 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Foundation Model-Powered Recommender Systems: From Feature-Based, Generative to Agentic Paradigms
Apr 23, 2025



Recommender systems (RS) have become essential in filtering information and personalizing content for users. RS techniques have traditionally relied on modeling interactions between users and items as well as the features of content using models specific to each task. The emergence of foundation models (FMs), large scale models trained on vast amounts of data such as GPT, LLaMA and CLIP, is reshaping the recommendation paradigm. This survey provides a comprehensive overview of the Foundation Models for Recommender Systems (FM4RecSys), covering their integration in three paradigms: (1) Feature-Based augmentation of representations, (2) Generative recommendation approaches, and (3) Agentic interactive systems. We first review the data foundations of RS, from traditional explicit or implicit feedback to multimodal content sources. We then introduce FMs and their capabilities for representation learning, natural language understanding, and multi-modal reasoning in RS contexts. The core of the survey discusses how FMs enhance RS under different paradigms. Afterward, we examine FM applications in various recommendation tasks. Through an analysis of recent research, we highlight key opportunities that have been realized as well as challenges encountered. Finally, we outline open research directions and technical challenges for next-generation FM4RecSys. This survey not only reviews the state-of-the-art methods but also provides a critical analysis of the trade-offs among the feature-based, the generative, and the agentic paradigms, outlining key open issues and future research directions.
Do RAG Systems Cover What Matters? Evaluating and Optimizing Responses with Sub-Question Coverage
Oct 20, 2024



Evaluating retrieval-augmented generation (RAG) systems remains challenging, particularly for open-ended questions that lack definitive answers and require coverage of multiple sub-topics. In this paper, we introduce a novel evaluation framework based on sub-question coverage, which measures how well a RAG system addresses different facets of a question. We propose decomposing questions into sub-questions and classifying them into three types -- core, background, and follow-up -- to reflect their roles and importance. Using this categorization, we introduce a fine-grained evaluation protocol that provides insights into the retrieval and generation characteristics of RAG systems, including three commercial generative answer engines: You.com, Perplexity AI, and Bing Chat. Interestingly, we find that while all answer engines cover core sub-questions more often than background or follow-up ones, they still miss around 50% of core sub-questions, revealing clear opportunities for improvement. Further, sub-question coverage metrics prove effective for ranking responses, achieving 82% accuracy compared to human preference annotations. Lastly, we also demonstrate that leveraging core sub-questions enhances both retrieval and answer generation in a RAG system, resulting in a 74% win rate over the baseline that lacks sub-questions.
Learn When to Trust Language Models: A Privacy-Centric Adaptive Model-Aware Approach
Apr 04, 2024Retrieval-augmented large language models (LLMs) have been remarkably competent in various NLP tasks. Despite their great success, the knowledge provided by the retrieval process is not always useful for improving the model prediction, since in some samples LLMs may already be quite knowledgeable and thus be able to answer the question correctly without retrieval. Aiming to save the cost of retrieval, previous work has proposed to determine when to do/skip the retrieval in a data-aware manner by analyzing the LLMs' pretraining data. However, these data-aware methods pose privacy risks and memory limitations, especially when requiring access to sensitive or extensive pretraining data. Moreover, these methods offer limited adaptability under fine-tuning or continual learning settings. We hypothesize that token embeddings are able to capture the model's intrinsic knowledge, which offers a safer and more straightforward way to judge the need for retrieval without the privacy risks associated with accessing pre-training data. Moreover, it alleviates the need to retain all the data utilized during model pre-training, necessitating only the upkeep of the token embeddings. Extensive experiments and in-depth analyses demonstrate the superiority of our model-aware approach.
Creating Suspenseful Stories: Iterative Planning with Large Language Models
Feb 27, 2024



