 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT-Flow: Speech Enhancement Robust to Multiple Distortions based on Flow Matching in Latent Space and Diffusion Transformers
Mar 23, 2026Recent advances in generative models, such as diffusion and flow matching, have shown strong performance in audio tasks. However, speech enhancement (SE) models are typically trained on limited datasets and evaluated under narrow conditions, limiting real-world applicability. To address this, we propose DiT-Flow, a flow matching-based SE framework built on the latent Diffusion Transformer (DiT) backbone and trained for robustness across diverse distortions, including noise, reverberation, and compression. DiT-Flow operates on compact variational auto-encoders (VAEs)-derived latent features. We validated our approach on StillSonicSet, a synthetic yet acoustically realistic dataset composed of LibriSpeech, FSD50K, FMA, and 90 Matterport3D scenes. Experiments show that DiT-Flow consistently outperforms state-of-the-art generative SE models, demonstrating the effectiveness of flow matching in multi-condition speech enhancement. Despite ongoing efforts to expand synthetic data realism, a persistent bottleneck in SE is the inevitable mismatch between training and deployment conditions. By integrating LoRA with the MoE framework, we achieve both parameter-efficient and high-performance training for DiT-Flow robust to multiple distortions with using 4.9% percentage of the total parameters to obtain a better performance on five unseen distortions.
SAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
Jan 27, 2026The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
Summary of The Inaugural Music Source Restoration Challenge
Jan 07, 2026Music Source Restoration (MSR) aims to recover original, unprocessed instrument stems from professionally mixed and degraded audio, requiring the reversal of both production effects and real-world degradations. We present the inaugural MSR Challenge, which features objective evaluation on studio-produced mixtures using Multi-Mel-SNR, Zimtohrli, and FAD-CLAP, alongside subjective evaluation on real-world degraded recordings. Five teams participated in the challenge. The winning system achieved 4.46 dB Multi-Mel-SNR and 3.47 MOS-Overall, corresponding to relative improvements of 91% and 18% over the second-place system, respectively. Per-stem analysis reveals substantial variation in restoration difficulty across instruments, with bass averaging 4.59 dB across all teams, while percussion averages only 0.29 dB. The dataset, evaluation protocols, and baselines are available at https://msrchallenge.com/.
SAM Audio: Segment Anything in Audio
Dec 19, 2025



General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
Spoken DialogSum: An Emotion-Rich Conversational Dataset for Spoken Dialogue Summarization
Dec 17, 2025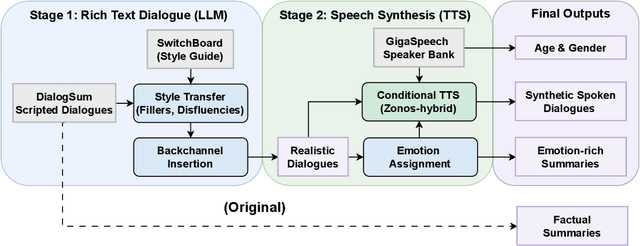

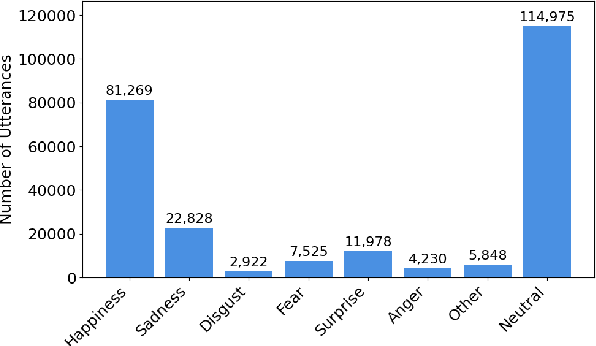
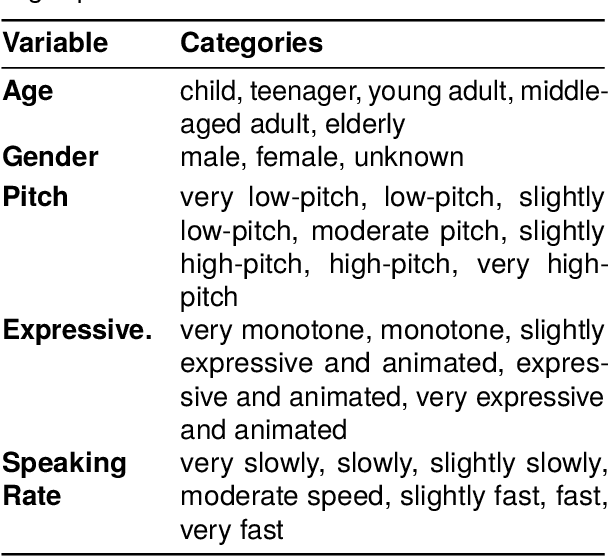
Recent audio language models can follow long conversations. However, research on emotion-aware or spoken dialogue summarization is constrained by the lack of data that links speech, summaries, and paralinguistic cues. We introduce Spoken DialogSum, the first corpus aligning raw conversational audio with factual summaries, emotion-rich summaries, and utterance-level labels for speaker age, gender, and emotion. The dataset is built in two stages: first, an LLM rewrites DialogSum scripts with Switchboard-style fillers and back-channels, then tags each utterance with emotion, pitch, and speaking rate. Second, an expressive TTS engine synthesizes speech from the tagged scripts, aligned with paralinguistic labels. Spoken DialogSum comprises 13,460 emotion-diverse dialogues, each paired with both a factual and an emotion-focused summary. We release an online demo at https://fatfat-emosum.github.io/EmoDialog-Sum-Audio-Samples/, with plans to release the full dataset in the near future. Baselines show that an Audio-LLM raises emotional-summary ROUGE-L by 28% relative to a cascaded ASR-LLM system, confirming the value of end-to-end speech modeling.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Audio Large Language Models Can Be Descriptive Speech Quality Evaluators
