 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoFinder: Online Lesion Retrieval for Explainable Colorectal Polyp Diagnosis Leveraging Latent Scene Representations
Jul 23, 2025Colorectal cancer (CRC) remains a leading cause of cancer-related mortality, underscoring the importance of timely polyp detection and diagnosis. While deep learning models have improved optical-assisted diagnostics, they often demand extensive labeled datasets and yield "black-box" outputs with limited interpretability. In this paper, we propose EndoFinder, an online polyp retrieval framework that leverages multi-view scene representations for explainable and scalable CRC diagnosis. First, we develop a Polyp-aware Image Encoder by combining contrastive learning and a reconstruction task, guided by polyp segmentation masks. This self-supervised approach captures robust features without relying on large-scale annotated data. Next, we treat each polyp as a three-dimensional "scene" and introduce a Scene Representation Transformer, which fuses multiple views of the polyp into a single latent representation. By discretizing this representation through a hashing layer, EndoFinder enables real-time retrieval from a compiled database of historical polyp cases, where diagnostic information serves as interpretable references for new queries. We evaluate EndoFinder on both public and newly collected polyp datasets for re-identification and pathology classification. Results show that EndoFinder outperforms existing methods in accuracy while providing transparent, retrieval-based insights for clinical decision-making. By contributing a novel dataset and a scalable, explainable framework, our work addresses key challenges in polyp diagnosis and offers a promising direction for more efficient AI-driven colonoscopy workflows. The source code is available at https://github.com/ku262/EndoFinder-Scene.
MISCGrasp: Leveraging Multiple Integrated Scales and Contrastive Learning for Enhanced Volumetric Grasping
Jul 03, 2025Robotic grasping faces challenges in adapting to objects with varying shapes and sizes. In this paper, we introduce MISCGrasp, a volumetric grasping method that integrates multi-scale feature extraction with contrastive feature enhancement for self-adaptive grasping. We propose a query-based interaction between high-level and low-level features through the Insight Transformer, while the Empower Transformer selectively attends to the highest-level features, which synergistically strikes a balance between focusing on fine geometric details and overall geometric structures. Furthermore, MISCGrasp utilizes multi-scale contrastive learning to exploit similarities among positive grasp samples, ensuring consistency across multi-scale features. Extensive experiments in both simulated and real-world environments demonstrate that MISCGrasp outperforms baseline and variant methods in tabletop decluttering tasks. More details are available at https://miscgrasp.github.io/.
SENIOR: Efficient Query Selection and Preference-Guided Exploration in Preference-based Reinforcement Learning
Jun 17, 2025Preference-based Reinforcement Learning (PbRL) methods provide a solution to avoid reward engineering by learning reward models based on human preferences. However, poor feedback- and sample- efficiency still remain the problems that hinder the application of PbRL. In this paper, we present a novel efficient query selection and preference-guided exploration method, called SENIOR, which could select the meaningful and easy-to-comparison behavior segment pairs to improve human feedback-efficiency and accelerate policy learning with the designed preference-guided intrinsic rewards. Our key idea is twofold: (1) We designed a Motion-Distinction-based Selection scheme (MDS). It selects segment pairs with apparent motion and different directions through kernel density estimation of states, which is more task-related and easy for human preference labeling; (2) We proposed a novel preference-guided exploration method (PGE). It encourages the exploration towards the states with high preference and low visits and continuously guides the agent achieving the valuable samples. The synergy between the two mechanisms could significantly accelerate the progress of reward and policy learning. Our experiments show that SENIOR outperforms other five existing methods in both human feedback-efficiency and policy convergence speed on six complex robot manipulation tasks from simulation and four real-worlds.
Restoring Gaussian Blurred Face Images for Deanonymization Attacks
Jun 14, 2025Gaussian blur is widely used to blur human faces in sensitive photos before the photos are posted on the Internet. However, it is unclear to what extent the blurred faces can be restored and used to re-identify the person, especially under a high-blurring setting. In this paper, we explore this question by developing a deblurring method called Revelio. The key intuition is to leverage a generative model's memorization effect and approximate the inverse function of Gaussian blur for face restoration. Compared with existing methods, we design the deblurring process to be identity-preserving. It uses a conditional Diffusion model for preliminary face restoration and then uses an identity retrieval model to retrieve related images to further enhance fidelity. We evaluate Revelio with large public face image datasets and show that it can effectively restore blurred faces, especially under a high-blurring setting. It has a re-identification accuracy of 95.9%, outperforming existing solutions. The result suggests that Gaussian blur should not be used for face anonymization purposes. We also demonstrate the robustness of this method against mismatched Gaussian kernel sizes and functions, and test preliminary countermeasures and adaptive attacks to inspire future work.