Automated story generation has been one of the long-standing challenges in NLP. Among all dimensions of stories, suspense is very common in human-written stories but relatively under-explored in AI-generated stories. While recent advances in large language models (LLMs) have greatly promoted language generation in general, state-of-the-art LLMs are still unreliable when it comes to suspenseful story generation. We propose a novel iterative-prompting-based planning method that is grounded in two theoretical foundations of story suspense from cognitive psychology and narratology. This theory-grounded method works in a fully zero-shot manner and does not rely on any supervised story corpora. To the best of our knowledge, this paper is the first attempt at suspenseful story generation with LLMs. Extensive human evaluations of the generated suspenseful stories demonstrate the effectiveness of our method.
Foundation Models for Recommender Systems: A Survey and New Perspectives
Feb 17, 2024



Recently, Foundation Models (FMs), with their extensive knowledge bases and complex architectures, have offered unique opportunities within the realm of recommender systems (RSs). In this paper, we attempt to thoroughly examine FM-based recommendation systems (FM4RecSys). We start by reviewing the research background of FM4RecSys. Then, we provide a systematic taxonomy of existing FM4RecSys research works, which can be divided into four different parts including data characteristics, representation learning, model type, and downstream tasks. Within each part, we review the key recent research developments, outlining the representative models and discussing their characteristics. Moreover, we elaborate on the open problems and opportunities of FM4RecSys aiming to shed light on future research directions in this area. In conclusion, we recap our findings and discuss the emerging trends in this field.
Few-Shot Dialogue Summarization via Skeleton-Assisted Prompt Transfer
May 20, 2023



In real-world scenarios, labeled samples for dialogue summarization are usually limited (i.e., few-shot) due to high annotation costs for high-quality dialogue summaries. To efficiently learn from few-shot samples, previous works have utilized massive annotated data from other downstream tasks and then performed prompt transfer in prompt tuning so as to enable cross-task knowledge transfer. However, existing general-purpose prompt transfer techniques lack consideration for dialogue-specific information. In this paper, we focus on improving the prompt transfer from dialogue state tracking to dialogue summarization and propose Skeleton-Assisted Prompt Transfer (SAPT), which leverages skeleton generation as extra supervision that functions as a medium connecting the distinct source and target task and resulting in the model's better consumption of dialogue state information. To automatically extract dialogue skeletons as supervised training data for skeleton generation, we design a novel approach with perturbation-based probes requiring neither annotation effort nor domain knowledge. Training the model on such skeletons can also help preserve model capability during prompt transfer. Our method significantly outperforms existing baselines. In-depth analyses demonstrate the effectiveness of our method in facilitating cross-task knowledge transfer in few-shot dialogue summarization.
Calibrating Trust of Multi-Hop Question Answering Systems with Decompositional Probes
Apr 16, 2022

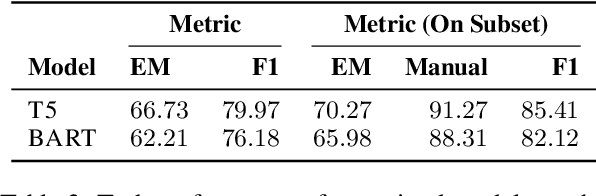
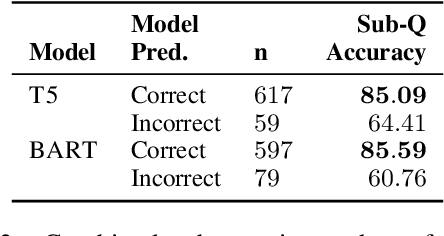
Multi-hop Question Answering (QA) is a challenging task since it requires an accurate aggregation of information from multiple context paragraphs and a thorough understanding of the underlying reasoning chains. Recent work in multi-hop QA has shown that performance can be boosted by first decomposing the questions into simpler, single-hop questions. In this paper, we explore one additional utility of the multi-hop decomposition from the perspective of explainable NLP: to create explanation by probing a neural QA model with them. We hypothesize that in doing so, users will be better able to construct a mental model of when the underlying QA system will give the correct answer. Through human participant studies, we verify that exposing the decomposition probes and answers to the probes to users can increase their ability to predict system performance on a question instance basis. We show that decomposition is an effective form of probing QA systems as well as a promising approach to explanation generation. In-depth analyses show the need for improvements in decomposition systems.
Guiding Neural Story Generation with Reader Models
Dec 16, 2021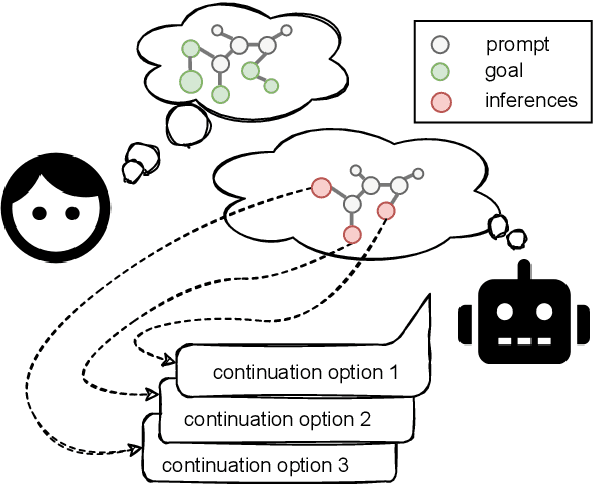

