally, we find several SFT-checkpoint metrics -- metrics spanning evaluation performance, hallucination rates, and reasoning quality -- to be predictive of post-RL model performance. We release checkpoints and final models as well as training data, evaluations, and code which allowed us to surpass leading open-source reasoning models in chess with a 7B-parameter model.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
Preference-Based Learning in Audio Applications: A Systematic Analysis
Nov 17, 2025



Despite the parallel challenges that audio and text domains face in evaluating generative model outputs, preference learning remains remarkably underexplored in audio applications. Through a PRISMA-guided systematic review of approximately 500 papers, we find that only 30 (6%) apply preference learning to audio tasks. Our analysis reveals a field in transition: pre-2021 works focused on emotion recognition using traditional ranking methods (rankSVM), while post-2021 studies have pivoted toward generation tasks employing modern RLHF frameworks. We identify three critical patterns: (1) the emergence of multi-dimensional evaluation strategies combining synthetic, automated, and human preferences; (2) inconsistent alignment between traditional metrics (WER, PESQ) and human judgments across different contexts; and (3) convergence on multi-stage training pipelines that combine reward signals. Our findings suggest that while preference learning shows promise for audio, particularly in capturing subjective qualities like naturalness and musicality, the field requires standardized benchmarks, higher-quality datasets, and systematic investigation of how temporal factors unique to audio impact preference learning frameworks.
Long Grounded Thoughts: Distilling Compositional Visual Reasoning Chains at Scale
Nov 07, 2025Recent progress in multimodal reasoning has been driven largely by undisclosed datasets and proprietary data synthesis recipes, leaving open questions about how to systematically build large-scale, vision-centric reasoning datasets, particularly for tasks that go beyond visual math. In this work, we introduce a new reasoning data generation framework spanning diverse skills and levels of complexity with over 1M high-quality synthetic vision-centric questions. The dataset also includes preference data and instruction prompts supporting both offline and online RL. Our synthesis framework proceeds in two stages: (1) scale; and (2) complexity. Reasoning traces are then synthesized through a two-stage process that leverages VLMs and reasoning LLMs, producing CoT traces for VLMs that capture the richness and diverse cognitive behaviors found in frontier reasoning models. Remarkably, we show that finetuning Qwen2.5-VL-7B on our data outperforms all open-data baselines across all evaluated vision-centric benchmarks, and even surpasses strong closed-data models such as MiMo-VL-7B-RL on V* Bench, CV-Bench and MMStar-V. Perhaps most surprising, despite being entirely vision-centric, our data transfers positively to text-only reasoning (MMLU-Pro) and audio reasoning (MMAU), demonstrating its effectiveness. Similarly, despite not containing videos or embodied visual data, we observe notable gains when evaluating on a single-evidence embodied QA benchmark (NiEH). Finally, we use our data to analyze the entire VLM post-training pipeline. Our empirical analysis highlights that (i) SFT on high-quality data with non-linear reasoning traces is essential for effective online RL, (ii) staged offline RL matches online RL's performance while reducing compute demands, and (iii) careful SFT on high quality data can substantially improve out-of-domain, cross-modality transfer.
Beyond Needle(s) in the Embodied Haystack: Environment, Architecture, and Training Considerations for Long Context Reasoning
May 22, 2025We introduce $\infty$-THOR, a new framework for long-horizon embodied tasks that advances long-context understanding in embodied AI. $\infty$-THOR provides: (1) a generation framework for synthesizing scalable, reproducible, and unlimited long-horizon trajectories; (2) a novel embodied QA task, Needle(s) in the Embodied Haystack, where multiple scattered clues across extended trajectories test agents' long-context reasoning ability; and (3) a long-horizon dataset and benchmark suite featuring complex tasks that span hundreds of environment steps, each paired with ground-truth action sequences. To enable this capability, we explore architectural adaptations, including interleaved Goal-State-Action modeling, context extension techniques, and Context Parallelism, to equip LLM-based agents for extreme long-context reasoning and interaction. Experimental results and analyses highlight the challenges posed by our benchmark and provide insights into training strategies and model behaviors under long-horizon conditions. Our work provides a foundation for the next generation of embodied AI systems capable of robust, long-term reasoning and planning.
