 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Fake: Effective Training Data Synthesis Through Distribution Matching
Oct 16, 2023



Synthetic training data has gained prominence in numerous learning tasks and scenarios, offering advantages such as dataset augmentation, generalization evaluation, and privacy preservation. Despite these benefits, the efficiency of synthetic data generated by current methodologies remains inferior when training advanced deep models exclusively, limiting its practical utility. To address this challenge, we analyze the principles underlying training data synthesis for supervised learning and elucidate a principled theoretical framework from the distribution-matching perspective that explicates the mechanisms governing synthesis efficacy. Through extensive experiments, we demonstrate the effectiveness of our synthetic data across diverse image classification tasks, both as a replacement for and augmentation to real datasets, while also benefits challenging tasks such as out-of-distribution generalization and privacy preservation.
OxfordTVG-HIC: Can Machine Make Humorous Captions from Images?
Jul 21, 2023



This paper presents OxfordTVG-HIC (Humorous Image Captions), a large-scale dataset for humour generation and understanding. Humour is an abstract, subjective, and context-dependent cognitive construct involving several cognitive factors, making it a challenging task to generate and interpret. Hence, humour generation and understanding can serve as a new task for evaluating the ability of deep-learning methods to process abstract and subjective information. Due to the scarcity of data, humour-related generation tasks such as captioning remain under-explored. To address this gap, OxfordTVG-HIC offers approximately 2.9M image-text pairs with humour scores to train a generalizable humour captioning model. Contrary to existing captioning datasets, OxfordTVG-HIC features a wide range of emotional and semantic diversity resulting in out-of-context examples that are particularly conducive to generating humour. Moreover, OxfordTVG-HIC is curated devoid of offensive content. We also show how OxfordTVG-HIC can be leveraged for evaluating the humour of a generated text. Through explainability analysis of the trained models, we identify the visual and linguistic cues influential for evoking humour prediction (and generation). We observe qualitatively that these cues are aligned with the benign violation theory of humour in cognitive psychology.
ReMaX: Relaxing for Better Training on Efficient Panoptic Segmentation
Jun 29, 2023



This paper presents a new mechanism to facilitate the training of mask transformers for efficient panoptic segmentation, democratizing its deployment. We observe that due to its high complexity, the training objective of panoptic segmentation will inevitably lead to much higher false positive penalization. Such unbalanced loss makes the training process of the end-to-end mask-transformer based architectures difficult, especially for efficient models. In this paper, we present ReMaX that adds relaxation to mask predictions and class predictions during training for panoptic segmentation. We demonstrate that via these simple relaxation techniques during training, our model can be consistently improved by a clear margin \textbf{without} any extra computational cost on inference. By combining our method with efficient backbones like MobileNetV3-Small, our method achieves new state-of-the-art results for efficient panoptic segmentation on COCO, ADE20K and Cityscapes. Code and pre-trained checkpoints will be available at \url{https://github.com/google-research/deeplab2}.
LUMix: Improving Mixup by Better Modelling Label Uncertainty
Nov 29, 2022



Modern deep networks can be better generalized when trained with noisy samples and regularization techniques. Mixup and CutMix have been proven to be effective for data augmentation to help avoid overfitting. Previous Mixup-based methods linearly combine images and labels to generate additional training data. However, this is problematic if the object does not occupy the whole image as we demonstrate in Figure 1. Correctly assigning the label weights is hard even for human beings and there is no clear criterion to measure it. To tackle this problem, in this paper, we propose LUMix, which models such uncertainty by adding label perturbation during training. LUMix is simple as it can be implemented in just a few lines of code and can be universally applied to any deep networks \eg CNNs and Vision Transformers, with minimal computational cost. Extensive experiments show that our LUMix can consistently boost the performance for networks with a wide range of diversity and capacity on ImageNet, \eg $+0.7\%$ for a small model DeiT-S and $+0.6\%$ for a large variant XCiT-L. We also demonstrate that LUMix can lead to better robustness when evaluated on ImageNet-O and ImageNet-A. The source code can be found \href{https://github.com/kevin-ssy/LUMix}{here}
Is synthetic data from generative models ready for image recognition?
