 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation
Mar 25, 2025



Autoregressive (AR) models have demonstrated impressive capabilities in generating high-fidelity music. However, the conventional next-token prediction paradigm in AR models does not align with the human creative process in music composition, potentially compromising the musicality of generated samples. To overcome this limitation, we introduce MusiCoT, a novel chain-of-thought (CoT) prompting technique tailored for music generation. MusiCoT empowers the AR model to first outline an overall music structure before generating audio tokens, thereby enhancing the coherence and creativity of the resulting compositions. By leveraging the contrastive language-audio pretraining (CLAP) model, we establish a chain of "musical thoughts", making MusiCoT scalable and independent of human-labeled data, in contrast to conventional CoT methods. Moreover, MusiCoT allows for in-depth analysis of music structure, such as instrumental arrangements, and supports music referencing -- accepting variable-length audio inputs as optional style references. This innovative approach effectively addresses copying issues, positioning MusiCoT as a vital practical method for music prompting. Our experimental results indicate that MusiCoT consistently achieves superior performance across both objective and subjective metrics, producing music quality that rivals state-of-the-art generation models. Our samples are available at https://MusiCoT.github.io/.
SongCreator: Lyrics-based Universal Song Generation
Sep 09, 2024



Music is an integral part of human culture, embodying human intelligence and creativity, of which songs compose an essential part. While various aspects of song generation have been explored by previous works, such as singing voice, vocal composition and instrumental arrangement, etc., generating songs with both vocals and accompaniment given lyrics remains a significant challenge, hindering the application of music generation models in the real world. In this light, we propose SongCreator, a song-generation system designed to tackle this challenge. The model features two novel designs: a meticulously designed dual-sequence language model (DSLM) to capture the information of vocals and accompaniment for song generation, and an additional attention mask strategy for DSLM, which allows our model to understand, generate and edit songs, making it suitable for various song-related generation tasks. Extensive experiments demonstrate the effectiveness of SongCreator by achieving state-of-the-art or competitive performances on all eight tasks. Notably, it surpasses previous works by a large margin in lyrics-to-song and lyrics-to-vocals. Additionally, it is able to independently control the acoustic conditions of the vocals and accompaniment in the generated song through different prompts, exhibiting its potential applicability. Our samples are available at https://songcreator.github.io/.
Foundation Models for Music: A Survey
Aug 27, 2024



In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model
May 26, 2023Expressive human speech generally abounds with rich and flexible speech prosody variations. The speech prosody predictors in existing expressive speech synthesis methods mostly produce deterministic predictions, which are learned by directly minimizing the norm of prosody prediction error. Its unimodal nature leads to a mismatch with ground truth distribution and harms the model's ability in making diverse predictions. Thus, we propose a novel prosody predictor based on the denoising diffusion probabilistic model to take advantage of its high-quality generative modeling and training stability. Experiment results confirm that the proposed prosody predictor outperforms the deterministic baseline on both the expressiveness and diversity of prediction results with even fewer network parameters.
Efficient Neural Music Generation
May 25, 2023



Recent progress in music generation has been remarkably advanced by the state-of-the-art MusicLM, which comprises a hierarchy of three LMs, respectively, for semantic, coarse acoustic, and fine acoustic modelings. Yet, sampling with the MusicLM requires processing through these LMs one by one to obtain the fine-grained acoustic tokens, making it computationally expensive and prohibitive for a real-time generation. Efficient music generation with a quality on par with MusicLM remains a significant challenge. In this paper, we present MeLoDy (M for music; L for LM; D for diffusion), an LM-guided diffusion model that generates music audios of state-of-the-art quality meanwhile reducing 95.7% or 99.6% forward passes in MusicLM, respectively, for sampling 10s or 30s music. MeLoDy inherits the highest-level LM from MusicLM for semantic modeling, and applies a novel dual-path diffusion (DPD) model and an audio VAE-GAN to efficiently decode the conditioning semantic tokens into waveform. DPD is proposed to simultaneously model the coarse and fine acoustics by incorporating the semantic information into segments of latents effectively via cross-attention at each denoising step. Our experimental results suggest the superiority of MeLoDy, not only in its practical advantages on sampling speed and infinitely continuable generation, but also in its state-of-the-art musicality, audio quality, and text correlation. Our samples are available at https://Efficient-MeLoDy.github.io/.
FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis
Apr 21, 2022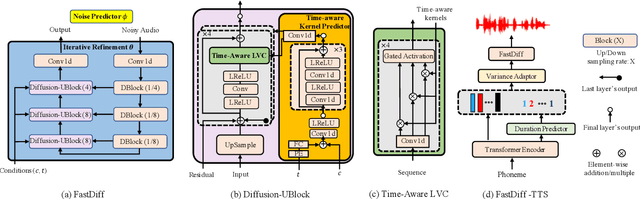
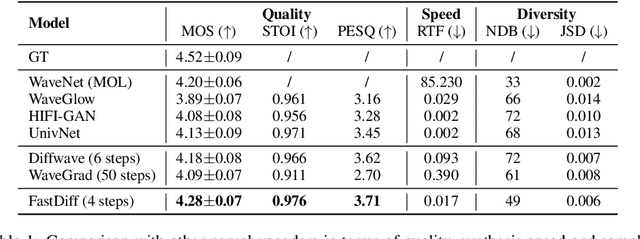
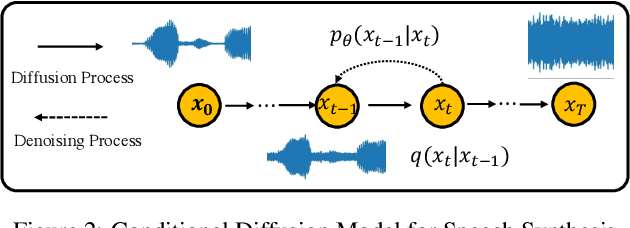

Denoising diffusion probabilistic models (DDPMs) have recently achieved leading performances in many generative tasks. However, the inherited iterative sampling process costs hindered their applications to speech synthesis. This paper proposes FastDiff, a fast conditional diffusion model for high-quality speech synthesis. FastDiff employs a stack of time-aware location-variable convolutions of diverse receptive field patterns to efficiently model long-term time dependencies with adaptive conditions. A noise schedule predictor is also adopted to reduce the sampling steps without sacrificing the generation quality. Based on FastDiff, we design an end-to-end text-to-speech synthesizer, FastDiff-TTS, which generates high-fidelity speech waveforms without any intermediate feature (e.g., Mel-spectrogram). Our evaluation of FastDiff demonstrates the state-of-the-art results with higher-quality (MOS 4.28) speech samples. Also, FastDiff enables a sampling speed of 58x faster than real-time on a V100 GPU, making diffusion models practically applicable to speech synthesis deployment for the first time. We further show that FastDiff generalized well to the mel-spectrogram inversion of unseen speakers, and FastDiff-TTS outperformed other competing methods in end-to-end text-to-speech synthesis. Audio samples are available at \url{https://FastDiff.github.io/}.
BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis
Mar 25, 2022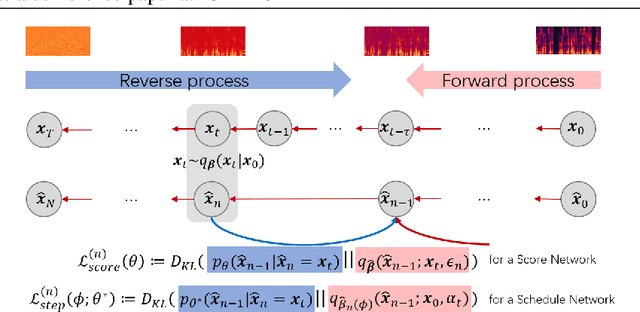
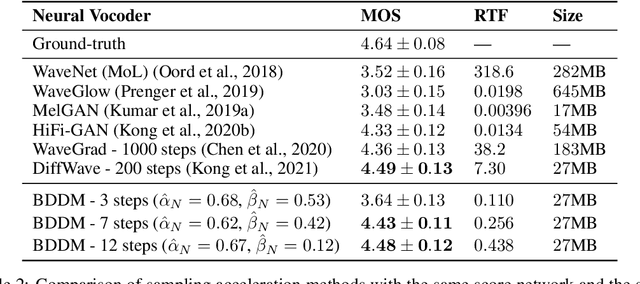
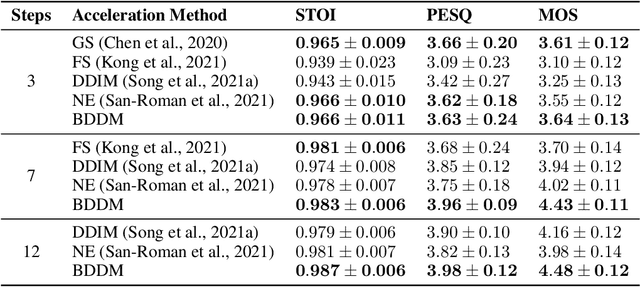
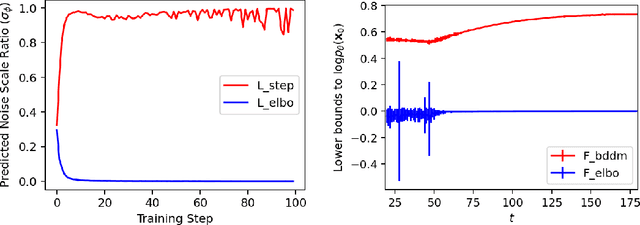
