 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConveyor: Efficient Tool-aware LLM Serving with Tool Partial Execution
May 29, 2024



The complexity of large language model (LLM) serving workloads has substantially increased due to the integration with external tool invocations, such as ChatGPT plugins. In this paper, we identify a new opportunity for efficient LLM serving for requests that trigger tools: tool partial execution alongside LLM decoding. To this end, we design Conveyor, an efficient LLM serving system optimized for handling requests involving external tools. We introduce a novel interface for tool developers to expose partial execution opportunities to the LLM serving system and a request scheduler that facilitates partial tool execution. Our results demonstrate that tool partial execution can improve request completion latency by up to 38.8%.
A Chinese Multi-type Complex Questions Answering Dataset over Wikidata
Nov 11, 2021
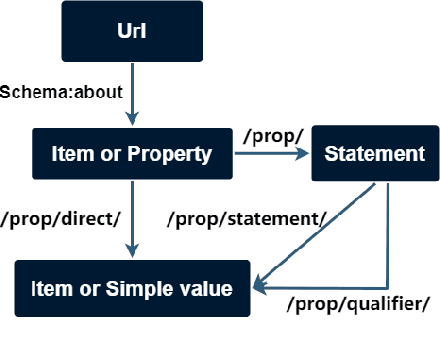
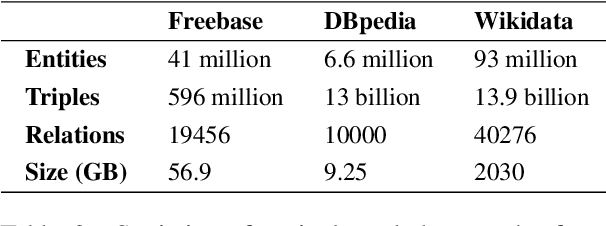
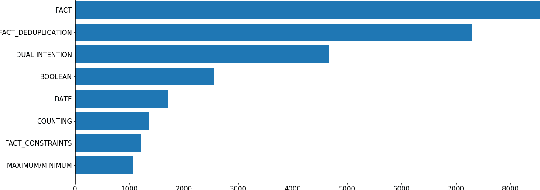
Complex Knowledge Base Question Answering is a popular area of research in the past decade. Recent public datasets have led to encouraging results in this field, but are mostly limited to English and only involve a small number of question types and relations, hindering research in more realistic settings and in languages other than English. In addition, few state-of-the-art KBQA models are trained on Wikidata, one of the most popular real-world knowledge bases. We propose CLC-QuAD, the first large scale complex Chinese semantic parsing dataset over Wikidata to address these challenges. Together with the dataset, we present a text-to-SPARQL baseline model, which can effectively answer multi-type complex questions, such as factual questions, dual intent questions, boolean questions, and counting questions, with Wikidata as the background knowledge. We finally analyze the performance of SOTA KBQA models on this dataset and identify the challenges facing Chinese KBQA.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020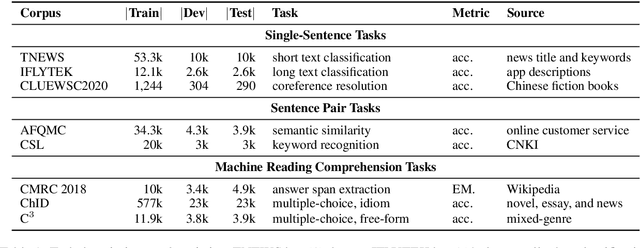
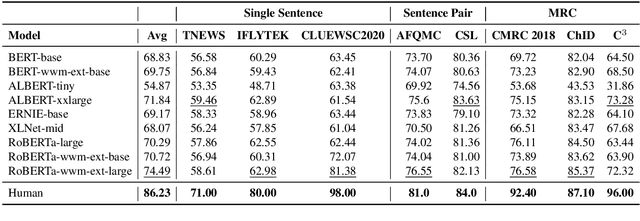
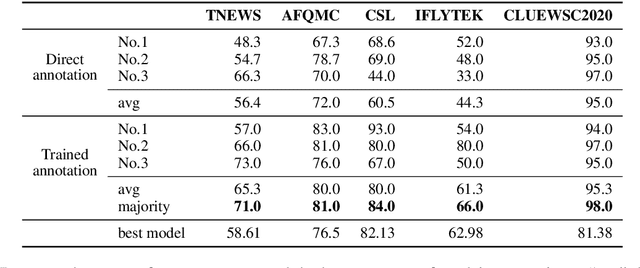
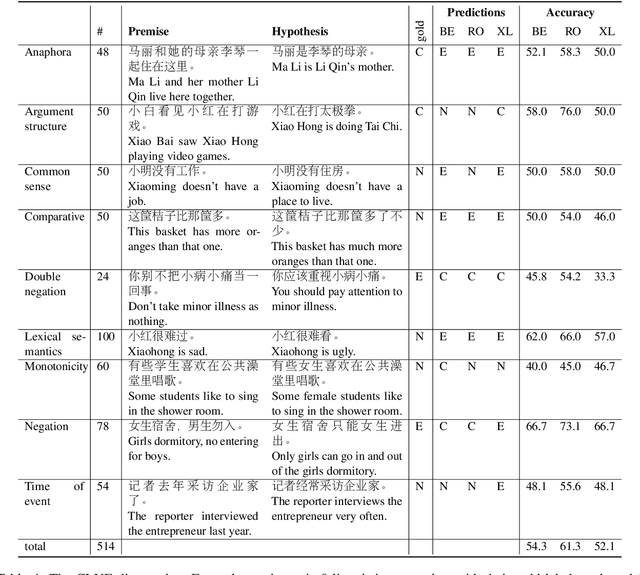
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.