Oct 14, 2022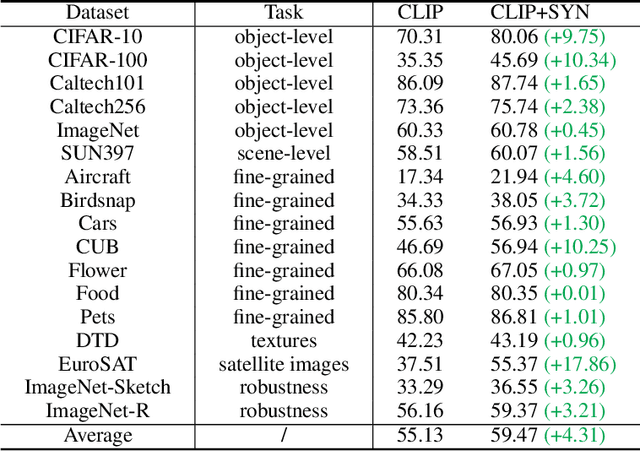
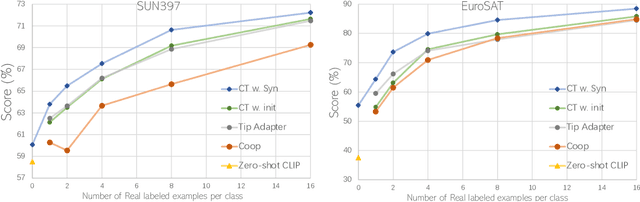
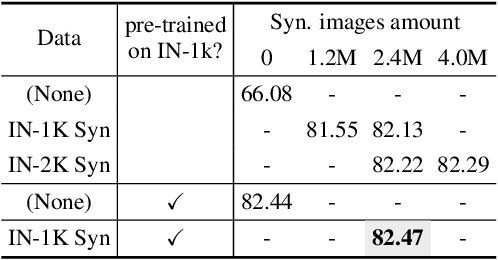

Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images. Though the results are astonishing to human eyes, how applicable these generated images are for recognition tasks remains under-explored. In this work, we extensively study whether and how synthetic images generated from state-of-the-art text-to-image generation models can be used for image recognition tasks, and focus on two perspectives: synthetic data for improving classification models in data-scarce settings (i.e. zero-shot and few-shot), and synthetic data for large-scale model pre-training for transfer learning. We showcase the powerfulness and shortcomings of synthetic data from existing generative models, and propose strategies for better applying synthetic data for recognition tasks. Code: https://github.com/CVMI-Lab/SyntheticData.
