 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Prompt Tuning for Few-shot Text Classification
May 11, 2022
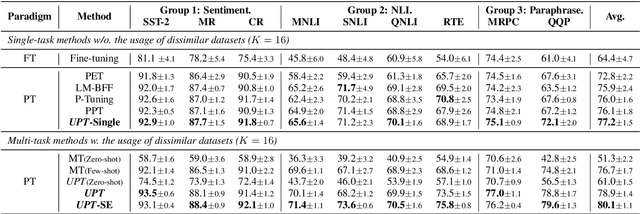
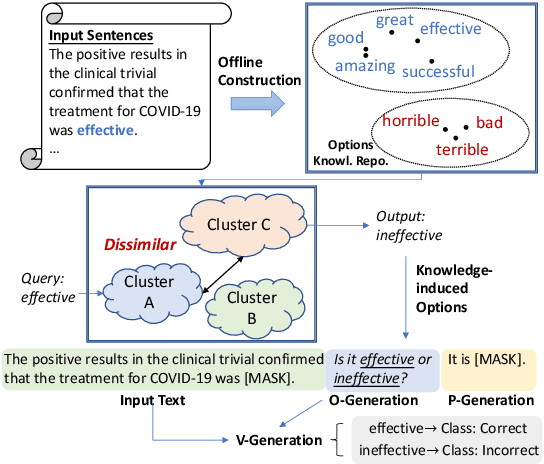
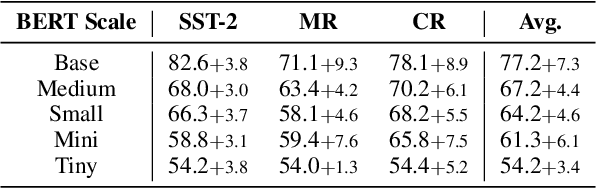
Prompt-based fine-tuning has boosted the performance of Pre-trained Language Models (PLMs) on few-shot text classification by employing task-specific prompts. Yet, PLMs are unfamiliar with prompt-style expressions during pre-training, which limits the few-shot learning performance on downstream tasks. It would be desirable if the models can acquire some prompting knowledge before adaptation to specific NLP tasks. We present the Unified Prompt Tuning (UPT) framework, leading to better few-shot text classification for BERT-style models by explicitly capturing prompting semantics from non-target NLP datasets. In UPT, a novel paradigm Prompt-Options-Verbalizer is proposed for joint prompt learning across different NLP tasks, forcing PLMs to capture task-invariant prompting knowledge. We further design a self-supervised task named Knowledge-enhanced Selective Masked Language Modeling to improve the PLM's generalization abilities for accurate adaptation to previously unseen tasks. After multi-task learning across multiple tasks, the PLM can be better prompt-tuned towards any dissimilar target tasks in low-resourced settings. Experiments over a variety of NLP tasks show that UPT consistently outperforms state-of-the-arts for prompt-based fine-tuning.
