 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVideo-Ego4D: A Pack of Champion Solutions to Ego4D Challenges
Nov 17, 2022In this report, we present our champion solutions to five tracks at Ego4D challenge. We leverage our developed InternVideo, a video foundation model, for five Ego4D tasks, including Moment Queries, Natural Language Queries, Future Hand Prediction, State Change Object Detection, and Short-term Object Interaction Anticipation. InternVideo-Ego4D is an effective paradigm to adapt the strong foundation model to the downstream ego-centric video understanding tasks with simple head designs. In these five tasks, the performance of InternVideo-Ego4D comprehensively surpasses the baseline methods and the champions of CVPR2022, demonstrating the powerful representation ability of InternVideo as a video foundation model. Our code will be released at https://github.com/OpenGVLab/ego4d-eccv2022-solutions
Exploring State Change Capture of Heterogeneous Backbones @ Ego4D Hands and Objects Challenge 2022
Nov 16, 2022Capturing the state changes of interacting objects is a key technology for understanding human-object interactions. This technical report describes our method using heterogeneous backbones for the Ego4D Object State Change Classification and PNR Temporal Localization Challenge. In the challenge, we used the heterogeneous video understanding backbones, namely CSN with 3D convolution as operator and VideoMAE with Transformer as operator. Our method achieves an accuracy of 0.796 on OSCC while achieving an absolute temporal localization error of 0.516 on PNR. These excellent results rank 1st on the leaderboard of Ego4D OSCC & PNR-TL Challenge 2022.
Exploring Detection-based Method For Speaker Diarization @ Ego4D Audio-only Diarization Challenge 2022
Nov 16, 2022We provide the technical report for Ego4D audio-only diarization challenge in ECCV 2022. Speaker diarization takes the audio streams as input and outputs the homogeneous segments according to the speaker's identity. It aims to solve the problem of "Who spoke when." In this paper, we explore a Detection-based method to tackle the audio-only speaker diarization task. Our method first extracts audio features by audio backbone and then feeds the feature to a detection-generate network to get the speaker proposals. Finally, after postprocessing, we can get the diarization results. The validation dataset validates this method, and our method achieves 53.85 DER on the test dataset. These results rank 3rd on the leaderboard of Ego4D audio-only diarization challenge 2022.
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Nov 13, 2022Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs. The code will be released at https://github.com/OpenGVLab/InternImage.
A Survey of Deep Face Restoration: Denoise, Super-Resolution, Deblur, Artifact Removal
Nov 05, 2022



Face Restoration (FR) aims to restore High-Quality (HQ) faces from Low-Quality (LQ) input images, which is a domain-specific image restoration problem in the low-level computer vision area. The early face restoration methods mainly use statistic priors and degradation models, which are difficult to meet the requirements of real-world applications in practice. In recent years, face restoration has witnessed great progress after stepping into the deep learning era. However, there are few works to study deep learning-based face restoration methods systematically. Thus, this paper comprehensively surveys recent advances in deep learning techniques for face restoration. Specifically, we first summarize different problem formulations and analyze the characteristic of the face image. Second, we discuss the challenges of face restoration. Concerning these challenges, we present a comprehensive review of existing FR methods, including prior based methods and deep learning-based methods. Then, we explore developed techniques in the task of FR covering network architectures, loss functions, and benchmark datasets. We also conduct a systematic benchmark evaluation on representative methods. Finally, we discuss future directions, including network designs, metrics, benchmark datasets, applications,etc. We also provide an open-source repository for all the discussed methods, which is available at https://github.com/TaoWangzj/Awesome-Face-Restoration.