Knowledge Distillation as Efficient Pre-training: Faster Convergence, Higher Data-efficiency, and Better Transferability
Mar 26, 2022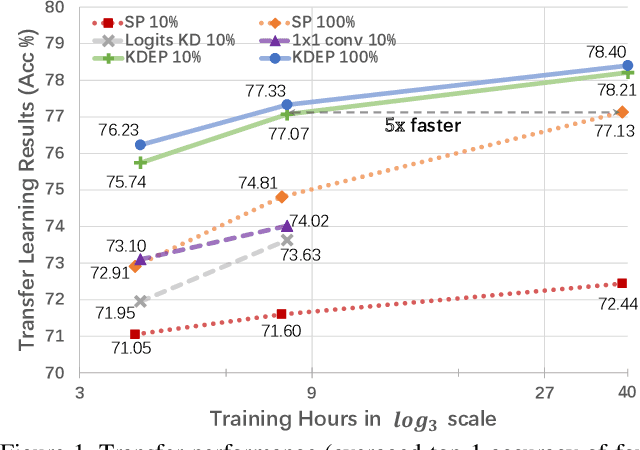
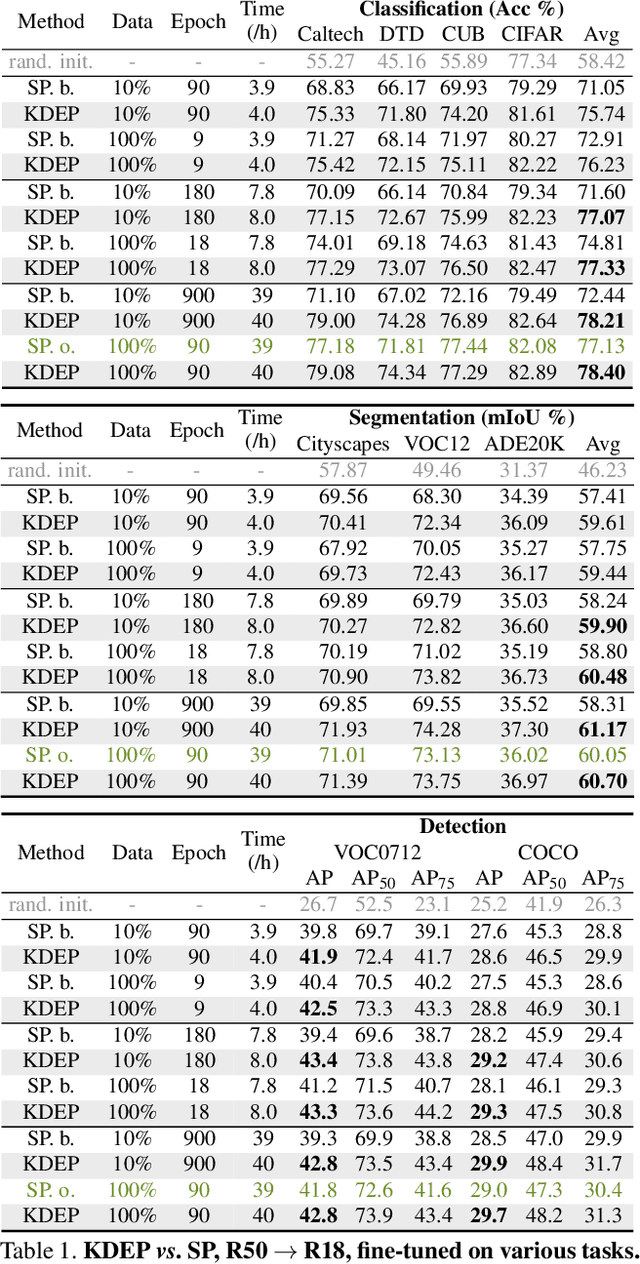
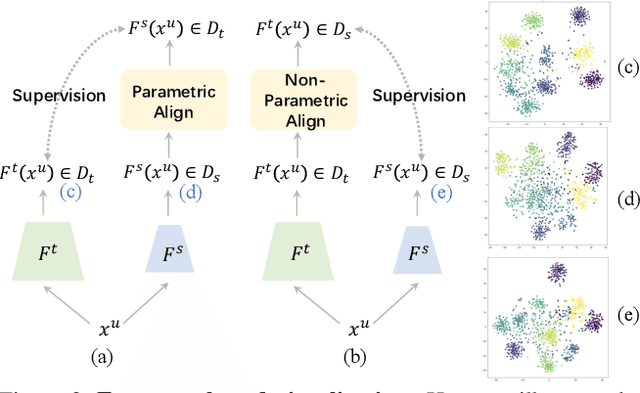
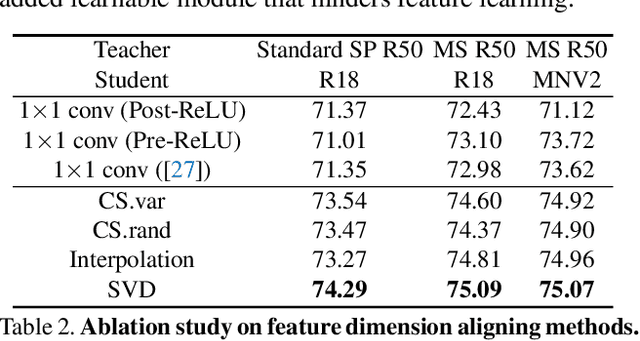
Large-scale pre-training has been proven to be crucial for various computer vision tasks. However, with the increase of pre-training data amount, model architecture amount, and the private/inaccessible data, it is not very efficient or possible to pre-train all the model architectures on large-scale datasets. In this work, we investigate an alternative strategy for pre-training, namely Knowledge Distillation as Efficient Pre-training (KDEP), aiming to efficiently transfer the learned feature representation from existing pre-trained models to new student models for future downstream tasks. We observe that existing Knowledge Distillation (KD) methods are unsuitable towards pre-training since they normally distill the logits that are going to be discarded when transferred to downstream tasks. To resolve this problem, we propose a feature-based KD method with non-parametric feature dimension aligning. Notably, our method performs comparably with supervised pre-training counterparts in 3 downstream tasks and 9 downstream datasets requiring 10x less data and 5x less pre-training time. Code is available at https://github.com/CVMI-Lab/KDEP.
Slot-VPS: Object-centric Representation Learning for Video Panoptic Segmentation
Dec 16, 2021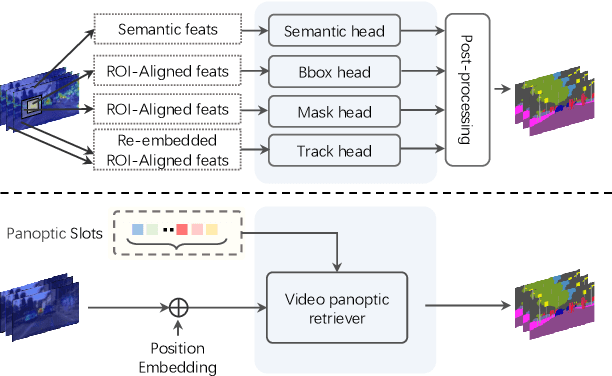