Contrastive Demonstration Tuning for Pre-trained Language Models
Apr 18, 2022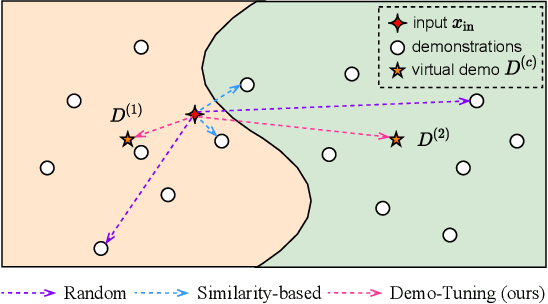
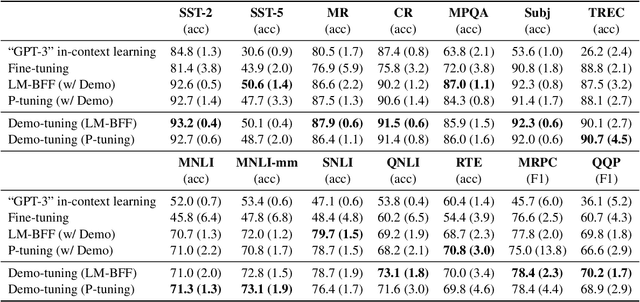
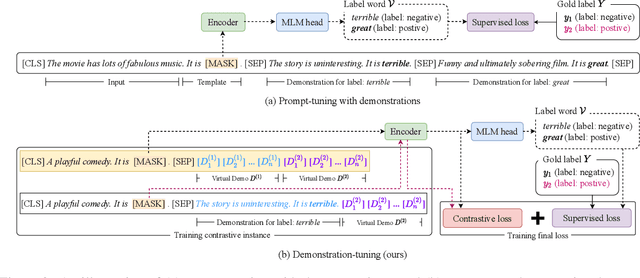
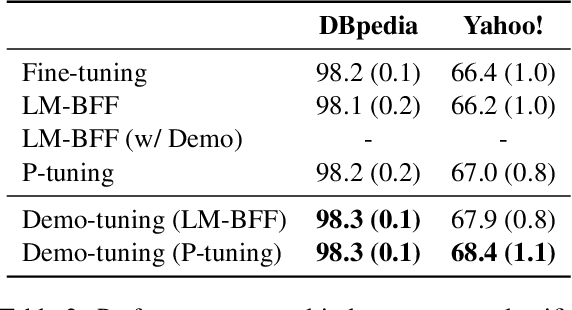
Pretrained language models can be effectively stimulated by textual prompts or demonstrations, especially in low-data scenarios. Recent works have focused on automatically searching discrete or continuous prompts or optimized verbalizers, yet studies for the demonstration are still limited. Concretely, the demonstration examples are crucial for an excellent final performance of prompt-tuning. In this paper, we propose a novel pluggable, extensible, and efficient approach named contrastive demonstration tuning, which is free of demonstration sampling. Furthermore, the proposed approach can be: (i) Plugged to any previous prompt-tuning approaches; (ii) Extended to widespread classification tasks with a large number of categories. Experimental results on 16 datasets illustrate that our method integrated with previous approaches LM-BFF and P-tuning can yield better performance. Code is available in https://github.com/zjunlp/PromptKG/tree/main/research/Demo-Tuning.
Image Captioning In the Transformer Age
Apr 15, 2022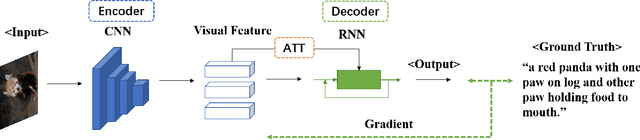
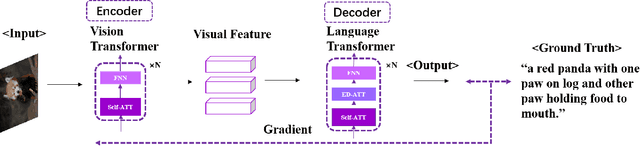
Image Captioning (IC) has achieved astonishing developments by incorporating various techniques into the CNN-RNN encoder-decoder architecture. However, since CNN and RNN do not share the basic network component, such a heterogeneous pipeline is hard to be trained end-to-end where the visual encoder will not learn anything from the caption supervision. This drawback inspires the researchers to develop a homogeneous architecture that facilitates end-to-end training, for which Transformer is the perfect one that has proven its huge potential in both vision and language domains and thus can be used as the basic component of the visual encoder and language decoder in an IC pipeline. Meantime, self-supervised learning releases the power of the Transformer architecture that a pre-trained large-scale one can be generalized to various tasks including IC. The success of these large-scale models seems to weaken the importance of the single IC task. However, we demonstrate that IC still has its specific significance in this age by analyzing the connections between IC with some popular self-supervised learning paradigms. Due to the page limitation, we only refer to highly important papers in this short survey and more related works can be found at https://github.com/SjokerLily/awesome-image-captioning.
