 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIoT-based Continuous, Contextualized, and Explainable Driving Assessment for Older Adults
Feb 28, 2026The world is undergoing a major demographic shift as older adults become a rapidly growing share of the population, creating new challenges for driving safety. In car-dependent regions such as the United States, driving remains essential for independence, access to services, and social participation. At the same time, aging can introduce gradual changes in vision, attention, reaction time, and driving control that quietly reduce safety. Today's assessment methods rely largely on infrequent clinic visits or simple screening tools, offering only a brief snapshot and failing to reflect how an older adult actually drives on the road. Our work starts from the observation that everyday driving provides a continuous record of functional ability and captures how a driver responds to traffic, navigates complex roads, and manages routine behavior. Leveraging this insight, we propose AURA, an Artificial Intelligence of Things (AIoT) framework for continuous, real-world assessment of driving safety among older adults. AURA integrates richer in-vehicle sensing, multi-scale behavioral modeling, and context-aware analysis to extract detailed indicators of driving performance from routine trips. It organizes fine-grained actions into longer behavioral trajectories and separates age-related performance changes from situational factors such as traffic, road design, or weather. By integrating sensing, modeling, and interpretation within a privacy-preserving edge architecture, AURA provides a foundation for proactive, individualized support that helps older adults drive safely. This paper outlines the design principles, challenges, and research opportunities needed to build reliable, real-world monitoring systems that promote safer aging behind the wheel.
Morph: ChirpTransformer-based Encoder-decoder Co-design for Reliable LoRa Communication
Jul 30, 2025In this paper, we propose Morph, a LoRa encoder-decoder co-design to enhance communication reliability while improving its computation efficiency in extremely-low signal-to-noise ratio (SNR) situations. The standard LoRa encoder controls 6 Spreading Factors (SFs) to tradeoff SNR tolerance with data rate. SF-12 is the maximum SF providing the lowest SNR tolerance on commercial off-the-shelf (COTS) LoRa nodes. In Morph, we develop an SF-configuration based encoder to mimic the larger SFs beyond SF-12 while it is compatible with COTS LoRa nodes. Specifically, we manipulate four SF configurations of a Morph symbol to encode 2-bit data. Accordingly, we recognize the used SF configuration of the symbol for data decoding. We leverage a Deep Neural Network (DNN) decoder to fully capture multi-dimensional features among diverse SF configurations to maximize the SNR gain. Moreover, we customize the input size, neural network structure, and training method of the DNN decoder to improve its efficiency, reliability, and generalizability. We implement Morph with COTS LoRa nodes and a USRP N210, then evaluate its performance on indoor and campus-scale testbeds. Results show that we can reliably decode data at -28.8~dB SNR, which is 6.4~dB lower than the standard LoRa with SF-12 chirps. In addition, the computation efficiency of our DNN decoder is about 3x higher than state-of-the-art.
Hydra-Bench: A Benchmark for Multi-Modal Leaf Wetness Sensing
Jul 30, 2025Leaf wetness detection is a crucial task in agricultural monitoring, as it directly impacts the prediction and protection of plant diseases. However, existing sensing systems suffer from limitations in robustness, accuracy, and environmental resilience when applied to natural leaves under dynamic real-world conditions. To address these challenges, we introduce a new multi-modal dataset specifically designed for evaluating and advancing machine learning algorithms in leaf wetness detection. Our dataset comprises synchronized mmWave raw data, Synthetic Aperture Radar (SAR) images, and RGB images collected over six months from five diverse plant species in both controlled and outdoor field environments. We provide detailed benchmarks using the Hydra model, including comparisons against single modality baselines and multiple fusion strategies, as well as performance under varying scan distances. Additionally, our dataset can serve as a benchmark for future SAR imaging algorithm optimization, enabling a systematic evaluation of detection accuracy under diverse conditions.
Artificial Intelligence of Things: A Survey
Oct 25, 2024



The integration of the Internet of Things (IoT) and modern Artificial Intelligence (AI) has given rise to a new paradigm known as the Artificial Intelligence of Things (AIoT). In this survey, we provide a systematic and comprehensive review of AIoT research. We examine AIoT literature related to sensing, computing, and networking & communication, which form the three key components of AIoT. In addition to advancements in these areas, we review domain-specific AIoT systems that are designed for various important application domains. We have also created an accompanying GitHub repository, where we compile the papers included in this survey: https://github.com/AIoT-MLSys-Lab/AIoT-Survey. This repository will be actively maintained and updated with new research as it becomes available. As both IoT and AI become increasingly critical to our society, we believe AIoT is emerging as an essential research field at the intersection of IoT and modern AI. We hope this survey will serve as a valuable resource for those engaged in AIoT research and act as a catalyst for future explorations to bridge gaps and drive advancements in this exciting field.
* Accepted in ACM Transactions on Sensor Networks (TOSN)
Harnessing Your DRAM and SSD for Sustainable and Accessible LLM Inference with Mixed-Precision and Multi-level Caching
Oct 23, 2024