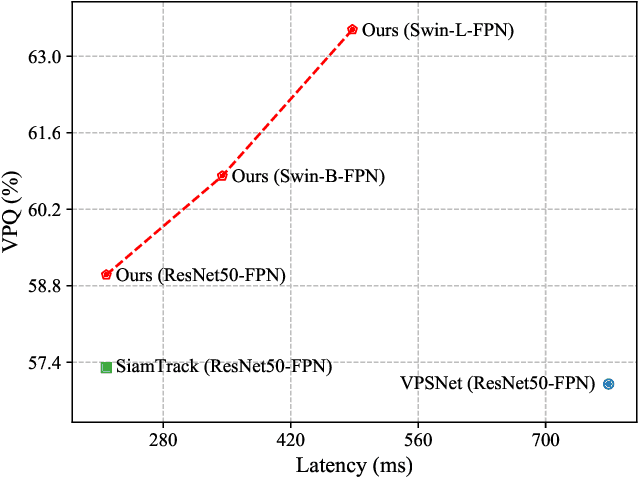
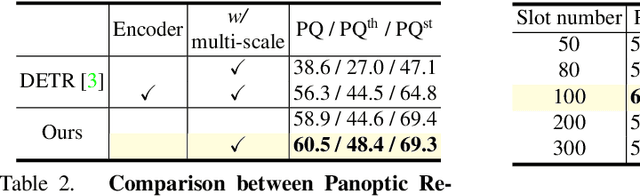
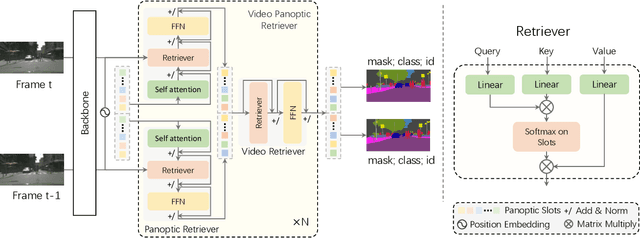
Video Panoptic Segmentation (VPS) aims at assigning a class label to each pixel, uniquely segmenting and identifying all object instances consistently across all frames. Classic solutions usually decompose the VPS task into several sub-tasks and utilize multiple surrogates (e.g. boxes and masks, centres and offsets) to represent objects. However, this divide-and-conquer strategy requires complex post-processing in both spatial and temporal domains and is vulnerable to failures from surrogate tasks. In this paper, inspired by object-centric learning which learns compact and robust object representations, we present Slot-VPS, the first end-to-end framework for this task. We encode all panoptic entities in a video, including both foreground instances and background semantics, with a unified representation called panoptic slots. The coherent spatio-temporal object's information is retrieved and encoded into the panoptic slots by the proposed Video Panoptic Retriever, enabling it to localize, segment, differentiate, and associate objects in a unified manner. Finally, the output panoptic slots can be directly converted into the class, mask, and object ID of panoptic objects in the video. We conduct extensive ablation studies and demonstrate the effectiveness of our approach on two benchmark datasets, Cityscapes-VPS (\textit{val} and test sets) and VIPER (\textit{val} set), achieving new state-of-the-art performance of 63.7, 63.3 and 56.2 VPQ, respectively.