Probing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency
Apr 06, 2022
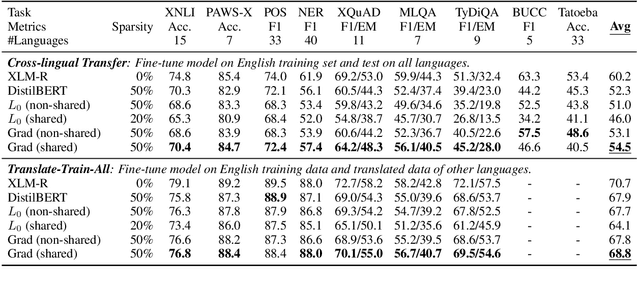
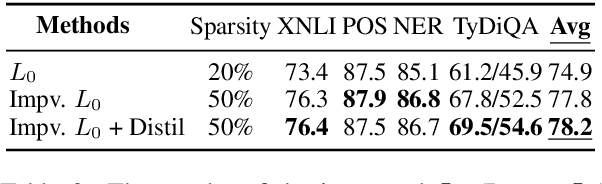
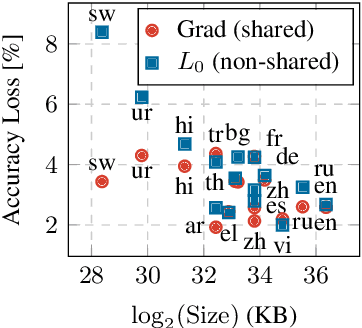
Structured pruning has been extensively studied on monolingual pre-trained language models and is yet to be fully evaluated on their multilingual counterparts. This work investigates three aspects of structured pruning on multilingual pre-trained language models: settings, algorithms, and efficiency. Experiments on nine downstream tasks show several counter-intuitive phenomena: for settings, individually pruning for each language does not induce a better result; for algorithms, the simplest method performs the best; for efficiency, a fast model does not imply that it is also small. To facilitate the comparison on all sparsity levels, we present Dynamic Sparsification, a simple approach that allows training the model once and adapting to different model sizes at inference. We hope this work fills the gap in the study of structured pruning on multilingual pre-trained models and sheds light on future research.
Making Pre-trained Language Models End-to-end Few-shot Learners with Contrastive Prompt Tuning
Apr 01, 2022

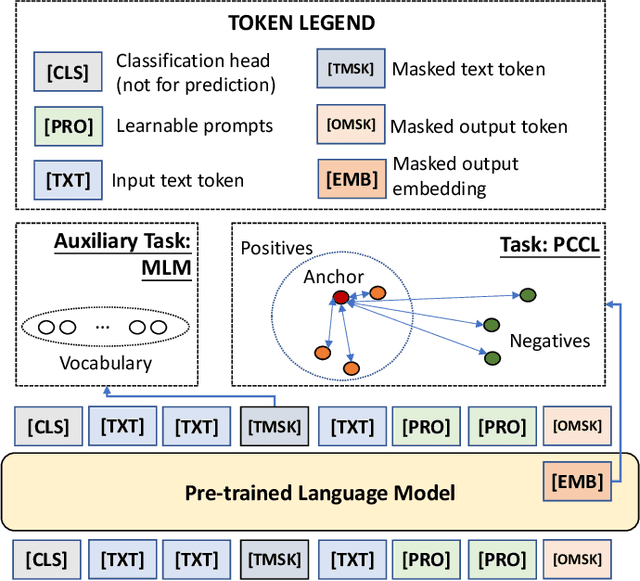
Pre-trained Language Models (PLMs) have achieved remarkable performance for various language understanding tasks in IR systems, which require the fine-tuning process based on labeled training data. For low-resource scenarios, prompt-based learning for PLMs exploits prompts as task guidance and turns downstream tasks into masked language problems for effective few-shot fine-tuning. In most existing approaches, the high performance of prompt-based learning heavily relies on handcrafted prompts and verbalizers, which may limit the application of such approaches in real-world scenarios. To solve this issue, we present CP-Tuning, the first end-to-end Contrastive Prompt Tuning framework for fine-tuning PLMs without any manual engineering of task-specific prompts and verbalizers. It is integrated with the task-invariant continuous prompt encoding technique with fully trainable prompt parameters. We further propose the pair-wise cost-sensitive contrastive learning procedure to optimize the model in order to achieve verbalizer-free class mapping and enhance the task-invariance of prompts. It explicitly learns to distinguish different classes and makes the decision boundary smoother by assigning different costs to easy and hard cases. Experiments over a variety of language understanding tasks used in IR systems and different PLMs show that CP-Tuning outperforms state-of-the-art methods.
