 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolitical-LLM: Large Language Models in Political Science
Dec 09, 2024



In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science. Our online resource is available at: http://political-llm.org/.
Integrating Social Determinants of Health into Knowledge Graphs: Evaluating Prediction Bias and Fairness in Healthcare
Nov 29, 2024



Social determinants of health (SDoH) play a crucial role in patient health outcomes, yet their integration into biomedical knowledge graphs remains underexplored. This study addresses this gap by constructing an SDoH-enriched knowledge graph using the MIMIC-III dataset and PrimeKG. We introduce a novel fairness formulation for graph embeddings, focusing on invariance with respect to sensitive SDoH information. Via employing a heterogeneous-GCN model for drug-disease link prediction, we detect biases related to various SDoH factors. To mitigate these biases, we propose a post-processing method that strategically reweights edges connected to SDoHs, balancing their influence on graph representations. This approach represents one of the first comprehensive investigations into fairness issues within biomedical knowledge graphs incorporating SDoH. Our work not only highlights the importance of considering SDoH in medical informatics but also provides a concrete method for reducing SDoH-related biases in link prediction tasks, paving the way for more equitable healthcare recommendations. Our code is available at \url{https://github.com/hwq0726/SDoH-KG}.
Accelerating Vision Diffusion Transformers with Skip Branches
Nov 26, 2024



Diffusion Transformers (DiT), an emerging image and video generation model architecture, has demonstrated great potential because of its high generation quality and scalability properties. Despite the impressive performance, its practical deployment is constrained by computational complexity and redundancy in the sequential denoising process. While feature caching across timesteps has proven effective in accelerating diffusion models, its application to DiT is limited by fundamental architectural differences from U-Net-based approaches. Through empirical analysis of DiT feature dynamics, we identify that significant feature variation between DiT blocks presents a key challenge for feature reusability. To address this, we convert standard DiT into Skip-DiT with skip branches to enhance feature smoothness. Further, we introduce Skip-Cache which utilizes the skip branches to cache DiT features across timesteps at the inference time. We validated effectiveness of our proposal on different DiT backbones for video and image generation, showcasing skip branches to help preserve generation quality and achieve higher speedup. Experimental results indicate that Skip-DiT achieves a 1.5x speedup almost for free and a 2.2x speedup with only a minor reduction in quantitative metrics. Code is available at https://github.com/OpenSparseLLMs/Skip-DiT.git.
Path-RAG: Knowledge-Guided Key Region Retrieval for Open-ended Pathology Visual Question Answering
Nov 26, 2024



Accurate diagnosis and prognosis assisted by pathology images are essential for cancer treatment selection and planning. Despite the recent trend of adopting deep-learning approaches for analyzing complex pathology images, they fall short as they often overlook the domain-expert understanding of tissue structure and cell composition. In this work, we focus on a challenging Open-ended Pathology VQA (PathVQA-Open) task and propose a novel framework named Path-RAG, which leverages HistoCartography to retrieve relevant domain knowledge from pathology images and significantly improves performance on PathVQA-Open. Admitting the complexity of pathology image analysis, Path-RAG adopts a human-centered AI approach by retrieving domain knowledge using HistoCartography to select the relevant patches from pathology images. Our experiments suggest that domain guidance can significantly boost the accuracy of LLaVA-Med from 38% to 47%, with a notable gain of 28% for H&E-stained pathology images in the PathVQA-Open dataset. For longer-form question and answer pairs, our model consistently achieves significant improvements of 32.5% in ARCH-Open PubMed and 30.6% in ARCH-Open Books on H\&E images. Our code and dataset is available here (https://github.com/embedded-robotics/path-rag).
BPO: Towards Balanced Preference Optimization between Knowledge Breadth and Depth in Alignment
Nov 16, 2024



