 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseVoxFormer: Sparse Voxel-based Transformer for Multi-modal 3D Object Detection
Mar 11, 2025



Most previous 3D object detection methods that leverage the multi-modality of LiDAR and cameras utilize the Bird's Eye View (BEV) space for intermediate feature representation. However, this space uses a low x, y-resolution and sacrifices z-axis information to reduce the overall feature resolution, which may result in declined accuracy. To tackle the problem of using low-resolution features, this paper focuses on the sparse nature of LiDAR point cloud data. From our observation, the number of occupied cells in the 3D voxels constructed from a LiDAR data can be even fewer than the number of total cells in the BEV map, despite the voxels' significantly higher resolution. Based on this, we introduce a novel sparse voxel-based transformer network for 3D object detection, dubbed as SparseVoxFormer. Instead of performing BEV feature extraction, we directly leverage sparse voxel features as the input for a transformer-based detector. Moreover, with regard to the camera modality, we introduce an explicit modality fusion approach that involves projecting 3D voxel coordinates onto 2D images and collecting the corresponding image features. Thanks to these components, our approach can leverage geometrically richer multi-modal features while even reducing the computational cost. Beyond the proof-of-concept level, we further focus on facilitating better multi-modal fusion and flexible control over the number of sparse features. Finally, thorough experimental results demonstrate that utilizing a significantly smaller number of sparse features drastically reduces computational costs in a 3D object detector while enhancing both overall and long-range performance.
MapDistill: Boosting Efficient Camera-based HD Map Construction via Camera-LiDAR Fusion Model Distillation
Jul 16, 2024



Online high-definition (HD) map construction is an important and challenging task in autonomous driving. Recently, there has been a growing interest in cost-effective multi-view camera-based methods without relying on other sensors like LiDAR. However, these methods suffer from a lack of explicit depth information, necessitating the use of large models to achieve satisfactory performance. To address this, we employ the Knowledge Distillation (KD) idea for efficient HD map construction for the first time and introduce a novel KD-based approach called MapDistill to transfer knowledge from a high-performance camera-LiDAR fusion model to a lightweight camera-only model. Specifically, we adopt the teacher-student architecture, i.e., a camera-LiDAR fusion model as the teacher and a lightweight camera model as the student, and devise a dual BEV transform module to facilitate cross-modal knowledge distillation while maintaining cost-effective camera-only deployment. Additionally, we present a comprehensive distillation scheme encompassing cross-modal relation distillation, dual-level feature distillation, and map head distillation. This approach alleviates knowledge transfer challenges between modalities, enabling the student model to learn improved feature representations for HD map construction. Experimental results on the challenging nuScenes dataset demonstrate the effectiveness of MapDistill, surpassing existing competitors by over 7.7 mAP or 4.5X speedup.
HIMap: HybrId Representation Learning for End-to-end Vectorized HD Map Construction
Mar 26, 2024



Vectorized High-Definition (HD) map construction requires predictions of the category and point coordinates of map elements (e.g. road boundary, lane divider, pedestrian crossing, etc.). State-of-the-art methods are mainly based on point-level representation learning for regressing accurate point coordinates. However, this pipeline has limitations in obtaining element-level information and handling element-level failures, e.g. erroneous element shape or entanglement between elements. To tackle the above issues, we propose a simple yet effective HybrId framework named HIMap to sufficiently learn and interact both point-level and element-level information. Concretely, we introduce a hybrid representation called HIQuery to represent all map elements, and propose a point-element interactor to interactively extract and encode the hybrid information of elements, e.g. point position and element shape, into the HIQuery. Additionally, we present a point-element consistency constraint to enhance the consistency between the point-level and element-level information. Finally, the output point-element integrated HIQuery can be directly converted into map elements' class, point coordinates, and mask. We conduct extensive experiments and consistently outperform previous methods on both nuScenes and Argoverse2 datasets. Notably, our method achieves $77.8$ mAP on the nuScenes dataset, remarkably superior to previous SOTAs by $8.3$ mAP at least.