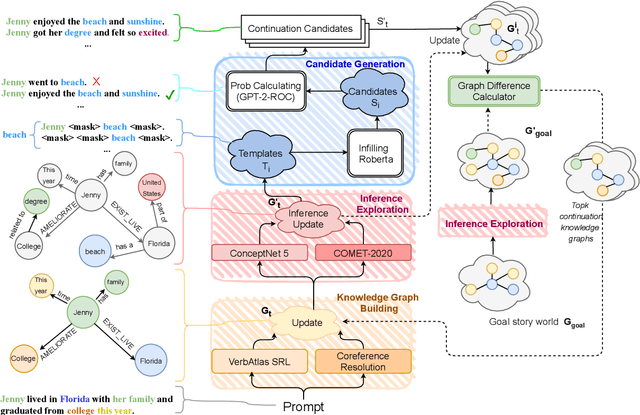

Automated storytelling has long captured the attention of researchers for the ubiquity of narratives in everyday life. However, it is challenging to maintain coherence and stay on-topic toward a specific ending when generating narratives with neural language models. In this paper, we introduce Story generation with Reader Models (StoRM), a framework in which a reader model is used to reason about the story should progress. A reader model infers what a human reader believes about the concepts, entities, and relations about the fictional story world. We show how an explicit reader model represented as a knowledge graph affords story coherence and provides controllability in the form of achieving a given story world state goal. Experiments show that our model produces significantly more coherent and on-topic stories, outperforming baselines in dimensions including plot plausibility and staying on topic. Our system also outperforms outline-guided story generation baselines in composing given concepts without ordering.
Rethinking Action Spaces for Reinforcement Learning in End-to-end Dialog Agents with Latent Variable Models
Apr 15, 2019
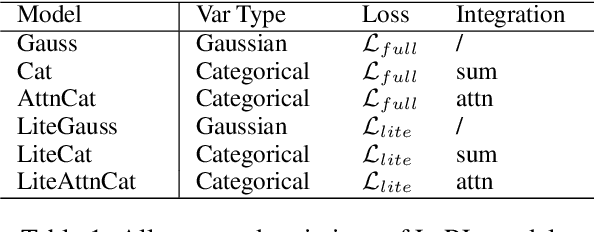
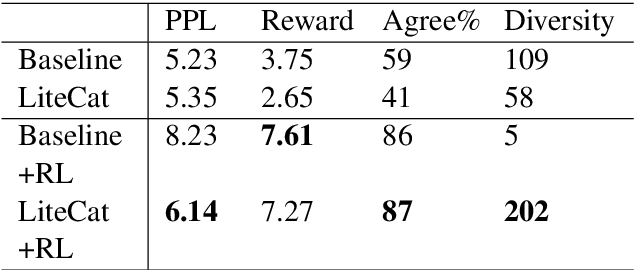
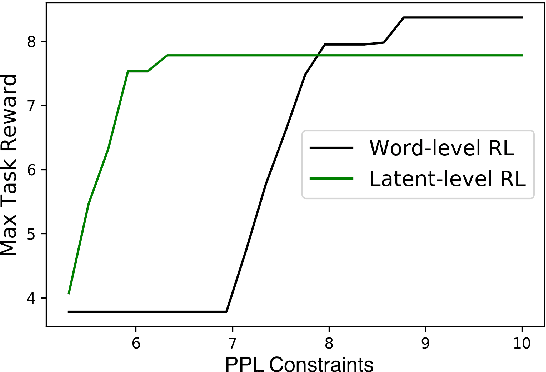
Defining action spaces for conversational agents and optimizing their decision-making process with reinforcement learning is an enduring challenge. Common practice has been to use handcrafted dialog acts, or the output vocabulary, e.g. in neural encoder decoders, as the action spaces. Both have their own limitations. This paper proposes a novel latent action framework that treats the action spaces of an end-to-end dialog agent as latent