Code Synonyms Do Matter: Multiple Synonyms Matching Network for Automatic ICD Coding
Mar 31, 2022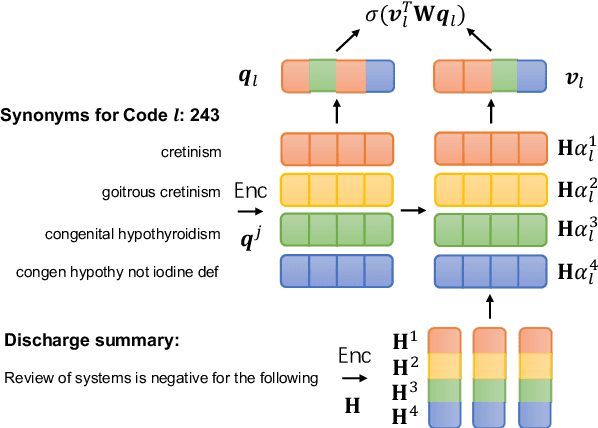
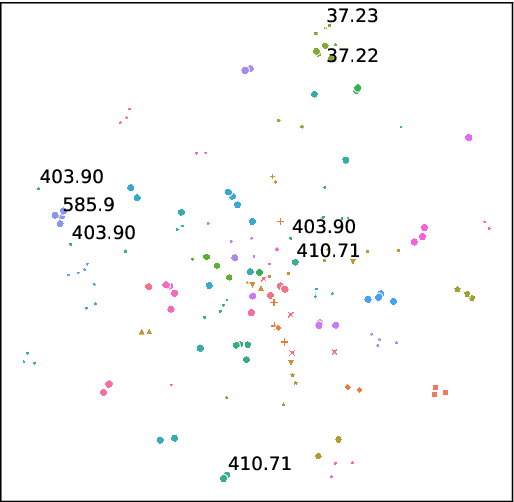
Automatic ICD coding is defined as assigning disease codes to electronic medical records (EMRs). Existing methods usually apply label attention with code representations to match related text snippets. Unlike these works that model the label with the code hierarchy or description, we argue that the code synonyms can provide more comprehensive knowledge based on the observation that the code expressions in EMRs vary from their descriptions in ICD. By aligning codes to concepts in UMLS, we collect synonyms of every code. Then, we propose a multiple synonyms matching network to leverage synonyms for better code representation learning, and finally help the code classification. Experiments on the MIMIC-III dataset show that our proposed method outperforms previous state-of-the-art methods.