Although Large Language Models (LLMs) have demonstrated remarkable capabilities, their massive parameter counts and associated extensive computing make LLMs' deployment the main part of carbon emission from nowadays AI applications. Compared to modern GPUs like H$100$, it would be significantly carbon-sustainable if we could leverage old-fashioned GPUs such as M$40$ (as shown in Figure 1, M$40$ only has one third carbon emission of H$100$'s) for LLM servings. However, the limited High Bandwidth Memory (HBM) available on such GPU often cannot support the loading of LLMs due to the gigantic model size and intermediate activation data, making their serving challenging. For instance, a LLaMA2 model with $70$B parameters typically requires $128$GB for inference, which substantially surpasses $24$GB HBM in a $3090$ GPU and remains infeasible even considering the additional $64$GB DRAM. To address this challenge, this paper proposes a mixed-precision with a model modularization algorithm to enable LLM inference on outdated hardware with resource constraints. (The precision denotes the numerical precision like FP16, INT8, INT4) and multi-level caching (M2Cache).) Specifically, our M2Cache first modulizes neurons in LLM and creates their importance ranking. Then, it adopts a dynamic sparse mixed-precision quantization mechanism in weight space to reduce computational demands and communication overhead at each decoding step. It collectively lowers the operational carbon emissions associated with LLM inference. Moreover, M2Cache introduces a three-level cache management system with HBM, DRAM, and SSDs that complements the dynamic sparse mixed-precision inference. To enhance communication efficiency, M2Cache maintains a neuron-level mixed-precision LRU cache in HBM, a larger layer-aware cache in DRAM, and a full model in SSD.
FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things
Sep 29, 2023



There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works are not conducted on datasets collected from authentic IoT devices that capture unique modalities and inherent challenges of IoT data. In this work, we introduce FedAIoT, an FL benchmark for AIoT to fill this critical gap. FedAIoT includes eight datatsets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT.
NELoRa-Bench: A Benchmark for Neural-enhanced LoRa Demodulation
Apr 20, 2023



Low-Power Wide-Area Networks (LPWANs) are an emerging Internet-of-Things (IoT) paradigm marked by low-power and long-distance communication. Among them, LoRa is widely deployed for its unique characteristics and open-source technology. By adopting the Chirp Spread Spectrum (CSS) modulation, LoRa enables low signal-to-noise ratio (SNR) communication. The standard LoRa demodulation method accumulates the chirp power of the whole chirp into an energy peak in the frequency domain. In this way, it can support communication even when SNR is lower than -15 dB. Beyond that, we proposed NELoRa, a neural-enhanced decoder that exploits multi-dimensional information to achieve significant SNR gain. This paper presents the dataset used to train/test NELoRa, which includes 27,329 LoRa symbols with spreading factors from 7 to 10, for further improvement of neural-enhanced LoRa demodulation. The dataset shows that NELoRa can achieve 1.84-2.35 dB SNR gain over the standard LoRa decoder. The dataset and codes can be found at https://github.com/daibiaoxuwu/NeLoRa_Dataset.
WiVelo: Fine-grained Walking Velocity Estimation for Wi-Fi Passive Tracking
Jul 28, 2022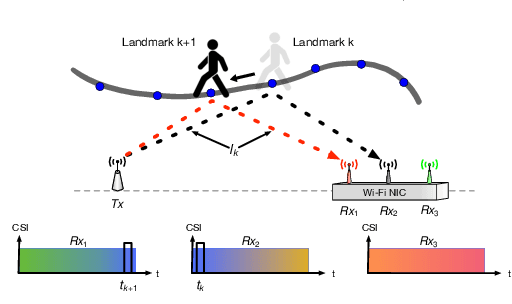
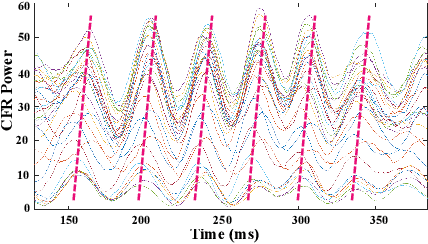
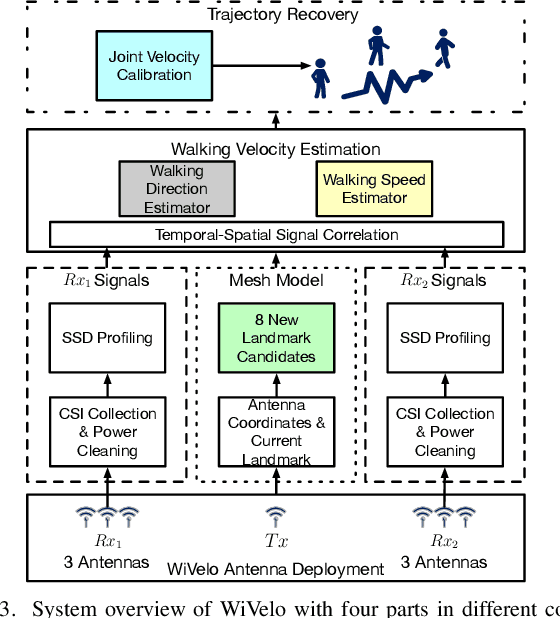
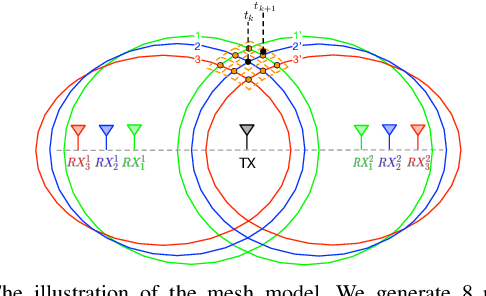
Passive human tracking via Wi-Fi has been researched broadly in the past decade. Besides straight-forward anchor point localization, velocity is another vital sign adopted by the existing approaches to infer user trajectory. However, state-of-the-art Wi-Fi velocity estimation relies on Doppler-Frequency-Shift (DFS) which suffers from the inevitable signal noise incurring unbounded velocity errors, further degrading the tracking accuracy. In this paper, we present WiVelo\footnote{Code\&datasets are available at \textit{https://github.com/liecn/WiVelo\_SECON22}} that explores new spatial-temporal signal correlation features observed from different antennas to achieve accurate velocity estimation. First, we use subcarrier shift distribution (SSD) extracted from channel state information (CSI) to define two correlation features for direction and speed estimation, separately. Then, we design a mesh model calculated by the antennas' locations to enable a fine-grained velocity estimation with bounded direction error. Finally, with the continuously estimated velocity, we develop an end-to-end trajectory recovery algorithm to mitigate velocity outliers with the property of walking velocity continuity. We implement WiVelo on commodity Wi-Fi hardware and extensively evaluate its tracking accuracy in various environments. The experimental results show our median and 90\% tracking errors are 0.47~m and 1.06~m, which are half and a quarter of state-of-the-arts.
NEC: Speaker Selective Cancellation via Neural Enhanced Ultrasound Shadowing
Jul 12, 2022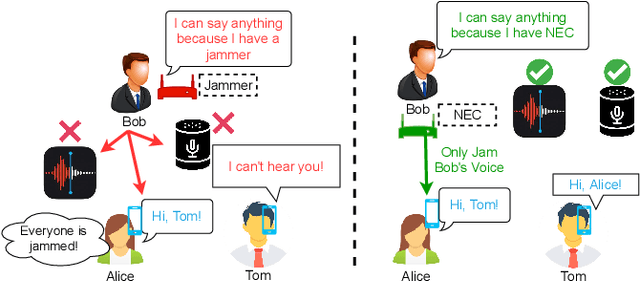


