 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIGQ: An End-to-End Hybrid Generative Architecture for E-commerce Query Recommendation
Mar 20, 2026Pre-search query recommendation, widely known as HintQ on Taobao's homepage, plays a vital role in intent capture and demand discovery, yet traditional methods suffer from shallow semantics, poor cold-start performance and low serendipity due to reliance on ID-based matching and co-click heuristics. To overcome these challenges, we propose AIGQ (AI-Generated Query architecture), the first end-to-end generative framework for HintQ scenario. AIGQ is built upon three core innovations spanning training paradigm, policy optimization and deployment architecture. First, we propose Interest-Aware List Supervised Fine-Tuning (IL-SFT), a list-level supervised learning approach that constructs training samples through session-aware behavior aggregation and interest-guided re-ranking strategy to faithfully model nuanced user intent. Accordingly, we design Interest-aware List Group Relative Policy Optimization (IL-GRPO), a novel policy gradient algorithm with a dual-component reward mechanism that jointly optimizes individual query relevance and global list properties, enhanced by a model-based reward from the online click-through rate (CTR) ranking model. To deploy under strict real-time and low-latency requirements, we further develop a hybrid offline-online architecture comprising AIGQ-Direct for nearline personalized user-to-query generation and AIGQ-Think, a reasoning-enhanced variant that produces trigger-to-query mappings to enrich interest diversity. Extensive offline evaluations and large-scale online A/B experiments on Taobao demonstrate that AIGQ consistently delivers substantial improvements in key business metrics across platform effectiveness and user engagement.
A Chinese Multi-type Complex Questions Answering Dataset over Wikidata
Nov 11, 2021
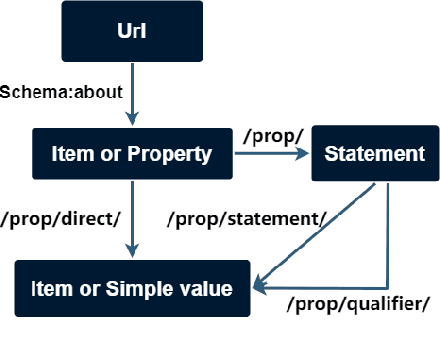
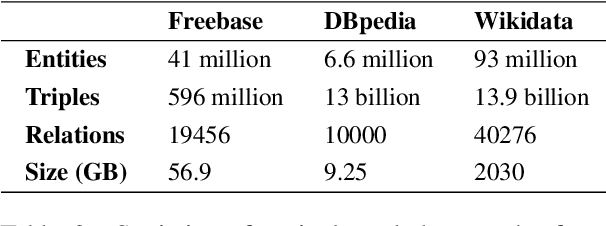
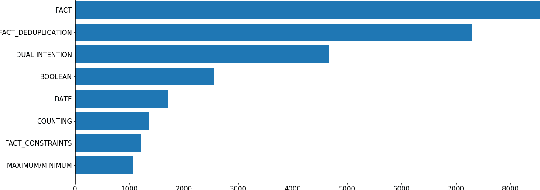
Complex Knowledge Base Question Answering is a popular area of research in the past decade. Recent public datasets have led to encouraging results in this field, but are mostly limited to English and only involve a small number of question types and relations, hindering research in more realistic settings and in languages other than English. In addition, few state-of-the-art KBQA models are trained on Wikidata, one of the most popular real-world knowledge bases. We propose CLC-QuAD, the first large scale complex Chinese semantic parsing dataset over Wikidata to address these challenges. Together with the dataset, we present a text-to-SPARQL baseline model, which can effectively answer multi-type complex questions, such as factual questions, dual intent questions, boolean questions, and counting questions, with Wikidata as the background knowledge. We finally analyze the performance of SOTA KBQA models on this dataset and identify the challenges facing Chinese KBQA.