SignAligner: Harmonizing Complementary Pose Modalities for Coherent Sign Language Generation
Jun 13, 2025Sign language generation aims to produce diverse sign representations based on spoken language. However, achieving realistic and naturalistic generation remains a significant challenge due to the complexity of sign language, which encompasses intricate hand gestures, facial expressions, and body movements. In this work, we introduce PHOENIX14T+, an extended version of the widely-used RWTH-PHOENIX-Weather 2014T dataset, featuring three new sign representations: Pose, Hamer and Smplerx. We also propose a novel method, SignAligner, for realistic sign language generation, consisting of three stages: text-driven pose modalities co-generation, online collaborative correction of multimodality, and realistic sign video synthesis. First, by incorporating text semantics, we design a joint sign language generator to simultaneously produce posture coordinates, gesture actions, and body movements. The text encoder, based on a Transformer architecture, extracts semantic features, while a cross-modal attention mechanism integrates these features to generate diverse sign language representations, ensuring accurate mapping and controlling the diversity of modal features. Next, online collaborative correction is introduced to refine the generated pose modalities using a dynamic loss weighting strategy and cross-modal attention, facilitating the complementarity of information across modalities, eliminating spatiotemporal conflicts, and ensuring semantic coherence and action consistency. Finally, the corrected pose modalities are fed into a pre-trained video generation network to produce high-fidelity sign language videos. Extensive experiments demonstrate that SignAligner significantly improves both the accuracy and expressiveness of the generated sign videos.
ReCUT: Balancing Reasoning Length and Accuracy in LLMs via Stepwise Trails and Preference Optimization
Jun 12, 2025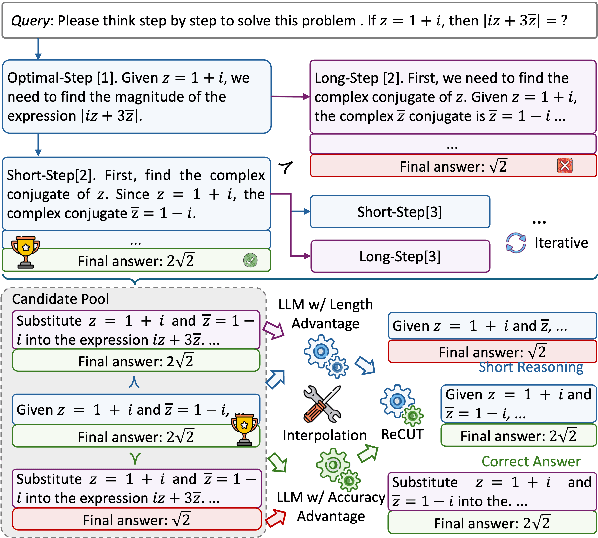
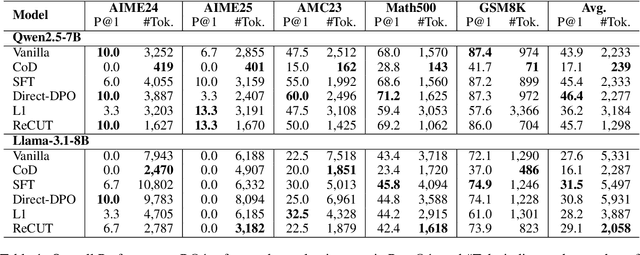
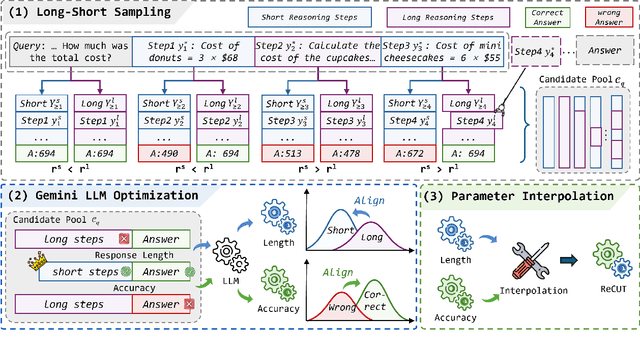
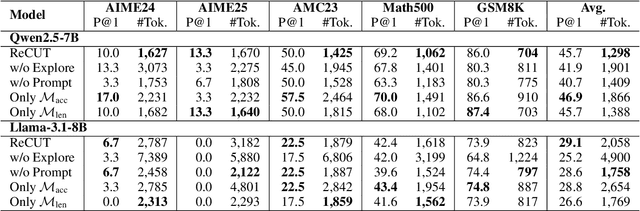
Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of Large Language Models (LLMs). However, these methods often suffer from overthinking, leading to unnecessarily lengthy or redundant reasoning traces. Existing approaches attempt to mitigate this issue through curating multiple reasoning chains for training LLMs, but their effectiveness is often constrained by the quality of the generated data and prone to overfitting. To address the challenge, we propose Reasoning Compression ThroUgh Stepwise Trials (ReCUT), a novel method aimed at balancing the accuracy and length of reasoning trajectory. Specifically, ReCUT employs a stepwise exploration mechanism and a long-short switched sampling strategy, enabling LLMs to incrementally generate diverse reasoning paths. These paths are evaluated and used to construct preference pairs to train two specialized models (Gemini LLMs)-one optimized for reasoning accuracy, the other for shorter reasoning. A final integrated model is obtained by interpolating the parameters of these two models. Experimental results across multiple math reasoning datasets and backbone models demonstrate that ReCUT significantly reduces reasoning lengths by approximately 30-50%, while maintaining or improving reasoning accuracy compared to various baselines. All codes and data will be released via https://github.com/NEUIR/ReCUT.