BackTrack: Robust template update via Backward Tracking of candidate template
Aug 21, 2023



Variations of target appearance such as deformations, illumination variance, occlusion, etc., are the major challenges of visual object tracking that negatively impact the performance of a tracker. An effective method to tackle these challenges is template update, which updates the template to reflect the change of appearance in the target object during tracking. However, with template updates, inadequate quality of new templates or inappropriate timing of updates may induce a model drift problem, which severely degrades the tracking performance. Here, we propose BackTrack, a robust and reliable method to quantify the confidence of the candidate template by backward tracking it on the past frames. Based on the confidence score of candidates from BackTrack, we can update the template with a reliable candidate at the right time while rejecting unreliable candidates. BackTrack is a generic template update scheme and is applicable to any template-based trackers. Extensive experiments on various tracking benchmarks verify the effectiveness of BackTrack over existing template update algorithms, as it achieves SOTA performance on various tracking benchmarks.
Object-Centric Multi-Task Learning for Human Instances
Mar 13, 2023



Human is one of the most essential classes in visual recognition tasks such as detection, segmentation, and pose estimation. Although much effort has been put into individual tasks, multi-task learning for these three tasks has been rarely studied. In this paper, we explore a compact multi-task network architecture that maximally shares the parameters of the multiple tasks via object-centric learning. To this end, we propose a novel query design to encode the human instance information effectively, called human-centric query (HCQ). HCQ enables for the query to learn explicit and structural information of human as well such as keypoints. Besides, we utilize HCQ in prediction heads of the target tasks directly and also interweave HCQ with the deformable attention in Transformer decoders to exploit a well-learned object-centric representation. Experimental results show that the proposed multi-task network achieves comparable accuracy to state-of-the-art task-specific models in human detection, segmentation, and pose estimation task, while it consumes less computational costs.
Slot-VPS: Object-centric Representation Learning for Video Panoptic Segmentation
Dec 16, 2021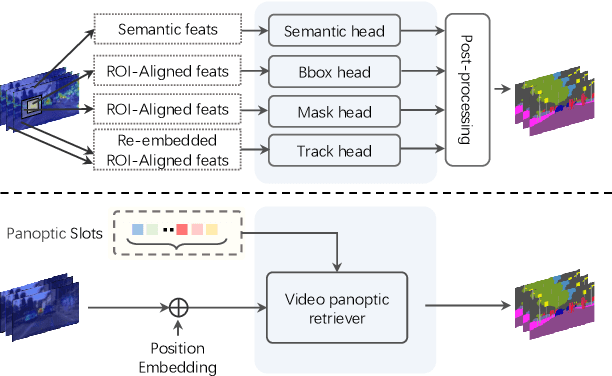
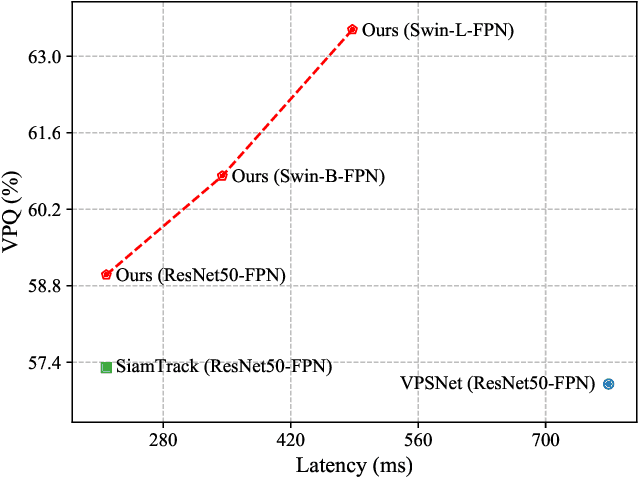
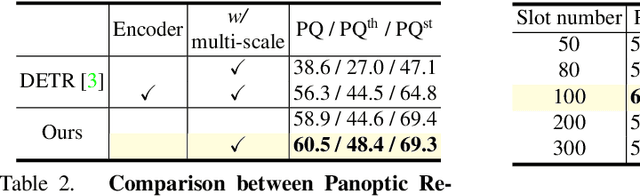
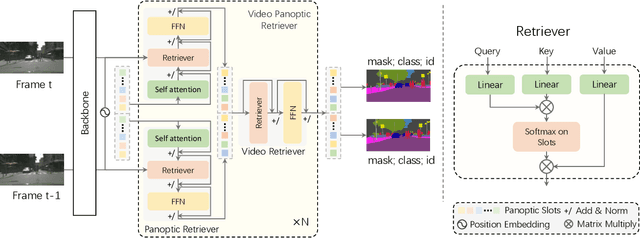