From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
Dec 14, 2021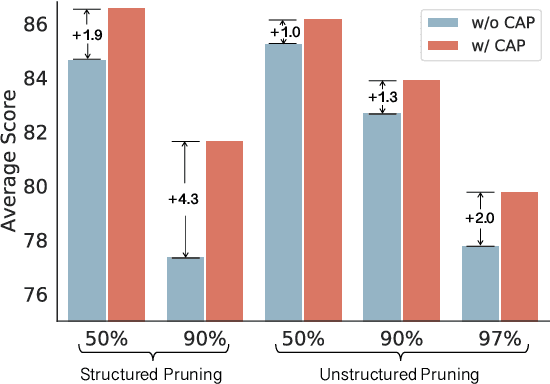
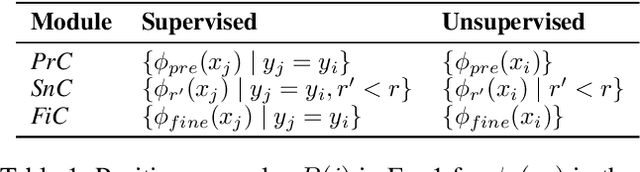
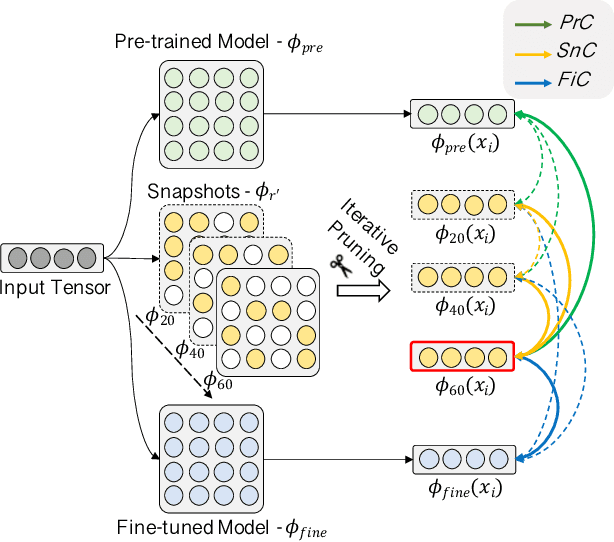
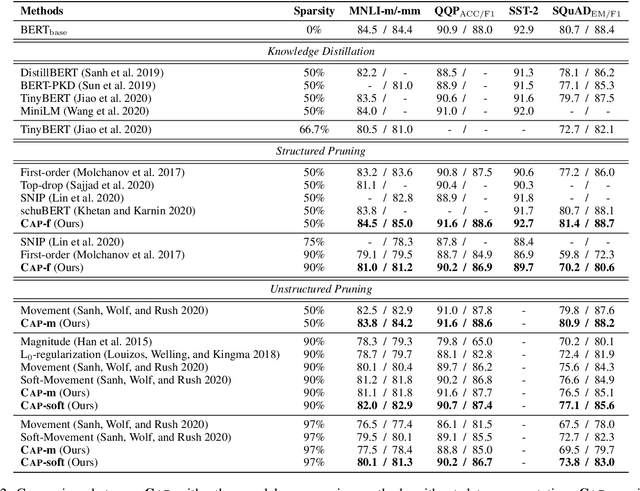
Pre-trained Language Models (PLMs) have achieved great success in various Natural Language Processing (NLP) tasks under the pre-training and fine-tuning paradigm. With large quantities of parameters, PLMs are computation-intensive and resource-hungry. Hence, model pruning has been introduced to compress large-scale PLMs. However, most prior approaches only consider task-specific knowledge towards downstream tasks, but ignore the essential task-agnostic knowledge during pruning, which may cause catastrophic forgetting problem and lead to poor generalization ability. To maintain both task-agnostic and task-specific knowledge in our pruned model, we propose ContrAstive Pruning (CAP) under the paradigm of pre-training and fine-tuning. It is designed as a general framework, compatible with both structured and unstructured pruning. Unified in contrastive learning, CAP enables the pruned model to learn from the pre-trained model for task-agnostic knowledge, and fine-tuned model for task-specific knowledge. Besides, to better retain the performance of the pruned model, the snapshots (i.e., the intermediate models at each pruning iteration) also serve as effective supervisions for pruning. Our extensive experiments show that adopting CAP consistently yields significant improvements, especially in extremely high sparsity scenarios. With only 3% model parameters reserved (i.e., 97% sparsity), CAP successfully achieves 99.2% and 96.3% of the original BERT performance in QQP and MNLI tasks. In addition, our probing experiments demonstrate that the model pruned by CAP tends to achieve better generalization ability.
