 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePETS: A Principled Framework Towards Optimal Trajectory Allocation for Efficient Test-Time Self-Consistency
Feb 18, 2026Test-time scaling can improve model performance by aggregating stochastic reasoning trajectories. However, achieving sample-efficient test-time self-consistency under a limited budget remains an open challenge. We introduce PETS (Principled and Efficient Test-TimeSelf-Consistency), which initiates a principled study of trajectory allocation through an optimization framework. Central to our approach is the self-consistency rate, a new measure defined as agreement with the infinite-budget majority vote. This formulation makes sample-efficient test-time allocation theoretically grounded and amenable to rigorous analysis. We study both offline and online settings. In the offline regime, where all questions are known in advance, we connect trajectory allocation to crowdsourcing, a classic and well-developed area, by modeling reasoning traces as workers. This perspective allows us to leverage rich existing theory, yielding theoretical guarantees and an efficient majority-voting-based allocation algorithm. In the online streaming regime, where questions arrive sequentially and allocations must be made on the fly, we propose a novel method inspired by the offline framework. Our approach adapts budgets to question difficulty while preserving strong theoretical guarantees and computational efficiency. Experiments show that PETS consistently outperforms uniform allocation. On GPQA, PETS achieves perfect self-consistency in both settings while reducing the sampling budget by up to 75% (offline) and 55% (online) relative to uniform allocation. Code is available at https://github.com/ZDCSlab/PETS.
Multi-Agent Debate for LLM Judges with Adaptive Stability Detection
Oct 14, 2025



With advancements in reasoning capabilities, Large Language Models (LLMs) are increasingly employed for automated judgment tasks. While LLMs-as-Judges offer promise in automating evaluations, current approaches often rely on simplistic aggregation methods (e.g., majority voting), which can fail even when individual agents provide correct answers. To address this, we propose a multi-agent debate judge framework where agents collaboratively reason and iteratively refine their responses. We formalize the debate process mathematically, analyzing agent interactions and proving that debate amplifies correctness compared to static ensembles. To enhance efficiency, we introduce a stability detection mechanism that models judge consensus dynamics via a time-varying Beta-Binomial mixture, with adaptive stopping based on distributional similarity (Kolmogorov-Smirnov test). This mechanism models the judges' collective correct rate dynamics using a time-varying mixture of Beta-Binomial distributions and employs an adaptive stopping criterion based on distributional similarity (Kolmogorov-Smirnov statistic). Experiments across multiple benchmarks and models demonstrate that our framework improves judgment accuracy over majority voting while maintaining computational efficiency.
DOGe: Defensive Output Generation for LLM Protection Against Knowledge Distillation
May 26, 2025
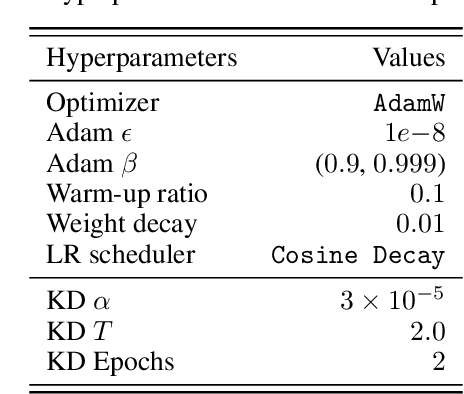
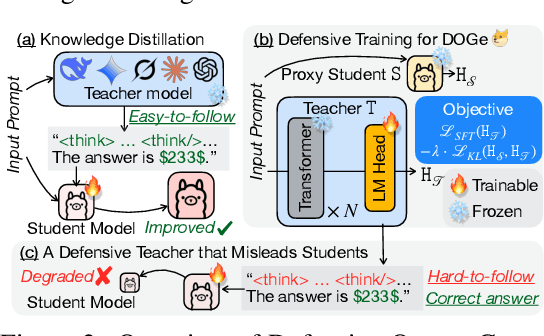

Large Language Models (LLMs) represent substantial intellectual and economic investments, yet their effectiveness can inadvertently facilitate model imitation via knowledge distillation (KD).In practical scenarios, competitors can distill proprietary LLM capabilities by simply observing publicly accessible outputs, akin to reverse-engineering a complex performance by observation alone. Existing protective methods like watermarking only identify imitation post-hoc, while other defenses assume the student model mimics the teacher's internal logits, rendering them ineffective against distillation purely from observed output text. This paper confronts the challenge of actively protecting LLMs within the realistic constraints of API-based access. We introduce an effective and efficient Defensive Output Generation (DOGe) strategy that subtly modifies the output behavior of an LLM. Its outputs remain accurate and useful for legitimate users, yet are designed to be misleading for distillation, significantly undermining imitation attempts. We achieve this by fine-tuning only the final linear layer of the teacher LLM with an adversarial loss. This targeted training approach anticipates and disrupts distillation attempts during inference time. Our experiments show that, while preserving or even improving the original performance of the teacher model, student models distilled from the defensively generated teacher outputs demonstrate catastrophically reduced performance, demonstrating our method's effectiveness as a practical safeguard against KD-based model imitation.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
May 26, 2025The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
Efficient MAP Estimation of LLM Judgment Performance with Prior Transfer
Apr 17, 2025