Diffusion probabilistic models (DPMs) and their extensions have emerged as competitive generative models yet confront challenges of efficient sampling. We propose a new bilateral denoising diffusion model (BDDM) that parameterizes both the forward and reverse processes with a schedule network and a score network, which can train with a novel bilateral modeling objective. We show that the new surrogate objective can achieve a lower bound of the log marginal likelihood tighter than a conventional surrogate. We also find that BDDM allows inheriting pre-trained score network parameters from any DPMs and consequently enables speedy and stable learning of the schedule network and optimization of a noise schedule for sampling. Our experiments demonstrate that BDDMs can generate high-fidelity audio samples with as few as three sampling steps. Moreover, compared to other state-of-the-art diffusion-based neural vocoders, BDDMs produce comparable or higher quality samples indistinguishable from human speech, notably with only seven sampling steps (143x faster than WaveGrad and 28.6x faster than DiffWave). We release our code at https://github.com/tencent-ailab/bddm.
* Accepted in ICLR 2022. arXiv admin note: text overlap with arXiv:2108.11514
Bilateral Denoising Diffusion Models
Aug 31, 2021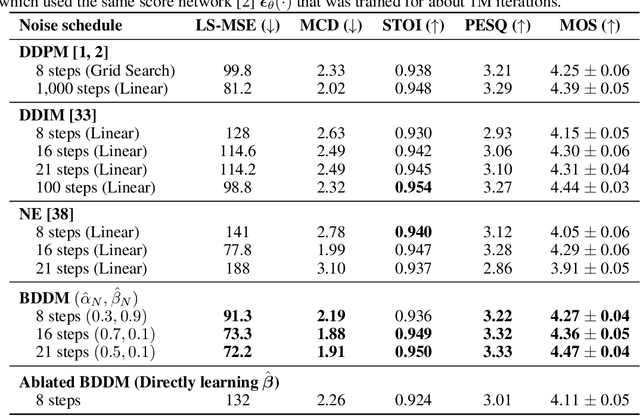
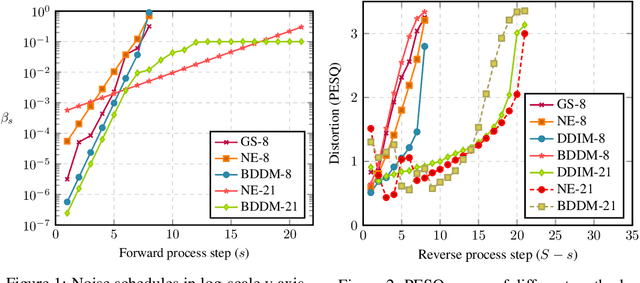
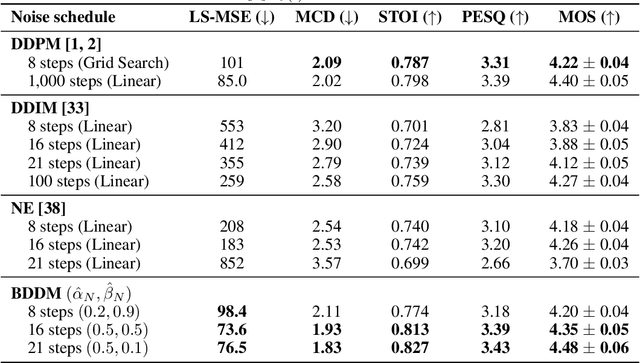
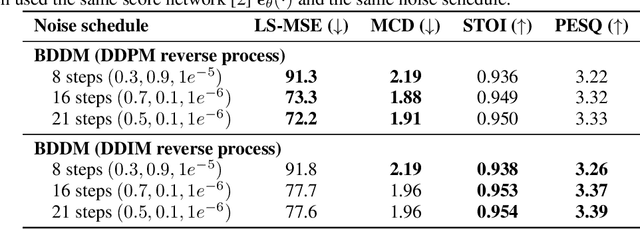
Denoising diffusion probabilistic models (DDPMs) have emerged as competitive generative models yet brought challenges to efficient sampling. In this paper, we propose novel bilateral denoising diffusion models (BDDMs), which take significantly fewer steps to generate high-quality samples. From a bilateral modeling objective, BDDMs parameterize the forward and reverse processes with a score network and a scheduling network, respectively. We show that a new lower bound tighter than the standard evidence lower bound can