variables and develops unsupervised methods in order to induce its own action space from the data. Comprehensive experiments are conducted examining both continuous and discrete action types and two different optimization methods based on stochastic variational inference. Results show that the proposed latent actions achieve superior empirical performance improvement over previous word-level policy gradient methods on both DealOrNoDeal and MultiWoz dialogs. Our detailed analysis also provides insights about various latent variable approaches for policy learning and can serve as a foundation for developing better latent actions in future research.
Towards Universal Dialogue State Tracking
Oct 22, 2018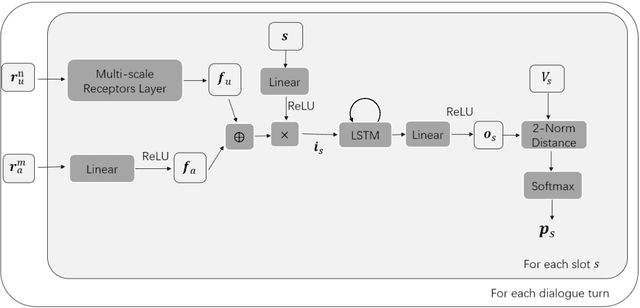
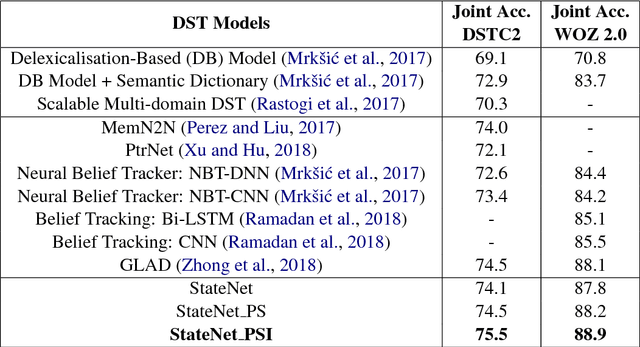
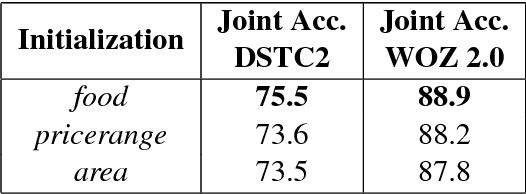
Dialogue state tracking is the core part of a spoken dialogue system. It estimates the beliefs of possible user's goals at every dialogue turn. However, for most current approaches, it's difficult to scale to large dialogue domains. They have one or more of following limitations: (a) Some models don't work in the situation where slot values in ontology changes dynamically; (b) The number of model parameters is proportional to the number of slots; (c) Some models extract features based on hand-crafted lexicons. To tackle these challenges, we propose StateNet, a universal dialogue state tracker. It is independent of the number of values, shares parameters across all slots, and uses pre-trained word vectors instead of explicit semantic dictionaries. Our experiments on two datasets show that our approach not only overcomes the limitations, but also significantly outperforms the performance of state-of-the-art approaches.