Video Panoptic Segmentation (VPS) aims at assigning a class label to each pixel, uniquely segmenting and identifying all object instances consistently across all frames. Classic solutions usually decompose the VPS task into several sub-tasks and utilize multiple surrogates (e.g. boxes and masks, centres and offsets) to represent objects. However, this divide-and-conquer strategy requires complex post-processing in both spatial and temporal domains and is vulnerable to failures from surrogate tasks. In this paper, inspired by object-centric learning which learns compact and robust object representations, we present Slot-VPS, the first end-to-end framework for this task. We encode all panoptic entities in a video, including both foreground instances and background semantics, with a unified representation called panoptic slots. The coherent spatio-temporal object's information is retrieved and encoded into the panoptic slots by the proposed Video Panoptic Retriever, enabling it to localize, segment, differentiate, and associate objects in a unified manner. Finally, the output panoptic slots can be directly converted into the class, mask, and object ID of panoptic objects in the video. We conduct extensive ablation studies and demonstrate the effectiveness of our approach on two benchmark datasets, Cityscapes-VPS (\textit{val} and test sets) and VIPER (\textit{val} set), achieving new state-of-the-art performance of 63.7, 63.3 and 56.2 VPQ, respectively.
Joint Learning of Generative Translator and Classifier for Visually Similar Classes
Dec 15, 2019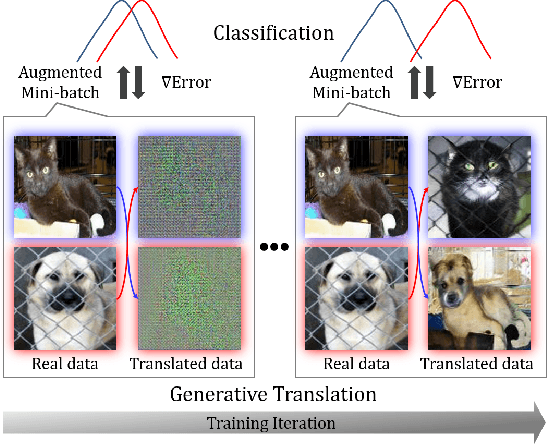
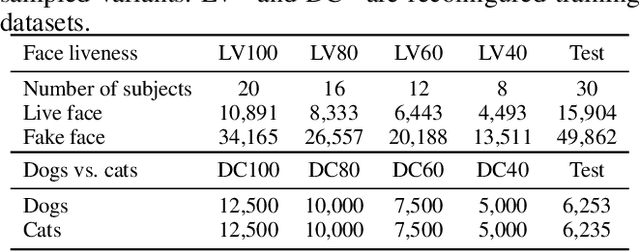
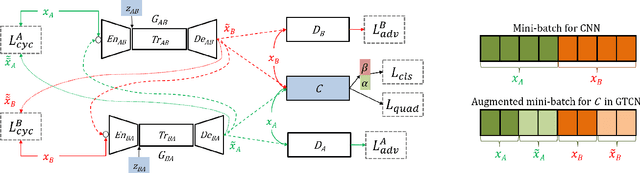
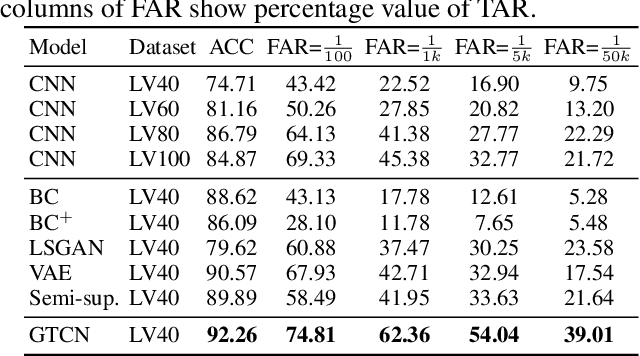
In this paper, we propose a Generative Translation Classification Network (GTCN) for improving visual classification accuracy in settings where classes are visually similar and data is scarce. For this purpose, we propose joint learning to train a classifier and a generative stochastic translation network end-to-end. The translation network is used to perform on-line data augmentation across classes, whereas previous works have mostly involved domain adaptation. To help the model further benefit from this data-augmentation, we introduce an adaptive fade-in loss and a quadruplet loss. We perform experiments on multiple datasets to demonstrate the proposed method's performance in varied settings. Of particular interest, training on 40% of the dataset is enough for our model to surpass the performance of baselines trained on the full dataset. When our architecture is trained on the full dataset, we achieve comparable performance with state-of-the-art methods despite using a light-weight architecture.
