 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting LLaMA Decoder to Vision Transformer
Apr 13, 2024This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field. We first "LLaMAfy" a standard ViT step-by-step to align with LLaMA's architecture, and find that directly applying a casual mask to the self-attention brings an attention collapse issue, resulting in the failure to the network training. We suggest to reposition the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image's information. Additionally, we develop a soft mask strategy that gradually introduces a casual mask to the self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning. Its causal self-attention boosts computational efficiency and learns complex representation by elevating attention map ranks. iLLaMA rivals the performance with its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters. Scaling the model to ~310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA's reliable properties: calibration, shape-texture bias, quantization compatibility, ADE20K segmentation and CIFAR transfer learning. We hope our study can kindle fresh views to visual model design in the wave of LLMs. Pre-trained models and codes are available here.
Ada-LEval: Evaluating long-context LLMs with length-adaptable benchmarks
Apr 10, 2024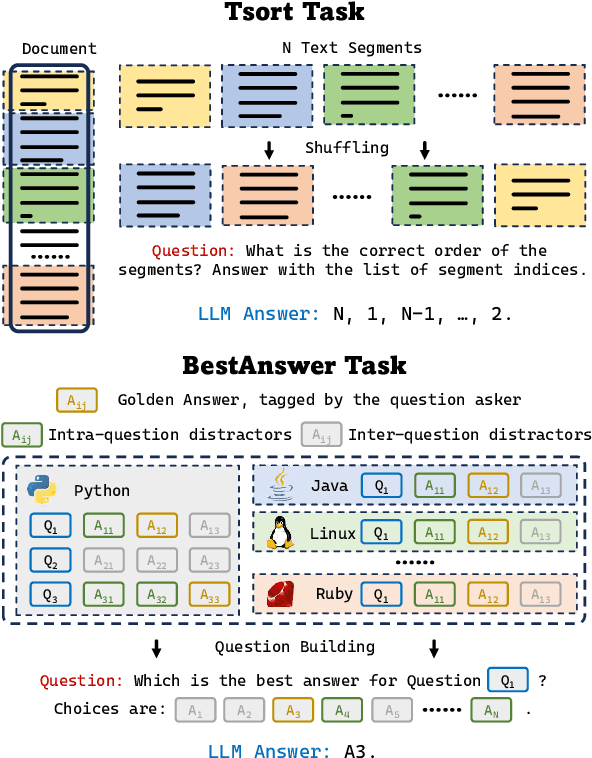
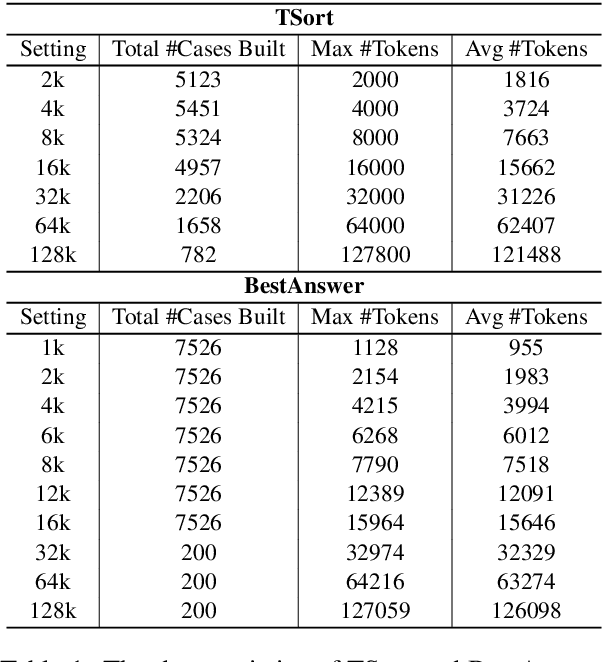
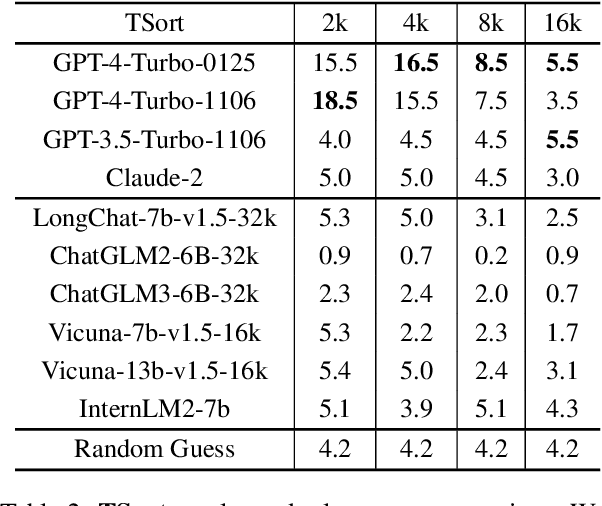
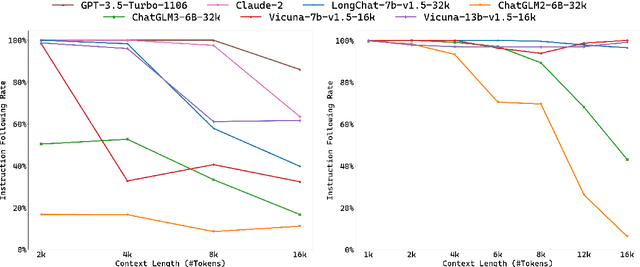
Recently, the large language model (LLM) community has shown increasing interest in enhancing LLMs' capability to handle extremely long documents. As various long-text techniques and model architectures emerge, the precise and detailed evaluation of models' long-text capabilities has become increasingly important. Existing long-text evaluation benchmarks, such as L-Eval and LongBench, construct long-text test sets based on open-source datasets, focusing mainly on QA and summarization tasks. These datasets include test samples of varying lengths (from 2k to 32k+) entangled together, making it challenging to assess model capabilities across different length ranges. Moreover, they do not cover the ultralong settings (100k+ tokens) that the latest LLMs claim to achieve. In this paper, we introduce Ada-LEval, a length-adaptable benchmark for evaluating the long-context understanding of LLMs. Ada-LEval includes two challenging subsets, TSort and BestAnswer, which enable a more reliable evaluation of LLMs' long context capabilities. These benchmarks support intricate manipulation of the length of test cases, and can easily produce text samples up to 128k tokens. We evaluate 4 state-of-the-art closed-source API models and 6 open-source models with Ada-LEval. The evaluation results demonstrate the limitations of current LLMs, especially in ultra-long-context settings. Our code is available at https://github.com/open-compass/Ada-LEval.
InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
Apr 09, 2024