be derived as a surrogate objective for training the two networks. In particular, BDDMs are efficient, simple-to-train, and capable of further improving any pre-trained DDPM by optimizing the inference noise schedules. Our experiments demonstrated that BDDMs can generate high-fidelity samples with as few as 3 sampling steps and produce comparable or even higher quality samples than DDPMs using 1000 steps with only 16 sampling steps (a 62x speedup).
Raw Waveform Encoder with Multi-Scale Globally Attentive Locally Recurrent Networks for End-to-End Speech Recognition
Jun 08, 2021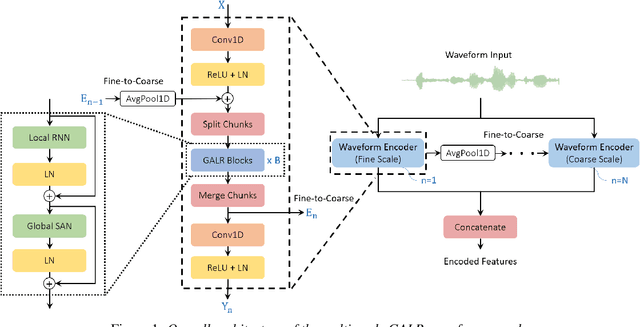
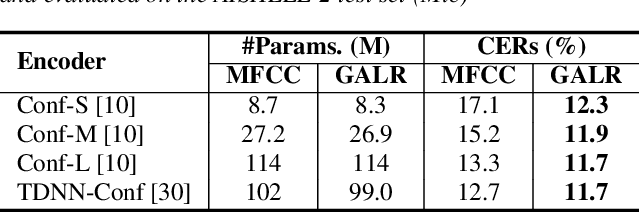
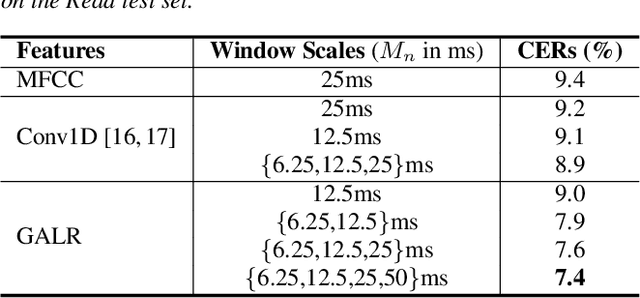
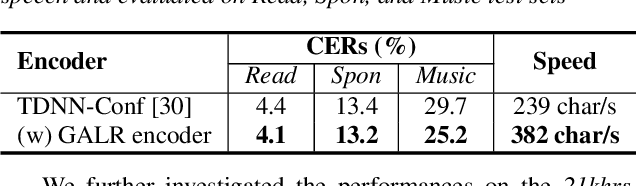
End-to-end speech recognition generally uses hand-engineered acoustic features as input and excludes the feature extraction module from its joint optimization. To extract learnable and adaptive features and mitigate information loss, we propose a new encoder that adopts globally attentive locally recurrent (GALR) networks and directly takes raw waveform as input. We observe improved ASR performance and robustness by applying GALR on different window lengths to aggregate fine-grain temporal information into multi-scale acoustic features. Experiments are conducted on a benchmark dataset AISHELL-2 and two large-scale Mandarin speech corpus of 5,000 hours and 21,000 hours. With faster speed and comparable model size, our proposed multi-scale GALR waveform encoder achieved consistent character error rate reductions (CERRs) from 7.9% to 28.1% relative over strong baselines, including Conformer and TDNN-Conformer. In particular, our approach demonstrated notable robustness than the traditional handcrafted features and outperformed the baseline MFCC-based TDNN-Conformer model by a 15.2% CERR on a music-mixed real-world speech test set.
