 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
ColorFLUX: A Structure-Color Decoupling Framework for Old Photo Colorization
Mar 30, 2026Old photos preserve invaluable historical memories, making their restoration and colorization highly desirable. While existing restoration models can address some degradation issues like denoising and scratch removal, they often struggle with accurate colorization. This limitation arises from the unique degradation inherent in old photos, such as faded brightness and altered color hues, which are different from modern photo distributions, creating a substantial domain gap during colorization. In this paper, we propose a novel old photo colorization framework based on the generative diffusion model FLUX. Our approach introduces a structure-color decoupling strategy that separates structure preservation from color restoration, enabling accurate colorization of old photos while maintaining structural consistency. We further enhance the model with a progressive Direct Preference Optimization (Pro-DPO) strategy, which allows the model to learn subtle color preferences through coarse-to-fine transitions in color augmentation. Additionally, we address the limitations of text-based prompts by introducing visual semantic prompts, which extract fine-grained semantic information directly from old photos, helping to eliminate the color bias inherent in old photos. Experimental results on both synthetic and real datasets demonstrate that our approach outperforms existing state-of-the-art colorization methods, including closed-source commercial models, producing high-quality and vivid colorization.
Comp-X: On Defining an Interactive Learned Image Compression Paradigm With Expert-driven LLM Agent
Aug 21, 2025We present Comp-X, the first intelligently interactive image compression paradigm empowered by the impressive reasoning capability of large language model (LLM) agent. Notably, commonly used image codecs usually suffer from limited coding modes and rely on manual mode selection by engineers, making them unfriendly for unprofessional users. To overcome this, we advance the evolution of image coding paradigm by introducing three key innovations: (i) multi-functional coding framework, which unifies different coding modes of various objective/requirements, including human-machine perception, variable coding, and spatial bit allocation, into one framework. (ii) interactive coding agent, where we propose an augmented in-context learning method with coding expert feedback to teach the LLM agent how to understand the coding request, mode selection, and the use of the coding tools. (iii) IIC-bench, the first dedicated benchmark comprising diverse user requests and the corresponding annotations from coding experts, which is systematically designed for intelligently interactive image compression evaluation. Extensive experimental results demonstrate that our proposed Comp-X can understand the coding requests efficiently and achieve impressive textual interaction capability. Meanwhile, it can maintain comparable compression performance even with a single coding framework, providing a promising avenue for artificial general intelligence (AGI) in image compression.
LiftVSR: Lifting Image Diffusion to Video Super-Resolution via Hybrid Temporal Modeling with Only 4$\times$RTX 4090s
Jun 10, 2025