LOGEN: Few-shot Logical Knowledge-Conditioned Text Generation with Self-training
Dec 02, 2021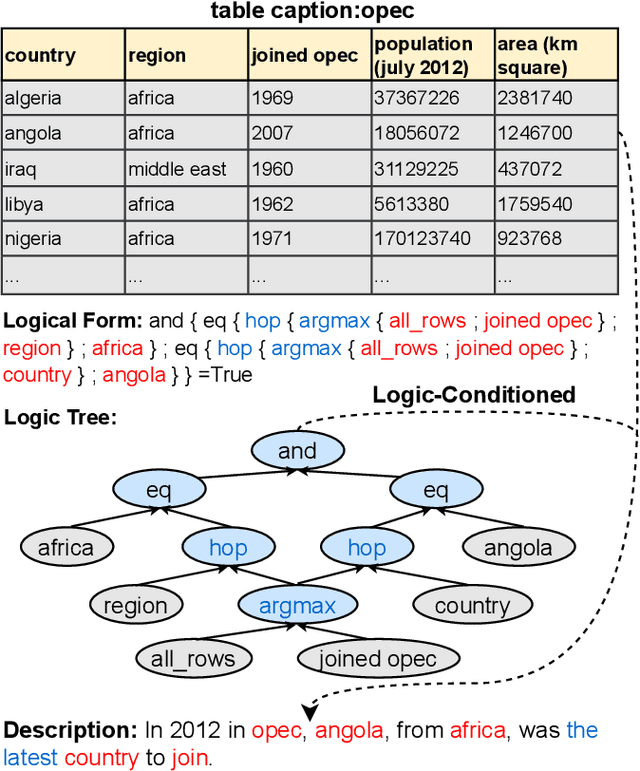
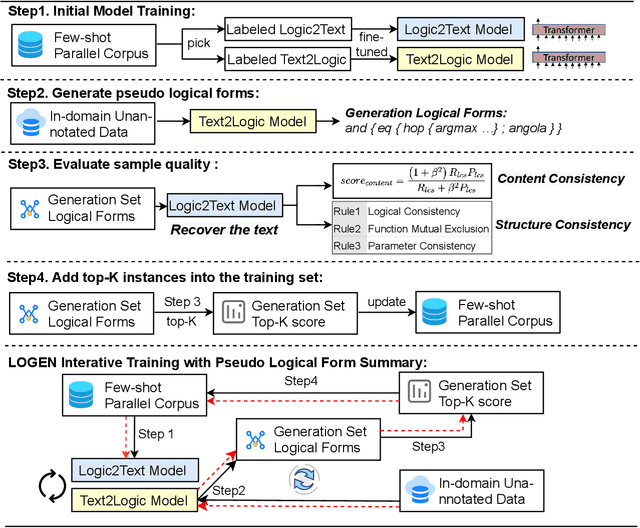
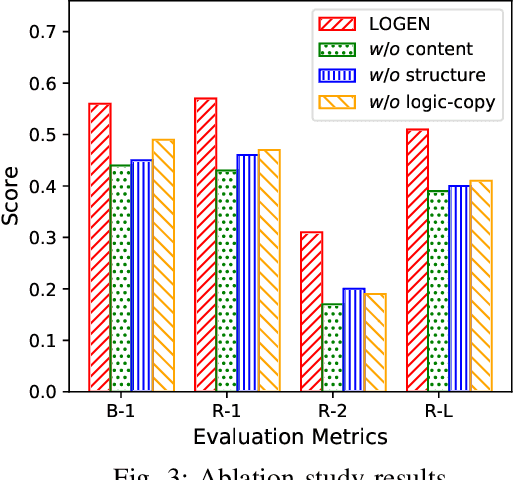

Natural language generation from structured data mainly focuses on surface-level descriptions, suffering from uncontrollable content selection and low fidelity. Previous works leverage logical forms to facilitate logical knowledge-conditioned text generation. Though achieving remarkable progress, they are data-hungry, which makes the adoption for real-world applications challenging with limited data. To this end, this paper proposes a unified framework for logical knowledge-conditioned text generation in the few-shot setting. With only a few seeds logical forms (e.g., 20/100 shot), our approach leverages self-training and samples pseudo logical forms based on content and structure consistency. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.