Deep generative-contrastive networks for facial expression recognition
Oct 25, 2018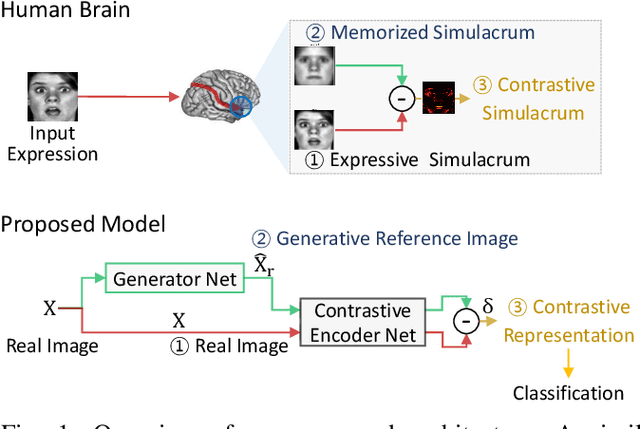
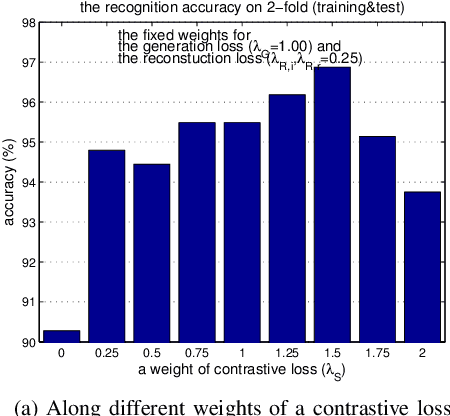
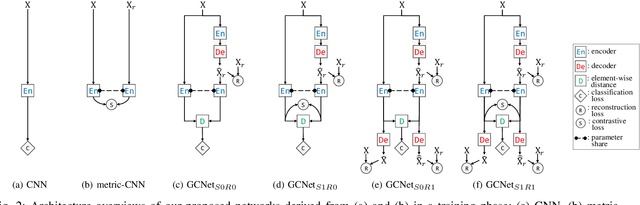
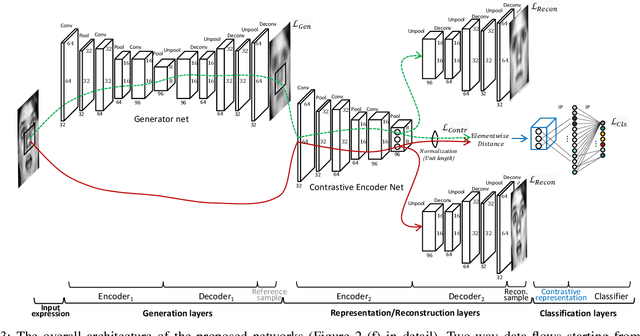
As the expressive depth of an emotional face differs with individuals or expressions, recognizing an expression using a single facial image at a moment is difficult. A relative expression of a query face compared to a reference face might alleviate this difficulty. In this paper, we propose to utilize contrastive representation that embeds a distinctive expressive factor for a discriminative purpose. The contrastive representation is calculated at the embedding layer of deep networks by comparing a given (query) image with the reference image. We attempt to utilize a generative reference image that is estimated based on the given image. Consequently, we deploy deep neural networks that embed a combination of a generative model, a contrastive model, and a discriminative model with an end-to-end training manner. In our proposed networks, we attempt to disentangle a facial expressive factor in two steps including learning of a generator network and a contrastive encoder network. We conducted extensive experiments on publicly available face expression databases (CK+, MMI, Oulu-CASIA, and in-the-wild databases) that have been widely adopted in the recent literatures. The proposed method outperforms the known state-of-the art methods in terms of the recognition accuracy.