The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Apr 06, 2024Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
RadioGAT: A Joint Model-based and Data-driven Framework for Multi-band Radiomap Reconstruction via Graph Attention Networks
Mar 25, 2024



Multi-band radiomap reconstruction (MB-RMR) is a key component in wireless communications for tasks such as spectrum management and network planning. However, traditional machine-learning-based MB-RMR methods, which rely heavily on simulated data or complete structured ground truth, face significant deployment challenges. These challenges stem from the differences between simulated and actual data, as well as the scarcity of real-world measurements. To address these challenges, our study presents RadioGAT, a novel framework based on Graph Attention Network (GAT) tailored for MB-RMR within a single area, eliminating the need for multi-region datasets. RadioGAT innovatively merges model-based spatial-spectral correlation encoding with data-driven radiomap generalization, thus minimizing the reliance on extensive data sources. The framework begins by transforming sparse multi-band data into a graph structure through an innovative encoding strategy that leverages radio propagation models to capture the spatial-spectral correlation inherent in the data. This graph-based representation not only simplifies data handling but also enables tailored label sampling during training, significantly enhancing the framework's adaptability for deployment. Subsequently, The GAT is employed to generalize the radiomap information across various frequency bands. Extensive experiments using raytracing datasets based on real-world environments have demonstrated RadioGAT's enhanced accuracy in supervised learning settings and its robustness in semi-supervised scenarios. These results underscore RadioGAT's effectiveness and practicality for MB-RMR in environments with limited data availability.
Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations
Mar 21, 2024We introduce CHARM, the first benchmark for comprehensively and in-depth evaluating the commonsense reasoning ability of large language models (LLMs) in Chinese, which covers both globally known and Chinese-specific commonsense. We evaluated 7 English and 12 Chinese-oriented LLMs on CHARM, employing 5 representative prompt strategies for improving LLMs' reasoning ability, such as Chain-of-Thought. Our findings indicate that the LLM's language orientation and the task's domain influence the effectiveness of the prompt strategy, which enriches previous research findings. We built closely-interconnected reasoning and memorization tasks, and found that some LLMs struggle with memorizing Chinese commonsense, affecting their reasoning ability, while others show differences in reasoning despite similar memorization performance. We also evaluated the LLMs' memorization-independent reasoning abilities and analyzed the typical errors. Our study precisely identified the LLMs' strengths and weaknesses, providing the clear direction for optimization. It can also serve as a reference for studies in other fields. We will release CHARM at https://github.com/opendatalab/CHARM .
InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning
Feb 09, 2024