On Efficient Reinforcement Learning for Full-length Game of StarCraft II
Sep 23, 2022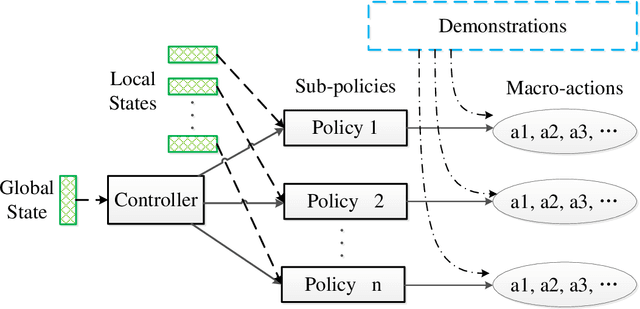

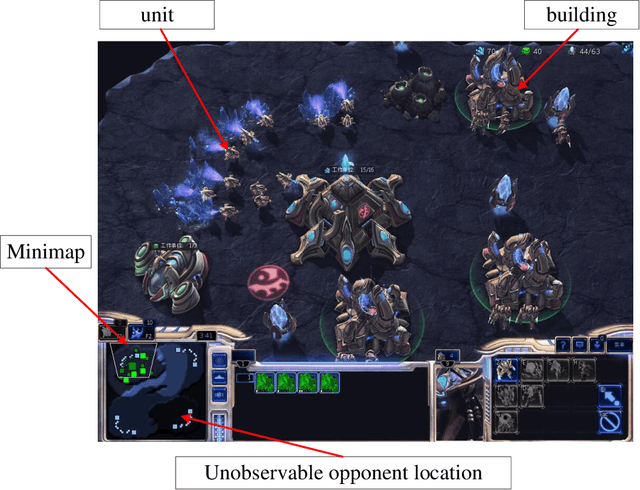

StarCraft II (SC2) poses a grand challenge for reinforcement learning (RL), of which the main difficulties include huge state space, varying action space, and a long time horizon. In this work, we investigate a set of RL techniques for the full-length game of StarCraft II. We investigate a hierarchical RL approach involving extracted macro-actions and a hierarchical architecture of neural networks. We investigate a curriculum transfer training procedure and train the agent on a single machine with 4 GPUs and 48 CPU threads. On a 64x64 map and using restrictive units, we achieve a win rate of 99% against the level-1 built-in AI. Through the curriculum transfer learning algorithm and a mixture of combat models, we achieve a 93% win rate against the most difficult non-cheating level built-in AI (level-7). In this extended version of the paper, we improve our architecture to train the agent against the cheating level AIs and achieve the win rate against the level-8, level-9, and level-10 AIs as 96%, 97%, and 94%, respectively. Our codes are at https://github.com/liuruoze/HierNet-SC2. To provide a baseline referring the AlphaStar for our work as well as the research and open-source community, we reproduce a scaled-down version of it, mini-AlphaStar (mAS). The latest version of mAS is 1.07, which can be trained on the raw action space which has 564 actions. It is designed to run training on a single common machine, by making the hyper-parameters adjustable. We then compare our work with mAS using the same resources and show that our method is more effective. The codes of mini-AlphaStar are at https://github.com/liuruoze/mini-AlphaStar. We hope our study could shed some light on the future research of efficient reinforcement learning on SC2 and other large-scale games.
Incremental Few-Shot Semantic Segmentation via Embedding Adaptive-Update and Hyper-class Representation
Jul 26, 2022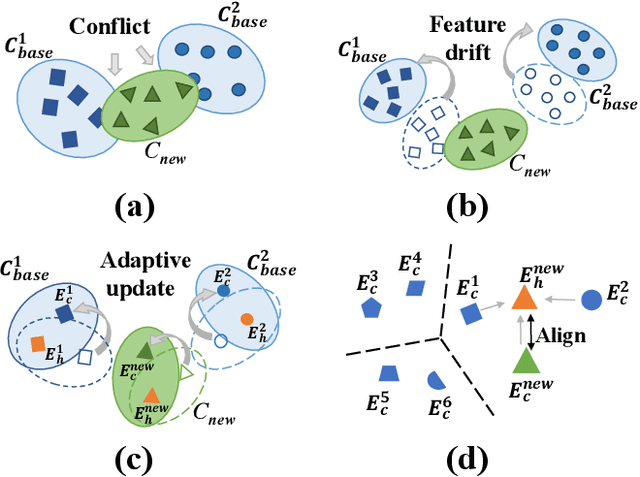
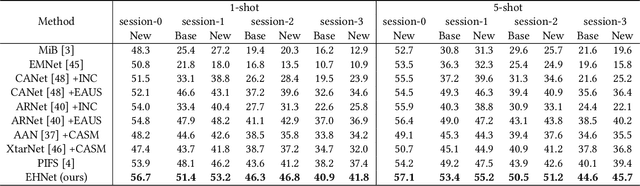
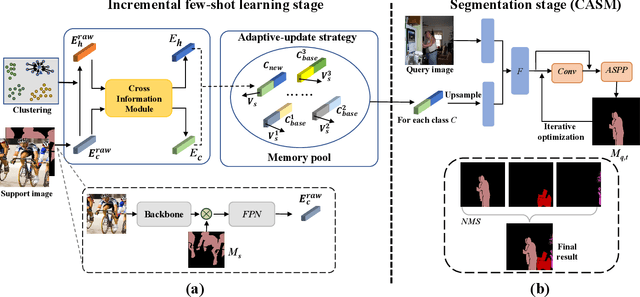
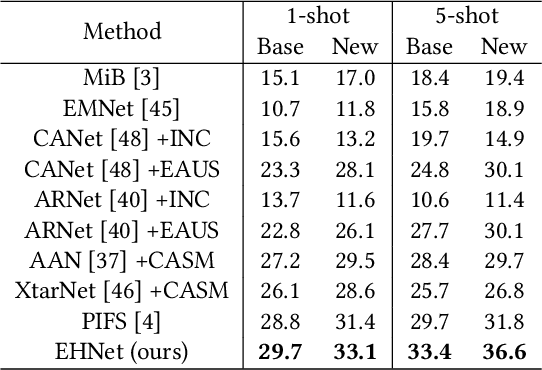
Incremental few-shot semantic segmentation (IFSS) targets at incrementally expanding model's capacity to segment new class of images supervised by only a few samples. However, features learned on old classes could significantly drift, causing catastrophic forgetting. Moreover, few samples for pixel-level segmentation on new classes lead to notorious overfitting issues in each learning session. In this paper, we explicitly represent class-based knowledge