Reinforcement Learning with Human Feedback (RLHF) is the key to the success of large language models (LLMs) in recent years. In this work, we first introduce the concepts of knowledge breadth and knowledge depth, which measure the comprehensiveness and depth of an LLM or knowledge source respectively. We reveal that the imbalance in the number of prompts and responses can lead to a potential disparity in breadth and depth learning within alignment tuning datasets by showing that even a simple uniform method for balancing the number of instructions and responses can lead to significant improvements. Building on this, we further propose Balanced Preference Optimization (BPO), designed to dynamically augment the knowledge depth of each sample. BPO is motivated by the observation that the usefulness of knowledge varies across samples, necessitating tailored learning of knowledge depth. To achieve this, we introduce gradient-based clustering, estimating the knowledge informativeness and usefulness of each augmented sample based on the model's optimization direction. Our experimental results across various benchmarks demonstrate that BPO outperforms other baseline methods in alignment tuning while maintaining training efficiency. Furthermore, we conduct a detailed analysis of each component of BPO, providing guidelines for future research in preference data optimization.
FM-TS: Flow Matching for Time Series Generation
Nov 12, 2024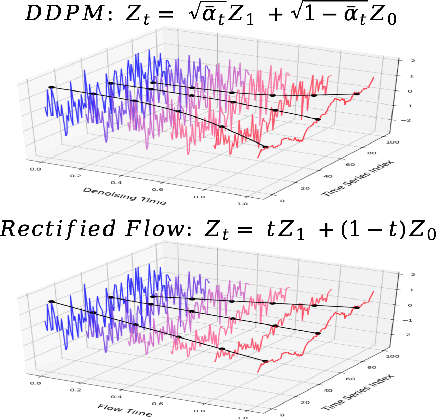
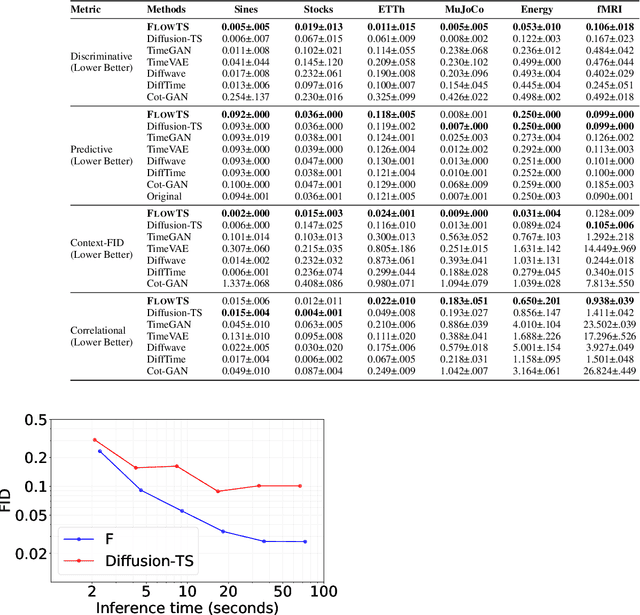
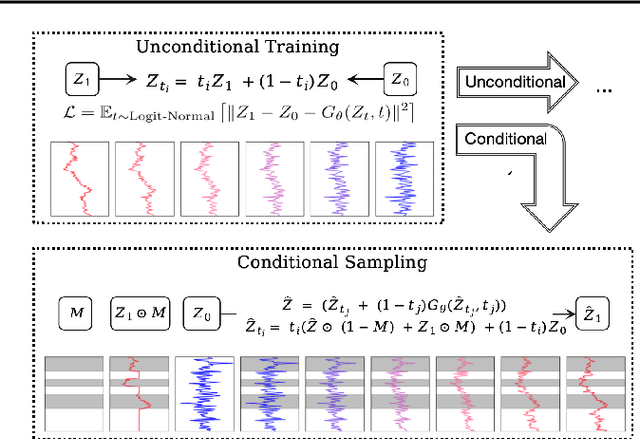
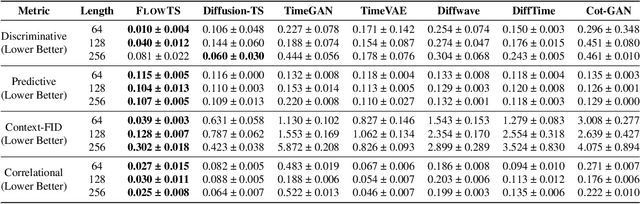
Time series generation has emerged as an essential tool for analyzing temporal data across numerous fields. While diffusion models have recently gained significant attention in generating high-quality time series, they tend to be computationally demanding and reliant on complex stochastic processes. To address these limitations, we introduce FM-TS, a rectified Flow Matching-based framework for Time Series generation, which simplifies the time series generation process by directly optimizing continuous trajectories. This approach avoids the need for iterative sampling or complex noise schedules typically required in diffusion-based models. FM-TS is more efficient in terms of training and inference. Moreover, FM-TS is highly adaptive, supporting both conditional and unconditional time series generation. Notably, through our novel inference design, the model trained in an unconditional setting can seamlessly generalize to conditional tasks without the need for retraining. Extensive benchmarking across both settings demonstrates that FM-TS consistently delivers superior performance compared to existing approaches while being more efficient in terms of training and inference. For instance, in terms of discriminative score, FM-TS achieves 0.005, 0.019, 0.011, 0.005, 0.053, and 0.106 on the Sines, Stocks, ETTh, MuJoCo, Energy, and fMRI unconditional time series datasets, respectively, significantly outperforming the second-best method which achieves 0.006, 0.067, 0.061, 0.008, 0.122, and 0.167 on the same datasets. We have achieved superior performance in solar forecasting and MuJoCo imputation tasks, significantly enhanced by our innovative $t$ power sampling method. The code is available at https://github.com/UNITES-Lab/FMTS.
FairSkin: Fair Diffusion for Skin Disease Image Generation
Oct 31, 2024