TransMix: Attend to Mix for Vision Transformers
Nov 18, 2021
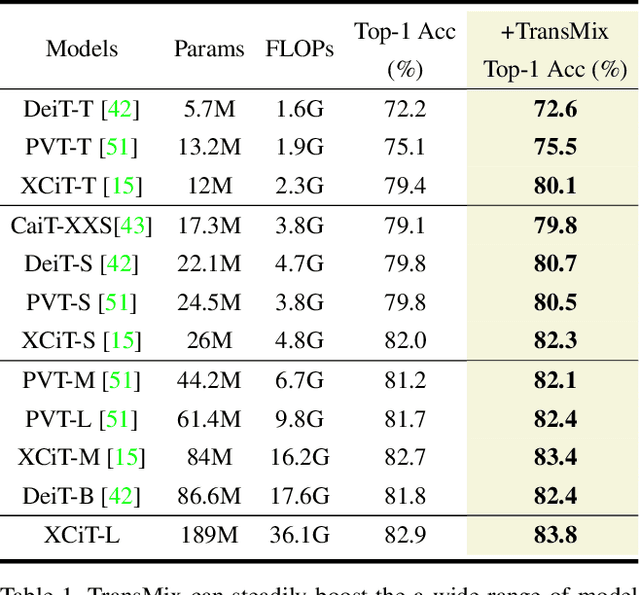
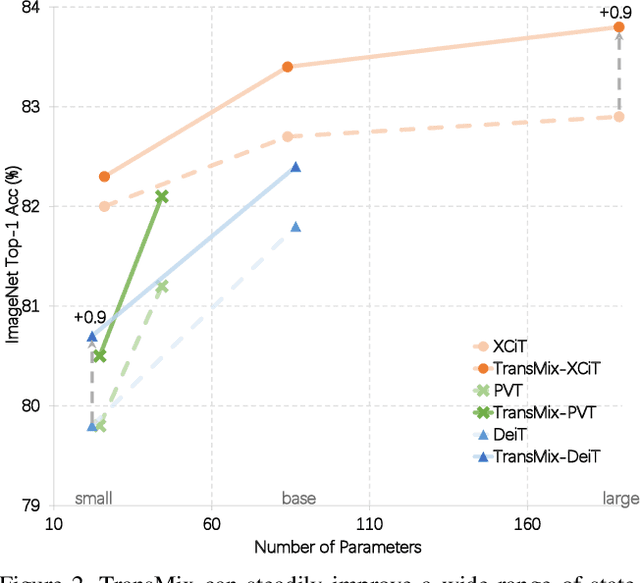

Mixup-based augmentation has been found to be effective for generalizing models during training, especially for Vision Transformers (ViTs) since they can easily overfit. However, previous mixup-based methods have an underlying prior knowledge that the linearly interpolated ratio of targets should be kept the same as the ratio proposed in input interpolation. This may lead to a strange phenomenon that sometimes there is no valid object in the mixed image due to the random process in augmentation but there is still response in the label space. To bridge such gap between the input and label spaces, we propose TransMix, which mixes labels based on the attention maps of Vision Transformers. The confidence of the label will be larger if the corresponding input image is weighted higher by the attention map. TransMix is embarrassingly simple and can be implemented in just a few lines of code without introducing any extra parameters and FLOPs to ViT-based models. Experimental results show that our method can consistently improve various ViT-based models at scales on ImageNet classification. After pre-trained with TransMix on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection and instance segmentation. TransMix also exhibits to be more robust when evaluating on 4 different benchmarks. Code will be made publicly available at https://github.com/Beckschen/TransMix.