for semantic segmentation as a category embedding and a hyper-class embedding, where the former describes exclusive semantical properties, and the latter expresses hyper-class knowledge as class-shared semantic properties. Aiming to solve IFSS problems, we present EHNet, i.e., Embedding adaptive-update and Hyper-class representation Network from two aspects. First, we propose an embedding adaptive-update strategy to avoid feature drift, which maintains old knowledge by hyper-class representation, and adaptively update category embeddings with a class-attention scheme to involve new classes learned in individual sessions. Second, to resist overfitting issues caused by few training samples, a hyper-class embedding is learned by clustering all category embeddings for initialization and aligned with category embedding of the new class for enhancement, where learned knowledge assists to learn new knowledge, thus alleviating performance dependence on training data scale. Significantly, these two designs provide representation capability for classes with sufficient semantics and limited biases, enabling to perform segmentation tasks requiring high semantic dependence. Experiments on PASCAL-5i and COCO datasets show that EHNet achieves new state-of-the-art performance with remarkable advantages.
SeedFormer: Patch Seeds based Point Cloud Completion with Upsample Transformer
Jul 21, 2022
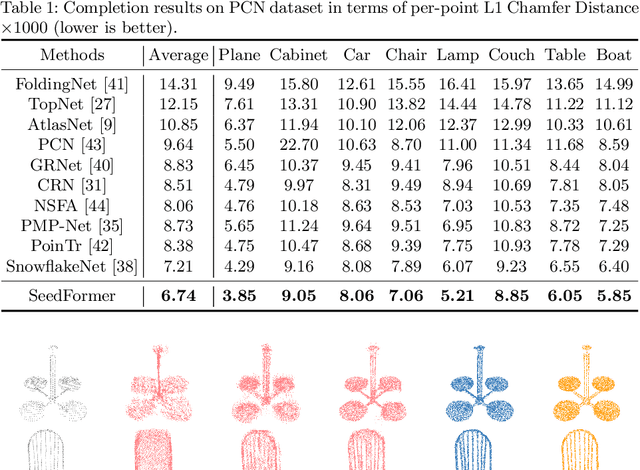
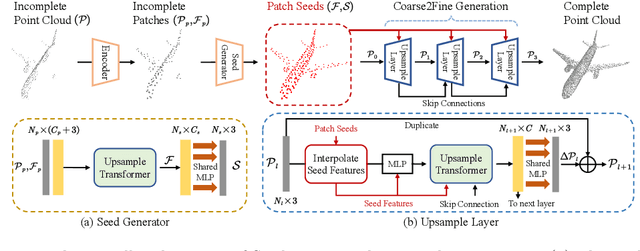
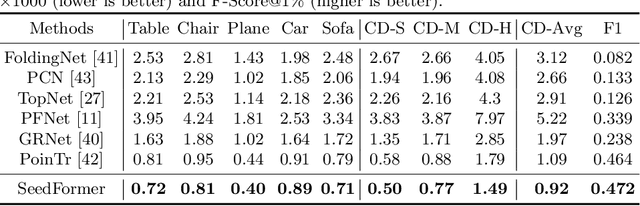
Point cloud completion has become increasingly popular among generation tasks of 3D point clouds, as it is a challenging yet indispensable problem to recover the complete shape of a 3D object from its partial observation. In this paper, we propose a novel SeedFormer to improve the ability of detail preservation and recovery in point cloud completion. Unlike previous methods based on a global feature vector, we introduce a new shape representation, namely Patch Seeds, which not only captures general structures from partial inputs but also preserves regional information of local patterns. Then, by integrating seed features into the generation process, we can recover faithful details for complete point clouds in a coarse-to-fine manner. Moreover, we devise an Upsample Transformer by extending the transformer structure into basic operations of point generators, which effectively incorporates spatial and semantic relationships between neighboring points. Qualitative and quantitative evaluations demonstrate that our method outperforms state-of-the-art completion networks on several benchmark datasets. Our code is available at https://github.com/hrzhou2/seedformer.