Sandglasset: A Light Multi-Granularity Self-attentive Network For Time-Domain Speech Separation
Mar 08, 2021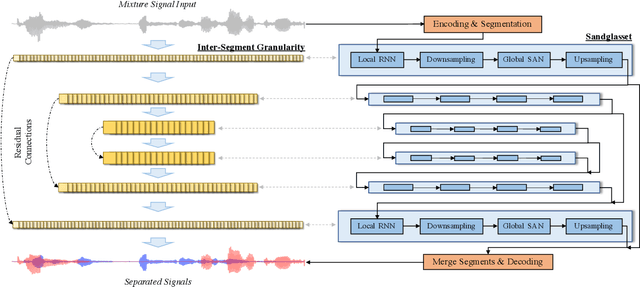
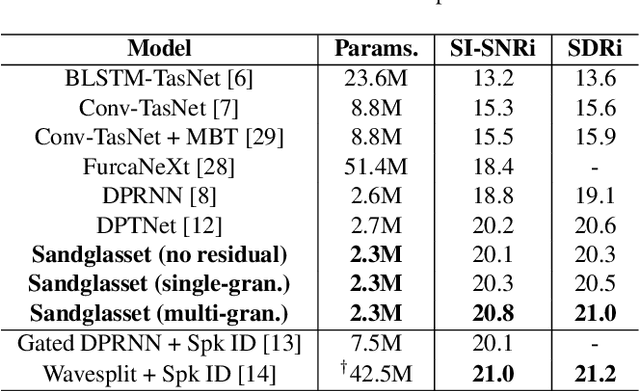
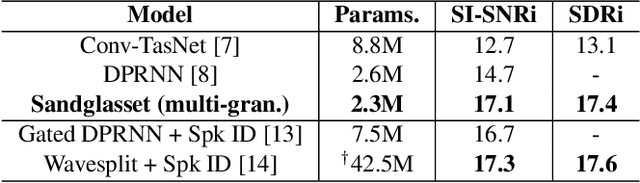
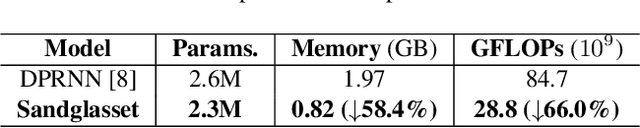
One of the leading single-channel speech separation (SS) models is based on a TasNet with a dual-path segmentation technique, where the size of each segment remains unchanged throughout all layers. In contrast, our key finding is that multi-granularity features are essential for enhancing contextual modeling and computational efficiency. We introduce a self-attentive network with a novel sandglass-shape, namely Sandglasset, which advances the state-of-the-art (SOTA) SS performance at significantly smaller model size and computational cost. Forward along each block inside Sandglasset, the temporal granularity of the features gradually becomes coarser until reaching half of the network blocks, and then successively turns finer towards the raw signal level. We also unfold that residual connections between features with the same granularity are critical for preserving information after passing through the bottleneck layer. Experiments show our Sandglasset with only 2.3M parameters has achieved the best results on two benchmark SS datasets -- WSJ0-2mix and WSJ0-3mix, where the SI-SNRi scores have been improved by absolute 0.8 dB and 2.4 dB, respectively, comparing to the prior SOTA results.