 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory
May 16, 2025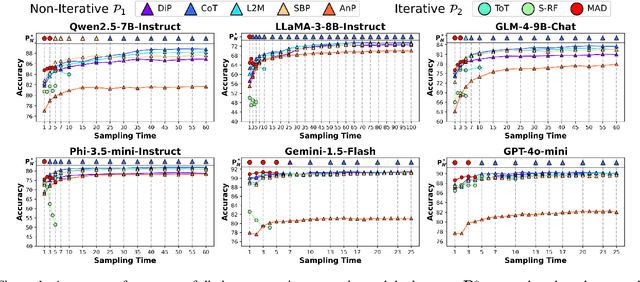


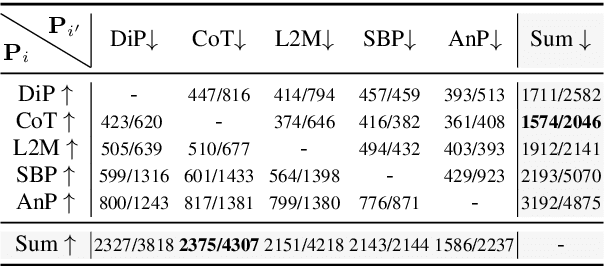
Recently, scaling test-time compute on Large Language Models (LLM) has garnered wide attention. However, there has been limited investigation of how various reasoning prompting strategies perform as scaling. In this paper, we focus on a standard and realistic scaling setting: majority voting. We systematically conduct experiments on 6 LLMs $\times$ 8 prompting strategies $\times$ 6 benchmarks. Experiment results consistently show that as the sampling time and computational overhead increase, complicated prompting strategies with superior initial performance gradually fall behind simple Chain-of-Thought. We analyze this phenomenon and provide theoretical proofs. Additionally, we propose a method according to probability theory to quickly and accurately predict the scaling performance and select the best strategy under large sampling times without extra resource-intensive inference in practice. It can serve as the test-time scaling law for majority voting. Furthermore, we introduce two ways derived from our theoretical analysis to significantly improve the scaling performance. We hope that our research can promote to re-examine the role of complicated prompting, unleash the potential of simple prompting strategies, and provide new insights for enhancing test-time scaling performance.
A Call for New Recipes to Enhance Spatial Reasoning in MLLMs
Apr 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in general vision-language tasks. However, recent studies have exposed critical limitations in their spatial reasoning capabilities. This deficiency in spatial reasoning significantly constrains MLLMs' ability to interact effectively with the physical world, thereby limiting their broader applications. We argue that spatial reasoning capabilities will not naturally emerge from merely scaling existing architectures and training methodologies. Instead, this challenge demands dedicated attention to fundamental modifications in the current MLLM development approach. In this position paper, we first establish a comprehensive framework for spatial reasoning within the context of MLLMs. We then elaborate on its pivotal role in real-world applications. Through systematic analysis, we examine how individual components of the current methodology-from training data to reasoning mechanisms-influence spatial reasoning capabilities. This examination reveals critical limitations while simultaneously identifying promising avenues for advancement. Our work aims to direct the AI research community's attention toward these crucial yet underexplored aspects. By highlighting these challenges and opportunities, we seek to catalyze progress toward achieving human-like spatial reasoning capabilities in MLLMs.
MME-Unify: A Comprehensive Benchmark for Unified Multimodal Understanding and Generation Models
Apr 07, 2025Existing MLLM benchmarks face significant challenges in evaluating Unified MLLMs (U-MLLMs) due to: 1) lack of standardized benchmarks for traditional tasks, leading to inconsistent comparisons; 2) absence of benchmarks for mixed-modality generation, which fails to assess multimodal reasoning capabilities. We present a comprehensive evaluation framework designed to systematically assess U-MLLMs. Our benchmark includes: Standardized Traditional Task Evaluation. We sample from 12 datasets, covering 10 tasks with 30 subtasks, ensuring consistent and fair comparisons across studies." 2. Unified Task Assessment. We introduce five novel tasks testing multimodal reasoning, including image editing, commonsense QA with image generation, and geometric reasoning. 3. Comprehensive Model Benchmarking. We evaluate 12 leading U-MLLMs, such as Janus-Pro, EMU3, VILA-U, and Gemini2-flash, alongside specialized understanding (e.g., Claude-3.5-Sonnet) and generation models (e.g., DALL-E-3). Our findings reveal substantial performance gaps in existing U-MLLMs, highlighting the need for more robust models capable of handling mixed-modality tasks effectively. The code and evaluation data can be found in https://mme-unify.github.io/.
Aligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025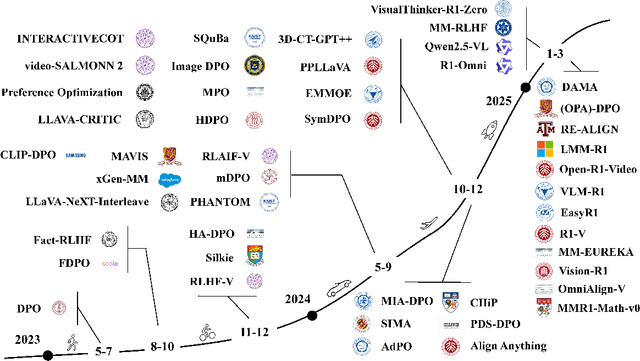
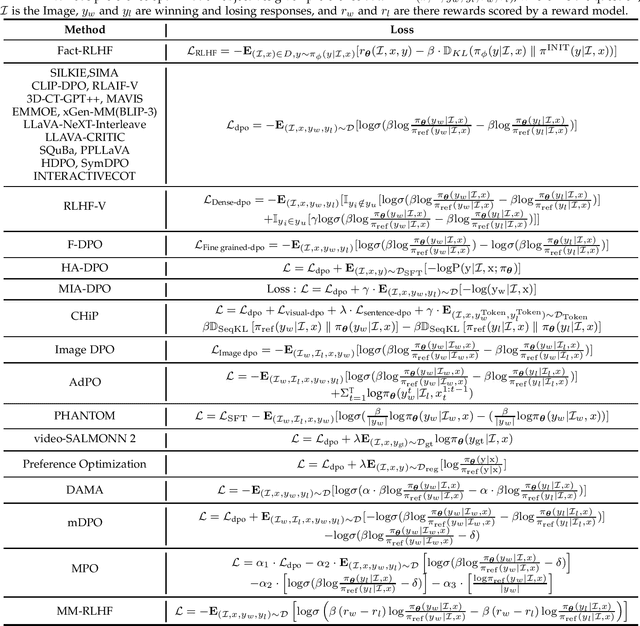
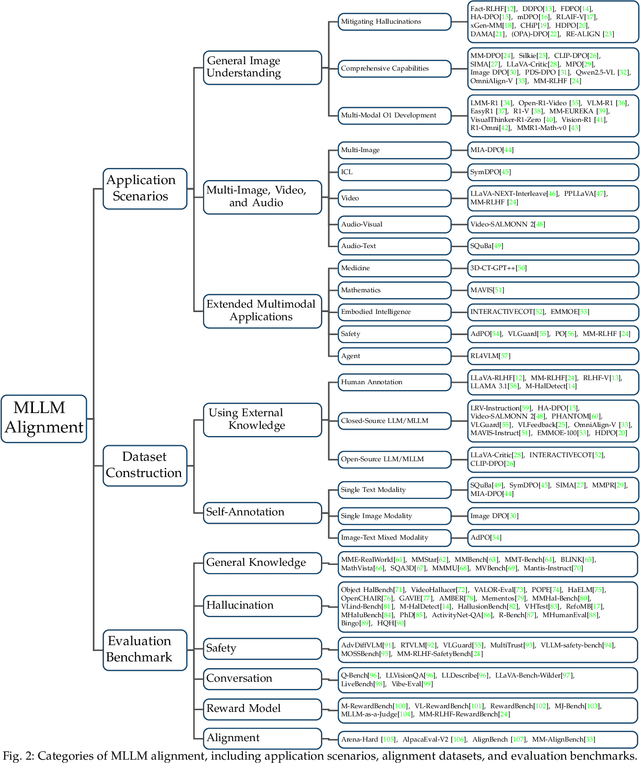

Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
VidCapBench: A Comprehensive Benchmark of Video Captioning for Controllable Text-to-Video Generation
Feb 18, 2025The training of controllable text-to-video (T2V) models relies heavily on the alignment between videos and captions, yet little existing research connects video caption evaluation with T2V generation assessment. This paper introduces VidCapBench, a video caption evaluation scheme specifically designed for T2V generation, agnostic to any particular caption format. VidCapBench employs a data annotation pipeline, combining expert model labeling and human refinement, to associate each collected video with key information spanning video aesthetics, content, motion, and physical laws. VidCapBench then partitions these key information attributes into automatically assessable and manually assessable subsets, catering to both the rapid evaluation needs of agile development and the accuracy requirements of thorough validation. By evaluating numerous state-of-the-art captioning models, we demonstrate the superior stability and comprehensiveness of VidCapBench compared to existing video captioning evaluation approaches. Verification with off-the-shelf T2V models reveals a significant positive correlation between scores on VidCapBench and the T2V quality evaluation metrics, indicating that VidCapBench can provide valuable guidance for training T2V models. The project is available at https://github.com/VidCapBench/VidCapBench.