Vision Transformer with Progressive Sampling
Aug 03, 2021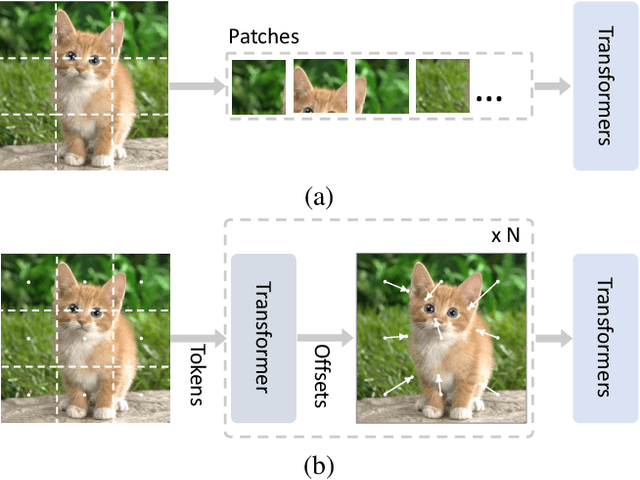
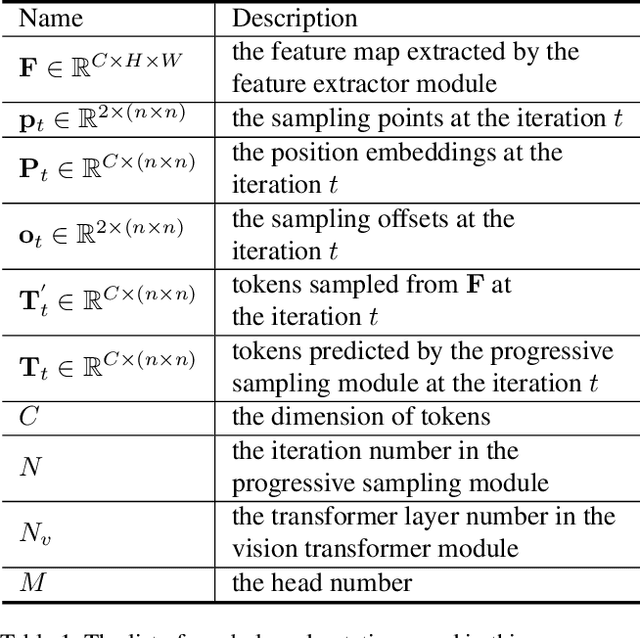
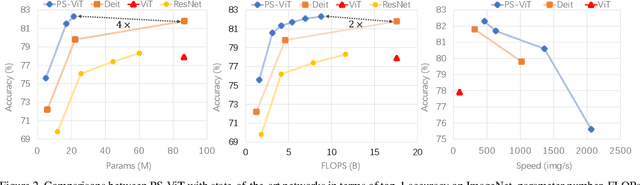
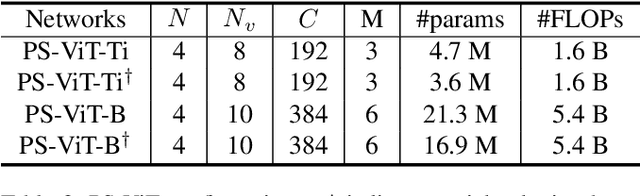
Transformers with powerful global relation modeling abilities have been introduced to fundamental computer vision tasks recently. As a typical example, the Vision Transformer (ViT) directly applies a pure transformer architecture on image classification, by simply splitting images into tokens with a fixed length, and employing transformers to learn relations between these tokens. However, such naive tokenization could destruct object structures, assign grids to uninterested regions such as background, and introduce interference signals. To mitigate the above issues, in this paper, we propose an iterative and progressive sampling strategy to locate discriminative regions. At each iteration, embeddings of the current sampling step are fed into a transformer encoder layer, and a group of sampling offsets is predicted to update the sampling locations for the next step. The progressive sampling is differentiable. When combined with the Vision Transformer, the obtained PS-ViT network can adaptively learn where to look. The proposed PS-ViT is both effective and