The math abilities of large language models can represent their abstract reasoning ability. In this paper, we introduce and open-source our math reasoning LLMs InternLM-Math which is continue pre-trained from InternLM2. We unify chain-of-thought reasoning, reward modeling, formal reasoning, data augmentation, and code interpreter in a unified seq2seq format and supervise our model to be a versatile math reasoner, verifier, prover, and augmenter. These abilities can be used to develop the next math LLMs or self-iteration. InternLM-Math obtains open-sourced state-of-the-art performance under the setting of in-context learning, supervised fine-tuning, and code-assisted reasoning in various informal and formal benchmarks including GSM8K, MATH, Hungary math exam, MathBench-ZH, and MiniF2F. Our pre-trained model achieves 30.3 on the MiniF2F test set without fine-tuning. We further explore how to use LEAN to solve math problems and study its performance under the setting of multi-task learning which shows the possibility of using LEAN as a unified platform for solving and proving in math. Our models, codes, and data are released at \url{https://github.com/InternLM/InternLM-Math}.
InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model
Jan 29, 2024



We introduce InternLM-XComposer2, a cutting-edge vision-language model excelling in free-form text-image composition and comprehension. This model goes beyond conventional vision-language understanding, adeptly crafting interleaved text-image content from diverse inputs like outlines, detailed textual specifications, and reference images, enabling highly customizable content creation. InternLM-XComposer2 proposes a Partial LoRA (PLoRA) approach that applies additional LoRA parameters exclusively to image tokens to preserve the integrity of pre-trained language knowledge, striking a balance between precise vision understanding and text composition with literary talent. Experimental results demonstrate the superiority of InternLM-XComposer2 based on InternLM2-7B in producing high-quality long-text multi-modal content and its exceptional vision-language understanding performance across various benchmarks, where it not only significantly outperforms existing multimodal models but also matches or even surpasses GPT-4V and Gemini Pro in certain assessments. This highlights its remarkable proficiency in the realm of multimodal understanding. The InternLM-XComposer2 model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
SGTR+: End-to-end Scene Graph Generation with Transformer
Jan 23, 2024



Scene Graph Generation (SGG) remains a challenging visual understanding task due to its compositional property. Most previous works adopt a bottom-up, two-stage or point-based, one-stage approach, which often suffers from high time complexity or suboptimal designs. In this work, we propose a novel SGG method to address the aforementioned issues, formulating the task as a bipartite graph construction problem. To address the issues above, we create a transformer-based end-to-end framework to generate the entity and entity-aware predicate proposal set, and infer directed edges to form relation triplets. Moreover, we design a graph assembling module to infer the connectivity of the bipartite scene graph based on our entity-aware structure, enabling us to generate the scene graph in an end-to-end manner. Based on bipartite graph assembling paradigm, we further propose a new technical design to address the efficacy of entity-aware modeling and optimization stability of graph assembling. Equipped with the enhanced entity-aware design, our method achieves optimal performance and time-complexity. Extensive experimental results show that our design is able to achieve the state-of-the-art or comparable performance on three challenging benchmarks, surpassing most of the existing approaches and enjoying higher efficiency in inference. Code is available: https://github.com/Scarecrow0/SGTR