Vision Transformer Adapter for Dense Predictions
May 18, 2022
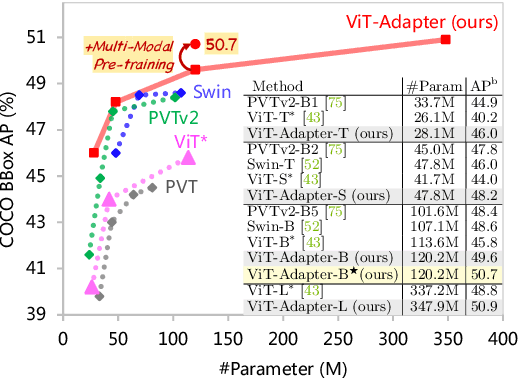
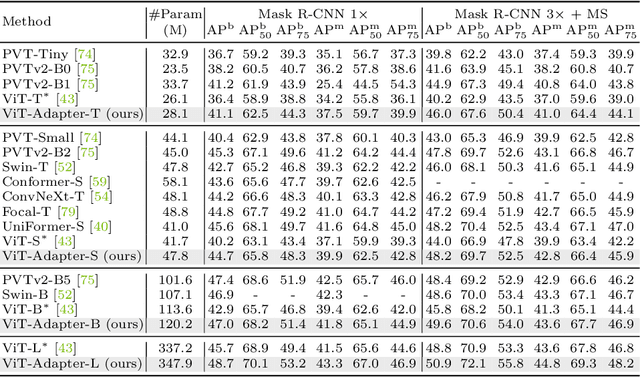
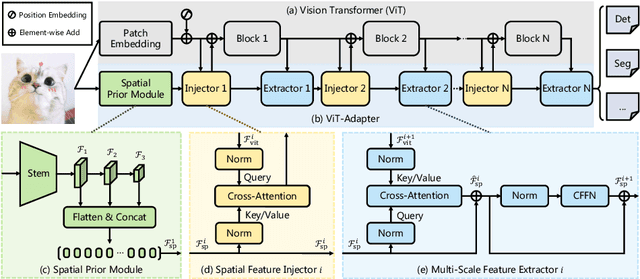
This work investigates a simple yet powerful adapter for Vision Transformer (ViT). Unlike recent visual transformers that introduce vision-specific inductive biases into their architectures, ViT achieves inferior performance on dense prediction tasks due to lacking prior information of images. To solve this issue, we propose a Vision Transformer Adapter (ViT-Adapter), which can remedy the defects of ViT and achieve comparable performance to vision-specific models by introducing inductive biases via an additional architecture. Specifically, the backbone in our framework is a vanilla transformer that can be pre-trained with multi-modal data. When fine-tuning on downstream tasks, a modality-specific adapter is used to introduce the data and tasks' prior information into the model, making it suitable for these tasks. We verify the effectiveness of our ViT-Adapter on multiple downstream tasks, including object detection, instance segmentation, and semantic segmentation. Notably, when using HTC++, our ViT-Adapter-L yields 60.1 box AP and 52.1 mask AP on COCO test-dev, surpassing Swin-L by 1.4 box AP and 1.0 mask AP. For semantic segmentation, our ViT-Adapter-L establishes a new state-of-the-art of 60.5 mIoU on ADE20K val, 0.6 points higher than SwinV2-G. We hope that the proposed ViT-Adapter could serve as an alternative for vision-specific transformers and facilitate future research. The code and models will be released at https://github.com/czczup/ViT-Adapter.