Image generation is a prevailing technique for clinical data augmentation for advancing diagnostic accuracy and reducing healthcare disparities. Diffusion Model (DM) has become a leading method in generating synthetic medical images, but it suffers from a critical twofold bias: (1) The quality of images generated for Caucasian individuals is significantly higher, as measured by the Frechet Inception Distance (FID). (2) The ability of the downstream-task learner to learn critical features from disease images varies across different skin tones. These biases pose significant risks, particularly in skin disease detection, where underrepresentation of certain skin tones can lead to misdiagnosis or neglect of specific conditions. To address these challenges, we propose FairSkin, a novel DM framework that mitigates these biases through a three-level resampling mechanism, ensuring fairer representation across racial and disease categories. Our approach significantly improves the diversity and quality of generated images, contributing to more equitable skin disease detection in clinical settings.
Harnessing Your DRAM and SSD for Sustainable and Accessible LLM Inference with Mixed-Precision and Multi-level Caching
Oct 23, 2024



Although Large Language Models (LLMs) have demonstrated remarkable capabilities, their massive parameter counts and associated extensive computing make LLMs' deployment the main part of carbon emission from nowadays AI applications. Compared to modern GPUs like H$100$, it would be significantly carbon-sustainable if we could leverage old-fashioned GPUs such as M$40$ (as shown in Figure 1, M$40$ only has one third carbon emission of H$100$'s) for LLM servings. However, the limited High Bandwidth Memory (HBM) available on such GPU often cannot support the loading of LLMs due to the gigantic model size and intermediate activation data, making their serving challenging. For instance, a LLaMA2 model with $70$B parameters typically requires $128$GB for inference, which substantially surpasses $24$GB HBM in a $3090$ GPU and remains infeasible even considering the additional $64$GB DRAM. To address this challenge, this paper proposes a mixed-precision with a model modularization algorithm to enable LLM inference on outdated hardware with resource constraints. (The precision denotes the numerical precision like FP16, INT8, INT4) and multi-level caching (M2Cache).) Specifically, our M2Cache first modulizes neurons in LLM and creates their importance ranking. Then, it adopts a dynamic sparse mixed-precision quantization mechanism in weight space to reduce computational demands and communication overhead at each decoding step. It collectively lowers the operational carbon emissions associated with LLM inference. Moreover, M2Cache introduces a three-level cache management system with HBM, DRAM, and SSDs that complements the dynamic sparse mixed-precision inference. To enhance communication efficiency, M2Cache maintains a neuron-level mixed-precision LRU cache in HBM, a larger layer-aware cache in DRAM, and a full model in SSD.
GDeR: Safeguarding Efficiency, Balancing, and Robustness via Prototypical Graph Pruning
Oct 17, 2024