efficient. When trained from scratch on ImageNet, PS-ViT performs 3.8% higher than the vanilla ViT in terms of top-1 accuracy with about $4\times$ fewer parameters and $10\times$ fewer FLOPs. Code is available at https://github.com/yuexy/PS-ViT.
Learning to Sample the Most Useful Training Patches from Images
Nov 24, 2020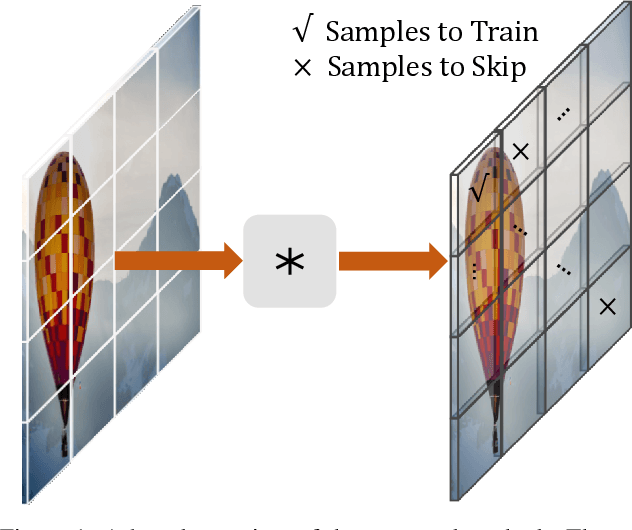


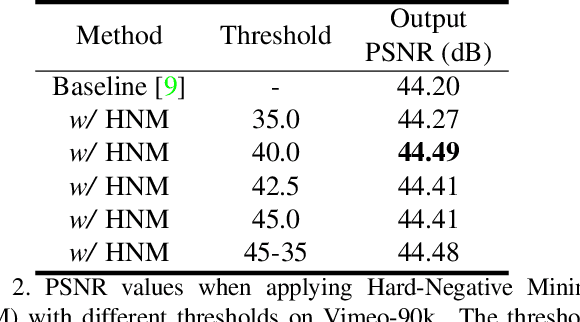
Some image restoration tasks like demosaicing require difficult training samples to learn effective models. Existing methods attempt to address this data training problem by manually collecting a new training dataset that contains adequate hard samples, however, there are still hard and simple areas even within one single image. In this paper, we present a data-driven approach called PatchNet that learns to select the most useful patches from an image to construct a new training set instead of manual or random selection. We show that our simple idea automatically selects informative samples out from a large-scale dataset, leading to a surprising 2.35dB generalisation gain in terms of PSNR. In addition to its remarkable effectiveness, PatchNet is also resource-friendly as it is applied only during training and therefore does not require any additional computational cost during inference.