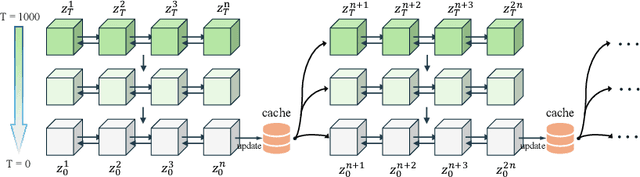
Diffusion models have significantly advanced video super-resolution (VSR) by enhancing perceptual quality, largely through elaborately designed temporal modeling to ensure inter-frame consistency. However, existing methods usually suffer from limited temporal coherence and prohibitively high computational costs (e.g., typically requiring over 8 NVIDIA A100-80G GPUs), especially for long videos. In this work, we propose LiftVSR, an efficient VSR framework that leverages and elevates the image-wise diffusion prior from PixArt-$\alpha$, achieving state-of-the-art results using only 4$\times$RTX 4090 GPUs. To balance long-term consistency and efficiency, we introduce a hybrid temporal modeling mechanism that decomposes temporal learning into two complementary components: (i) Dynamic Temporal Attention (DTA) for fine-grained temporal modeling within short frame segment ($\textit{i.e.}$, low complexity), and (ii) Attention Memory Cache (AMC) for long-term temporal modeling across segments ($\textit{i.e.}$, consistency). Specifically, DTA identifies multiple token flows across frames within multi-head query and key tokens to warp inter-frame contexts in the value tokens. AMC adaptively aggregates historical segment information via a cache unit, ensuring long-term coherence with minimal overhead. To further stabilize the cache interaction during inference, we introduce an asymmetric sampling strategy that mitigates feature mismatches arising from different diffusion sampling steps. Extensive experiments on several typical VSR benchmarks have demonstrated that LiftVSR achieves impressive performance with significantly lower computational costs.
NTIRE 2025 Challenge on Short-form UGC Video Quality Assessment and Enhancement: KwaiSR Dataset and Study
Apr 21, 2025In this work, we build the first benchmark dataset for short-form UGC Image Super-resolution in the wild, termed KwaiSR, intending to advance the research on developing image super-resolution algorithms for short-form UGC platforms. This dataset is collected from the Kwai Platform, which is composed of two parts, i.e., synthetic and wild parts. Among them, the synthetic dataset, including 1,900 image pairs, is produced by simulating the degradation following the distribution of real-world low-quality short-form UGC images, aiming to provide the ground truth for training and objective comparison in the validation/testing. The wild dataset contains low-quality images collected directly from the Kwai Platform, which are filtered using the quality assessment method KVQ from the Kwai Platform. As a result, the KwaiSR dataset contains 1800 synthetic image pairs and 1900 wild images, which are divided into training, validation, and testing parts with a ratio of 8:1:1. Based on the KwaiSR dataset, we organize the NTIRE 2025 challenge on a second short-form UGC Video quality assessment and enhancement, which attracts lots of researchers to develop the algorithm for it. The results of this competition have revealed that our KwaiSR dataset is pretty challenging for existing Image SR methods, which is expected to lead to a new direction in the image super-resolution field. The dataset can be found from https://lixinustc.github.io/NTIRE2025-KVQE-KwaSR-KVQ.github.io/.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Q-Adapt: Adapting LMM for Visual Quality Assessment with Progressive Instruction Tuning
Apr 02, 2025The rapid advancement of Large Multi-modal Foundation Models (LMM) has paved the way for the possible Explainable Image Quality Assessment (EIQA) with instruction tuning from two perspectives: overall quality explanation, and attribute-wise perception answering. However, existing works usually overlooked the conflicts between these two types of perception explanations during joint instruction tuning, leading to insufficient perception understanding. To mitigate this, we propose a new paradigm for perception-oriented instruction tuning, i.e., Q-Adapt, which aims to eliminate the conflicts and achieve the synergy between these two EIQA tasks when adapting LMM, resulting in enhanced multi-faceted explanations of IQA. Particularly, we propose a progressive instruction tuning strategy by dividing the adaption process of LMM for EIQA into two stages, where the first stage empowers the LMM with universal perception knowledge tailored for two tasks using an efficient transfer learning strategy, i.e., LoRA, and the second stage introduces the instruction-adaptive visual prompt tuning to dynamically adapt visual features for the different instructions from two tasks. In this way, our proposed Q-Adapt can achieve a lightweight visual quality evaluator, demonstrating comparable performance and, in some instances, superior results across perceptual-related benchmarks and commonly-used IQA databases. The source code is publicly available at https://github.com/yeppp27/Q-Adapt.
Hybrid Agents for Image Restoration
Mar 13, 2025



Existing Image Restoration (IR) studies typically focus on task-specific or universal modes individually, relying on the mode selection of users and lacking the cooperation between multiple task-specific/universal restoration modes. This leads to insufficient interaction for unprofessional users and limits their restoration capability for complicated real-world applications. In this work, we present HybridAgent, intending to incorporate multiple restoration modes into a unified image restoration model and achieve intelligent and efficient user interaction through our proposed hybrid agents. Concretely, we propose the hybrid rule of fast, slow, and feedback restoration agents. Here, the slow restoration agent optimizes the powerful multimodal large language model (MLLM) with our proposed instruction-tuning dataset to identify degradations within images with ambiguous user prompts and invokes proper restoration tools accordingly. The fast restoration agent is designed based on a lightweight large language model (LLM) via in-context learning to understand the user prompts with simple and clear requirements, which can obviate the unnecessary time/resource costs of MLLM. Moreover, we introduce the mixed distortion removal mode for our HybridAgents, which is crucial but not concerned in previous agent-based works. It can effectively prevent the error propagation of step-by-step image restoration and largely improve the efficiency of the agent system. We validate the effectiveness of HybridAgent with both synthetic and real-world IR tasks.
LossAgent: Towards Any Optimization Objectives for Image Processing with LLM Agents
Dec 05, 2024



We present the first loss agent, dubbed LossAgent, for low-level image processing tasks, e.g., image super-resolution and restoration, intending to achieve any customized optimization objectives of low-level image processing in different practical applications. Notably, not all optimization objectives, such as complex hand-crafted perceptual metrics, text description, and intricate human feedback, can be instantiated with existing low-level losses, e.g., MSE loss. which presents a crucial challenge in optimizing image processing networks in an end-to-end manner. To eliminate this, our LossAgent introduces the powerful large language model (LLM) as the loss agent, where the rich textual understanding of prior knowledge empowers the loss agent with the potential to understand complex optimization objectives, trajectory, and state feedback from external environments in the optimization process of the low-level image processing networks. In particular, we establish the loss repository by incorporating existing loss functions that support the end-to-end optimization for low-level image processing. Then, we design the optimization-oriented prompt engineering for the loss agent to actively and intelligently decide the compositional weights for each loss in the repository at each optimization interaction, thereby achieving the required optimization trajectory for any customized optimization objectives. Extensive experiments on three typical low-level image processing tasks and multiple optimization objectives have shown the effectiveness and applicability of our proposed LossAgent. Code and pre-trained models will be available at https://github.com/lbc12345/LossAgent.