TimeRAF: Retrieval-Augmented Foundation model for Zero-shot Time Series Forecasting
Dec 30, 2024



Time series forecasting plays a crucial role in data mining, driving rapid advancements across numerous industries. With the emergence of large models, time series foundation models (TSFMs) have exhibited remarkable generalization capabilities, such as zero-shot learning, through large-scale pre-training. Meanwhile, Retrieval-Augmented Generation (RAG) methods have been widely employed to enhance the performance of foundation models on unseen data, allowing models to access to external knowledge. In this paper, we introduce TimeRAF, a Retrieval-Augmented Forecasting model that enhance zero-shot time series forecasting through retrieval-augmented techniques. We develop customized time series knowledge bases that are tailored to the specific forecasting tasks. TimeRAF employs an end-to-end learnable retriever to extract valuable information from the knowledge base. Additionally, we propose Channel Prompting for knowledge integration, which effectively extracts relevant information from the retrieved knowledge along the channel dimension. Extensive experiments demonstrate the effectiveness of our model, showing significant improvement across various domains and datasets.
Towards Compatible Fine-tuning for Vision-Language Model Updates
Dec 30, 2024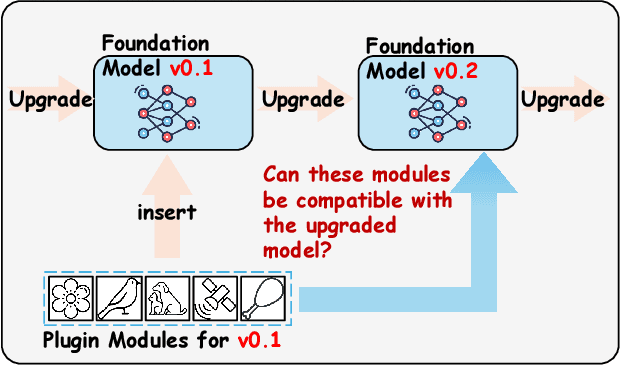
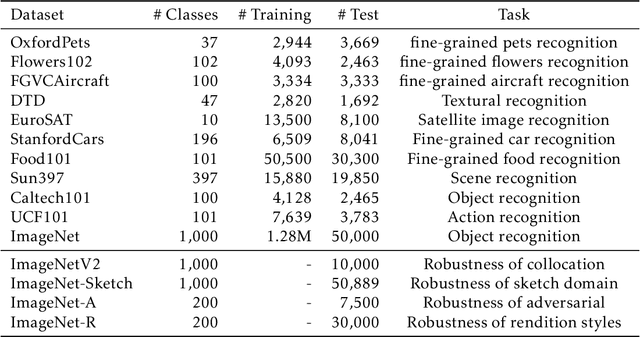
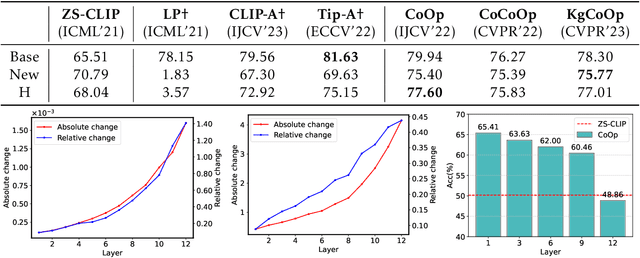
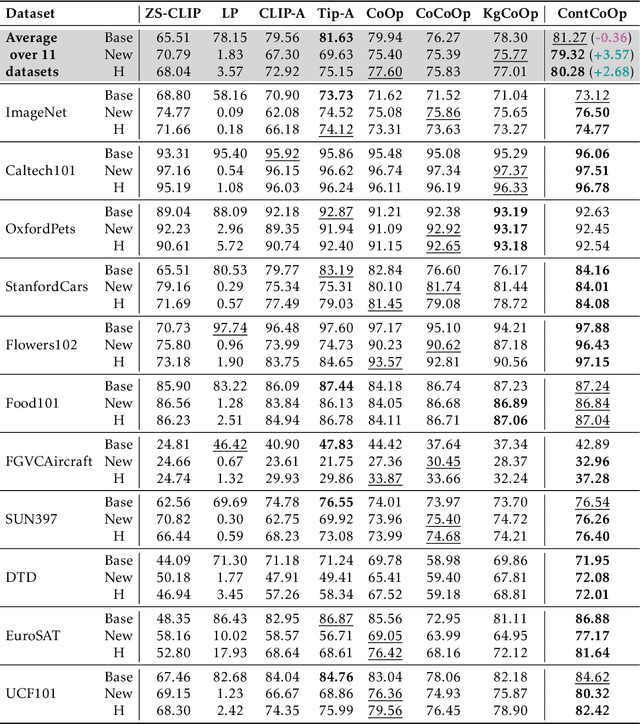
So far, efficient fine-tuning has become a popular strategy for enhancing the capabilities of foundation models on downstream tasks by learning plug-and-play modules. However, existing methods overlook a crucial issue: if the underlying foundation model is updated, are these plug-and-play modules still effective? In this paper, we first conduct a detailed analysis of various fine-tuning methods on the CLIP in terms of their compatibility with model updates. The study reveals that many high-performing fine-tuning methods fail to be compatible with the upgraded models. To address this, we propose a novel approach, Class-conditioned Context Optimization (ContCoOp), which integrates learnable prompts with class embeddings using an attention layer before inputting them into the text encoder. Consequently, the prompts can dynamically adapt to the changes in embedding space (due to model updates), ensuring continued effectiveness. Extensive experiments over 15 datasets show that our ContCoOp achieves the highest compatibility over the baseline methods, and exhibits robust out-of-distribution generalization.