Collaborating Action by Action: A Multi-agent LLM Framework for Embodied Reasoning
Apr 24, 2025Collaboration is ubiquitous and essential in day-to-day life -- from exchanging ideas, to delegating tasks, to generating plans together. This work studies how LLMs can adaptively collaborate to perform complex embodied reasoning tasks. To this end we introduce MINDcraft, an easily extensible platform built to enable LLM agents to control characters in the open-world game of Minecraft; and MineCollab, a benchmark to test the different dimensions of embodied and collaborative reasoning. An experimental study finds that the primary bottleneck in collaborating effectively for current state-of-the-art agents is efficient natural language communication, with agent performance dropping as much as 15% when they are required to communicate detailed task completion plans. We conclude that existing LLM agents are ill-optimized for multi-agent collaboration, especially in embodied scenarios, and highlight the need to employ methods beyond in-context and imitation learning. Our website can be found here: https://mindcraft-minecollab.github.io/
TALES: Text Adventure Learning Environment Suite
Apr 22, 2025Reasoning is an essential skill to enable Large Language Models (LLMs) to interact with the world. As tasks become more complex, they demand increasingly sophisticated and diverse reasoning capabilities for sequential decision-making, requiring structured reasoning over the context history to determine the next best action. We introduce TALES, a diverse collection of synthetic and human-written text-adventure games designed to challenge and evaluate diverse reasoning capabilities. We present results over a range of LLMs, open- and closed-weights, performing a qualitative analysis on the top performing models. Despite an impressive showing on synthetic games, even the top LLM-driven agents fail to achieve 15% on games designed for human enjoyment. Code and visualization of the experiments can be found at https://microsoft.github.io/tales.
In-context Ranking Preference Optimization
Apr 21, 2025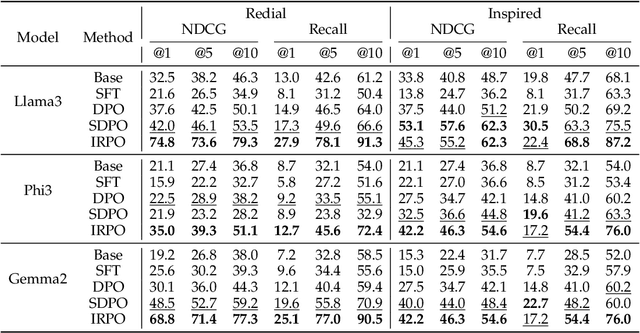
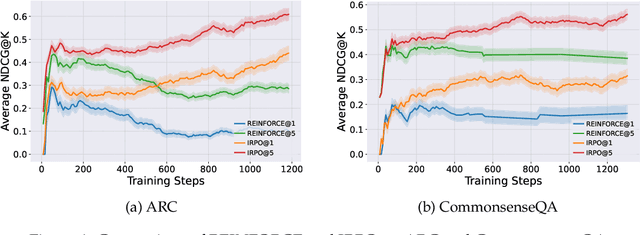
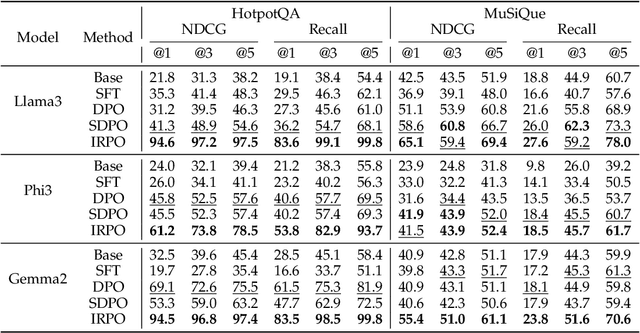
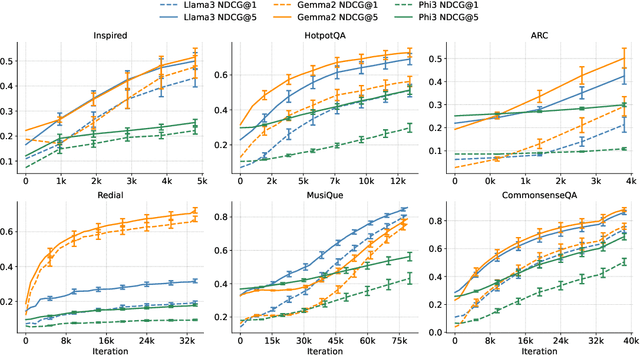
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.