Achieving Human Parity on Visual Question Answering
Nov 19, 2021
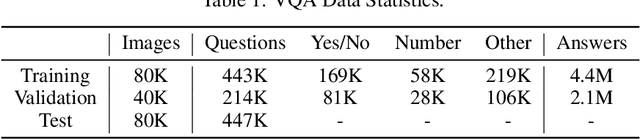
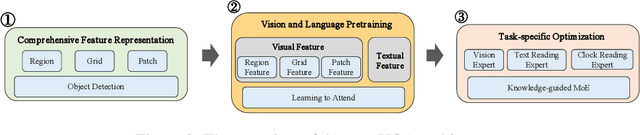
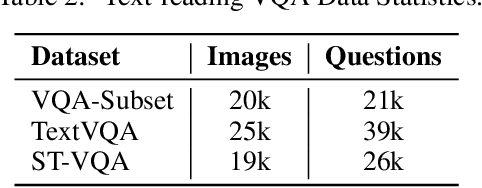
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.
A Chinese Multi-type Complex Questions Answering Dataset over Wikidata
Nov 11, 2021
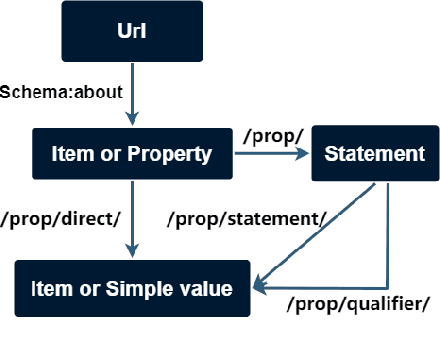
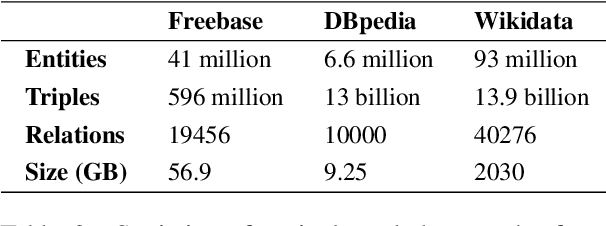
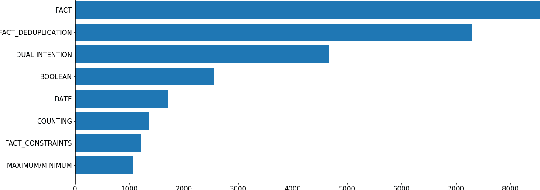
Complex Knowledge Base Question Answering is a popular area of research in the past decade. Recent public datasets have led to encouraging results in this field, but are mostly limited to English and only involve a small number of question types and relations, hindering research in more realistic settings and in languages other than English. In addition, few state-of-the-art KBQA models are trained on Wikidata, one of the most popular real-world knowledge bases. We propose CLC-QuAD, the first large scale complex Chinese semantic parsing dataset over Wikidata to address these challenges. Together with the dataset, we present a text-to-SPARQL baseline model, which can effectively answer multi-type complex questions, such as factual questions, dual intent questions, boolean questions, and counting questions, with Wikidata as the background knowledge. We finally analyze the performance of SOTA KBQA models on this dataset and identify the challenges facing Chinese KBQA.