Dark Miner: Defend against unsafe generation for text-to-image diffusion models
Sep 26, 2024Text-to-image diffusion models have been demonstrated with unsafe generation due to unfiltered large-scale training data, such as violent, sexual, and shocking images, necessitating the erasure of unsafe concepts. Most existing methods focus on modifying the generation probabilities conditioned on the texts containing unsafe descriptions. However, they fail to guarantee safe generation for unseen texts in the training phase, especially for the prompts from adversarial attacks. In this paper, we re-analyze the erasure task and point out that existing methods cannot guarantee the minimization of the total probabilities of unsafe generation. To tackle this problem, we propose Dark Miner. It entails a recurring three-stage process that comprises mining, verifying, and circumventing. It greedily mines embeddings with maximum generation probabilities of unsafe concepts and reduces unsafe generation more effectively. In the experiments, we evaluate its performance on two inappropriate concepts, two objects, and two styles. Compared with 6 previous state-of-the-art methods, our method achieves better erasure and defense results in most cases, especially under 4 state-of-the-art attacks, while preserving the model's native generation capability. Our code will be available on GitHub.
MME-RealWorld: Could Your Multimodal LLM Challenge High-Resolution Real-World Scenarios that are Difficult for Humans?
Aug 23, 2024



Comprehensive evaluation of Multimodal Large Language Models (MLLMs) has recently garnered widespread attention in the research community. However, we observe that existing benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including: 1) small data scale leads to a large performance variance; 2) reliance on model-based annotations results in restricted data quality; 3) insufficient task difficulty, especially caused by the limited image resolution. To tackle these issues, we introduce MME-RealWorld. Specifically, we collect more than $300$K images from public datasets and the Internet, filtering $13,366$ high-quality images for annotation. This involves the efforts of professional $25$ annotators and $7$ experts in MLLMs, contributing to $29,429$ question-answer pairs that cover $43$ subtasks across $5$ real-world scenarios, extremely challenging even for humans. As far as we know, MME-RealWorld is the largest manually annotated benchmark to date, featuring the highest resolution and a targeted focus on real-world applications. We further conduct a thorough evaluation involving $28$ prominent MLLMs, such as GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet. Our results show that even the most advanced models struggle with our benchmarks, where none of them reach $60\%$ accuracy. The challenges of perceiving high-resolution images and understanding complex real-world scenarios remain urgent issues to be addressed. The data and evaluation code are released at https://mme-realworld.github.io/ .
Artificial Immune System of Secure Face Recognition Against Adversarial Attacks
Jun 26, 2024Insect production for food and feed presents a promising supplement to ensure food safety and address the adverse impacts of agriculture on climate and environment in the future. However, optimisation is required for insect production to realise its full potential. This can be by targeted improvement of traits of interest through selective breeding, an approach which has so far been underexplored and underutilised in insect farming. Here we present a comprehensive review of the selective breeding framework in the context of insect production. We systematically evaluate adjustments of selective breeding techniques to the realm of insects and highlight the essential components integral to the breeding process. The discussion covers every step of a conventional breeding scheme, such as formulation of breeding objectives, phenotyping, estimation of genetic parameters and breeding values, selection of appropriate breeding strategies, and mitigation of issues associated with genetic diversity depletion and inbreeding. This review combines knowledge from diverse disciplines, bridging the gap between animal breeding, quantitative genetics, evolutionary biology, and entomology, offering an integrated view of the insect breeding research area and uniting knowledge which has previously remained scattered across diverse fields of expertise.