Uncertainty-based Network for Few-shot Image Classification
May 17, 2022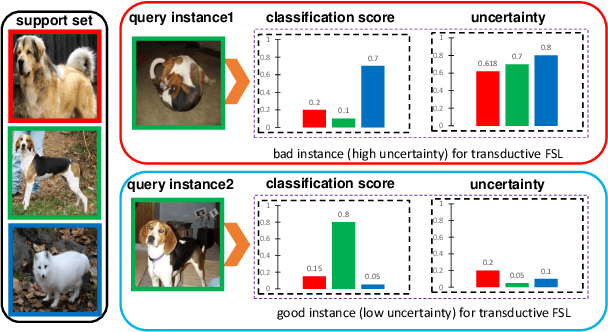
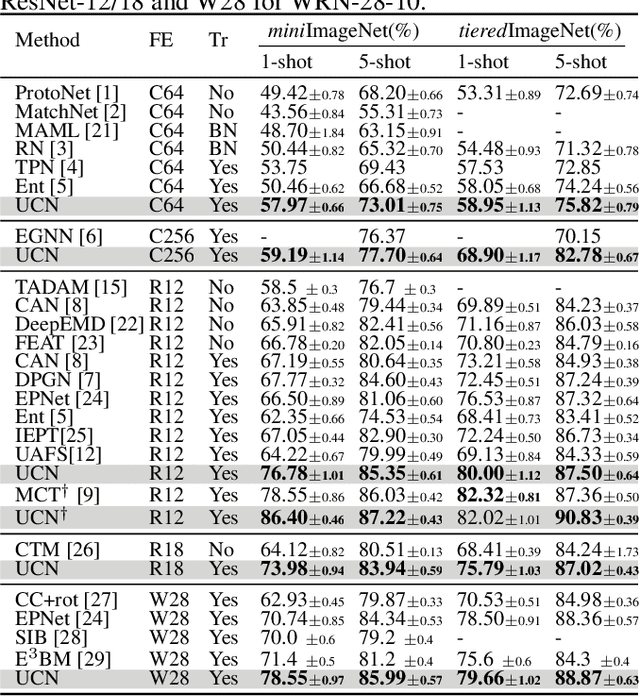
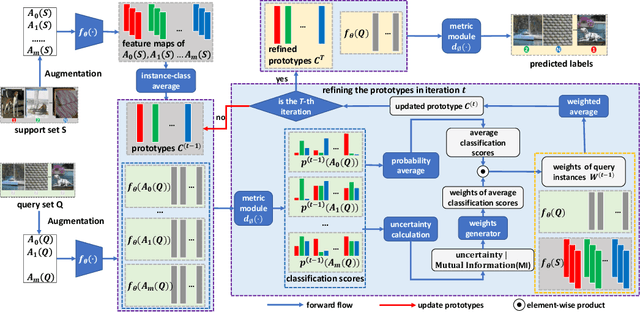
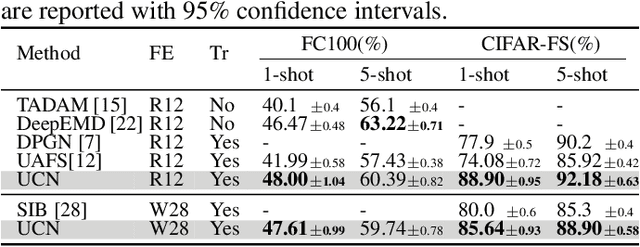
The transductive inference is an effective technique in the few-shot learning task, where query sets update prototypes to improve themselves. However, these methods optimize the model by considering only the classification scores of the query instances as confidence while ignoring the uncertainty of these classification scores. In this paper, we propose a novel method called Uncertainty-Based Network, which models the uncertainty of classification results with the help of mutual information. Specifically, we first data augment and classify the query instance and calculate the mutual information of these classification scores. Then, mutual information is used as uncertainty to assign weights to classification scores, and the iterative update strategy based on classification scores and uncertainties assigns the optimal weights to query instances in prototype optimization. Extensive results on four benchmarks show that Uncertainty-Based Network achieves comparable performance in classification accuracy compared to state-of-the-art method.