LLM ensembles are widely used for LLM judges. However, how to estimate their accuracy, especially in an efficient way, is unknown. In this paper, we present a principled maximum a posteriori (MAP) framework for an economical and precise estimation of the performance of LLM ensemble judgment. We first propose a mixture of Beta-Binomial distributions to model the judgment distribution, revising from the vanilla Binomial distribution. Next, we introduce a conformal prediction-driven approach that enables adaptive stopping during iterative sampling to balance accuracy with efficiency. Furthermore, we design a prior transfer mechanism that utilizes learned distributions on open-source datasets to improve estimation on a target dataset when only scarce annotations are available. Finally, we present BetaConform, a framework that integrates our distribution assumption, adaptive stopping, and the prior transfer mechanism to deliver a theoretically guaranteed distribution estimation of LLM ensemble judgment with minimum labeled samples. BetaConform is also validated empirically. For instance, with only 10 samples from the TruthfulQA dataset, for a Llama ensembled judge, BetaConform gauges its performance with error margin as small as 3.37%.
$\texttt{LucidAtlas}$: Learning Uncertainty-Aware, Covariate-Disentangled, Individualized Atlas Representations
Feb 12, 2025The goal of this work is to develop principled techniques to extract information from high dimensional data sets with complex dependencies in areas such as medicine that can provide insight into individual as well as population level variation. We develop $\texttt{LucidAtlas}$, an approach that can represent spatially varying information, and can capture the influence of covariates as well as population uncertainty. As a versatile atlas representation, $\texttt{LucidAtlas}$ offers robust capabilities for covariate interpretation, individualized prediction, population trend analysis, and uncertainty estimation, with the flexibility to incorporate prior knowledge. Additionally, we discuss the trustworthiness and potential risks of neural additive models for analyzing dependent covariates and then introduce a marginalization approach to explain the dependence of an individual predictor on the models' response (the atlas). To validate our method, we demonstrate its generalizability on two medical datasets. Our findings underscore the critical role of by-construction interpretable models in advancing scientific discovery. Our code will be publicly available upon acceptance.
Harnessing Your DRAM and SSD for Sustainable and Accessible LLM Inference with Mixed-Precision and Multi-level Caching
Oct 23, 2024



Although Large Language Models (LLMs) have demonstrated remarkable capabilities, their massive parameter counts and associated extensive computing make LLMs' deployment the main part of carbon emission from nowadays AI applications. Compared to modern GPUs like H$100$, it would be significantly carbon-sustainable if we could leverage old-fashioned GPUs such as M$40$ (as shown in Figure 1, M$40$ only has one third carbon emission of H$100$'s) for LLM servings. However, the limited High Bandwidth Memory (HBM) available on such GPU often cannot support the loading of LLMs due to the gigantic model size and intermediate activation data, making their serving challenging. For instance, a LLaMA2 model with $70$B parameters typically requires $128$GB for inference, which substantially surpasses $24$GB HBM in a $3090$ GPU and remains infeasible even considering the additional $64$GB DRAM. To address this challenge, this paper proposes a mixed-precision with a model modularization algorithm to enable LLM inference on outdated hardware with resource constraints. (The precision denotes the numerical precision like FP16, INT8, INT4) and multi-level caching (M2Cache).) Specifically, our M2Cache first modulizes neurons in LLM and creates their importance ranking. Then, it adopts a dynamic sparse mixed-precision quantization mechanism in weight space to reduce computational demands and communication overhead at each decoding step. It collectively lowers the operational carbon emissions associated with LLM inference. Moreover, M2Cache introduces a three-level cache management system with HBM, DRAM, and SSDs that complements the dynamic sparse mixed-precision inference. To enhance communication efficiency, M2Cache maintains a neuron-level mixed-precision LRU cache in HBM, a larger layer-aware cache in DRAM, and a full model in SSD.
Omni-Recon: Towards General-Purpose Neural Radiance Fields for Versatile 3D Applications
Mar 17, 2024Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.