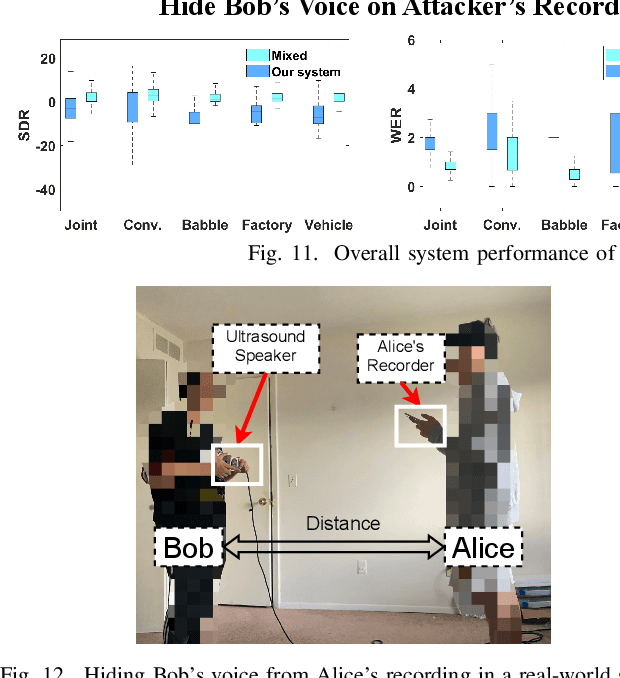
In this paper, we propose NEC (Neural Enhanced Cancellation), a defense mechanism, which prevents unauthorized microphones from capturing a target speaker's voice. Compared with the existing scrambling-based audio cancellation approaches, NEC can selectively remove a target speaker's voice from a mixed speech without causing interference to others. Specifically, for a target speaker, we design a Deep Neural Network (DNN) model to extract high-level speaker-specific but utterance-independent vocal features from his/her reference audios. When the microphone is recording, the DNN generates a shadow sound to cancel the target voice in real-time. Moreover, we modulate the audible shadow sound onto an ultrasound frequency, making it inaudible for humans. By leveraging the non-linearity of the microphone circuit, the microphone can accurately decode the shadow sound for target voice cancellation. We implement and evaluate NEC comprehensively with 8 smartphone microphones in different settings. The results show that NEC effectively mutes the target speaker at a microphone without interfering with other users' normal conversations.