 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-robust Expressive TTS
Paper and Code
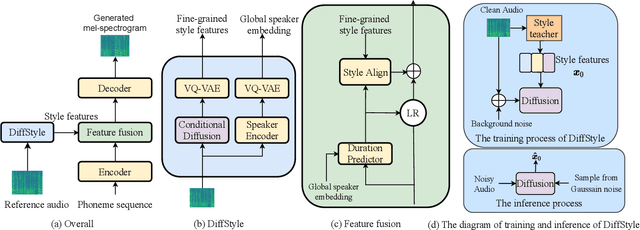
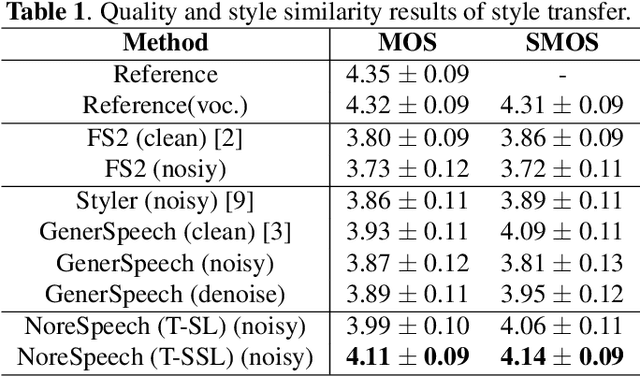

Expressive text-to-speech (TTS) can synthesize a new speaking style by imiating prosody and timbre from a reference audio, which faces the following challenges: (1) The highly dynamic prosody information in the reference audio is difficult to extract, especially, when the reference audio contains background noise. (2) The TTS systems should have good generalization for unseen speaking styles. In this paper, we present a \textbf{no}ise-\textbf{r}obust \textbf{e}xpressive TTS model (NoreSpeech), which can robustly transfer speaking style in a noisy reference utterance to synthesized speech. Specifically, our NoreSpeech includes several components: (1) a novel DiffStyle module, which leverages powerful probabilistic denoising diffusion models to learn noise-agnostic speaking style features from a teacher model by knowledge distillation; (2) a VQ-VAE block, which maps the style features into a controllable quantized latent space for improving the generalization of style transfer; and (3) a straight-forward but effective parameter-free text-style alignment module, which enables NoreSpeech to transfer style to a textual input from a length-mismatched reference utterance. Experiments demonstrate that NoreSpeech is more effective than previous expressive TTS models in noise environments. Audio samples and code are available at: \href{http://dongchaoyang.top/NoreSpeech\_demo/}{http://dongchaoyang.top/NoreSpeech\_demo/}