Jan 27, 2025An ideal multimodal agent should be aware of the quality of its input modalities. Recent advances have enabled large language models (LLMs) to incorporate auditory systems for handling various speech-related tasks. However, most audio LLMs remain unaware of the quality of the speech they process. This limitation arises because speech quality evaluation is typically excluded from multi-task training due to the lack of suitable datasets. To address this, we introduce the first natural language-based speech evaluation corpus, generated from authentic human ratings. In addition to the overall Mean Opinion Score (MOS), this corpus offers detailed analysis across multiple dimensions and identifies causes of quality degradation. It also enables descriptive comparisons between two speech samples (A/B tests) with human-like judgment. Leveraging this corpus, we propose an alignment approach with LLM distillation (ALLD) to guide the audio LLM in extracting relevant information from raw speech and generating meaningful responses. Experimental results demonstrate that ALLD outperforms the previous state-of-the-art regression model in MOS prediction, with a mean square error of 0.17 and an A/B test accuracy of 98.6%. Additionally, the generated responses achieve BLEU scores of 25.8 and 30.2 on two tasks, surpassing the capabilities of task-specific models. This work advances the comprehensive perception of speech signals by audio LLMs, contributing to the development of real-world auditory and sensory intelligent agents.
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
Sep 17, 2024Latent diffusion models have shown promising results in text-to-audio (T2A) generation tasks, yet previous models have encountered difficulties in generation quality, computational cost, diffusion sampling, and data preparation. In this paper, we introduce EzAudio, a transformer-based T2A diffusion model, to handle these challenges. Our approach includes several key innovations: (1) We build the T2A model on the latent space of a 1D waveform Variational Autoencoder (VAE), avoiding the complexities of handling 2D spectrogram representations and using an additional neural vocoder. (2) We design an optimized diffusion transformer architecture specifically tailored for audio latent representations and diffusion modeling, which enhances convergence speed, training stability, and memory usage, making the training process easier and more efficient. (3) To tackle data scarcity, we adopt a data-efficient training strategy that leverages unlabeled data for learning acoustic dependencies, audio caption data annotated by audio-language models for text-to-audio alignment learning, and human-labeled data for fine-tuning. (4) We introduce a classifier-free guidance (CFG) rescaling method that simplifies EzAudio by achieving strong prompt alignment while preserving great audio quality when using larger CFG scores, eliminating the need to struggle with finding the optimal CFG score to balance this trade-off. EzAudio surpasses existing open-source models in both objective metrics and subjective evaluations, delivering realistic listening experiences while maintaining a streamlined model structure, low training costs, and an easy-to-follow training pipeline. Code, data, and pre-trained models are released at: https://haidog-yaqub.github.io/EzAudio-Page/.
SoloAudio: Target Sound Extraction with Language-oriented Audio Diffusion Transformer
Sep 12, 2024In this paper, we introduce SoloAudio, a novel diffusion-based generative model for target sound extraction (TSE). Our approach trains latent diffusion models on audio, replacing the previous U-Net backbone with a skip-connected Transformer that operates on latent features. SoloAudio supports both audio-oriented and language-oriented TSE by utilizing a CLAP model as the feature extractor for target sounds. Furthermore, SoloAudio leverages synthetic audio generated by state-of-the-art text-to-audio models for training, demonstrating strong generalization to out-of-domain data and unseen sound events. We evaluate this approach on the FSD Kaggle 2018 mixture dataset and real data from AudioSet, where SoloAudio achieves the state-of-the-art results on both in-domain and out-of-domain data, and exhibits impressive zero-shot and few-shot capabilities. Source code and demos are released.