Training high-quality deep models necessitates vast amounts of data, resulting in overwhelming computational and memory demands. Recently, data pruning, distillation, and coreset selection have been developed to streamline data volume by retaining, synthesizing, or selecting a small yet informative subset from the full set. Among these methods, data pruning incurs the least additional training cost and offers the most practical acceleration benefits. However, it is the most vulnerable, often suffering significant performance degradation with imbalanced or biased data schema, thus raising concerns about its accuracy and reliability in on-device deployment. Therefore, there is a looming need for a new data pruning paradigm that maintains the efficiency of previous practices while ensuring balance and robustness. Unlike the fields of computer vision and natural language processing, where mature solutions have been developed to address these issues, graph neural networks (GNNs) continue to struggle with increasingly large-scale, imbalanced, and noisy datasets, lacking a unified dataset pruning solution. To achieve this, we introduce a novel dynamic soft-pruning method, GDeR, designed to update the training ``basket'' during the process using trainable prototypes. GDeR first constructs a well-modeled graph embedding hypersphere and then samples \textit{representative, balanced, and unbiased subsets} from this embedding space, which achieves the goal we called Graph Training Debugging. Extensive experiments on five datasets across three GNN backbones, demonstrate that GDeR (I) achieves or surpasses the performance of the full dataset with 30%~50% fewer training samples, (II) attains up to a 2.81x lossless training speedup, and (III) outperforms state-of-the-art pruning methods in imbalanced training and noisy training scenarios by 0.3%~4.3% and 3.6%~7.8%, respectively.
Adapt-$\infty$: Scalable Lifelong Multimodal Instruction Tuning via Dynamic Data Selection
Oct 14, 2024



Visual instruction datasets from various distributors are released at different times and often contain a significant number of semantically redundant text-image pairs, depending on their task compositions (i.e., skills) or reference sources. This redundancy greatly limits the efficient deployment of lifelong adaptable multimodal large language models, hindering their ability to refine existing skills and acquire new competencies over time. To address this, we reframe the problem of Lifelong Instruction Tuning (LiIT) via data selection, where the model automatically selects beneficial samples to learn from earlier and new datasets based on the current state of acquired knowledge in the model. Based on empirical analyses that show that selecting the best data subset using a static importance measure is often ineffective for multi-task datasets with evolving distributions, we propose Adapt-$\infty$, a new multi-way and adaptive data selection approach that dynamically balances sample efficiency and effectiveness during LiIT. We construct pseudo-skill clusters by grouping gradient-based sample vectors. Next, we select the best-performing data selector for each skill cluster from a pool of selector experts, including our newly proposed scoring function, Image Grounding score. This data selector samples a subset of the most important samples from each skill cluster for training. To prevent the continuous increase in the size of the dataset pool during LiIT, which would result in excessive computation, we further introduce a cluster-wise permanent data pruning strategy to remove the most semantically redundant samples from each cluster, keeping computational requirements manageable. Training with samples selected by Adapt-$\infty$ alleviates catastrophic forgetting, especially for rare tasks, and promotes forward transfer across the continuum using only a fraction of the original datasets.