Mutual-Supervised Learning for Sequential-to-Parallel Code Translation
Jun 11, 2025



The rise of GPU-based high-performance computing (HPC) has driven the widespread adoption of parallel programming models such as CUDA. Yet, the inherent complexity of parallel programming creates a demand for the automated sequential-to-parallel approaches. However, data scarcity poses a significant challenge for machine learning-based sequential-to-parallel code translation. Although recent back-translation methods show promise, they still fail to ensure functional equivalence in the translated code. In this paper, we propose a novel Mutual-Supervised Learning (MSL) framework for sequential-to-parallel code translation to address the functional equivalence issue. MSL consists of two models, a Translator and a Tester. Through an iterative loop consisting of Co-verify and Co-evolve steps, the Translator and the Tester mutually generate data for each other and improve collectively. The Tester generates unit tests to verify and filter functionally equivalent translated code, thereby evolving the Translator, while the Translator generates translated code as augmented input to evolve the Tester. Experimental results demonstrate that MuSL significantly enhances the performance of the base model: when applied to Qwen2.5-Coder, it not only improves Pass@1 by up to 28.91% and boosts Tester performance by 68.90%, but also outperforms the previous state-of-the-art method CodeRosetta by 1.56 and 6.92 in BLEU and CodeBLEU scores, while achieving performance comparable to DeepSeek-R1 and GPT-4.1. Our code is available at https://github.com/kcxain/musl.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Enhanced Trust Region Sequential Convex Optimization for Multi-Drone Thermal Screening Trajectory Planning in Urban Environments
Jun 06, 2025The rapid detection of abnormal body temperatures in urban populations is essential for managing public health risks, especially during outbreaks of infectious diseases. Multi-drone thermal screening systems offer promising solutions for fast, large-scale, and non-intrusive human temperature monitoring. However, trajectory planning for multiple drones in complex urban environments poses significant challenges, including collision avoidance, coverage efficiency, and constrained flight environments. In this study, we propose an enhanced trust region sequential convex optimization (TR-SCO) algorithm for optimal trajectory planning of multiple drones performing thermal screening tasks. Our improved algorithm integrates a refined convex optimization formulation within a trust region framework, effectively balancing trajectory smoothness, obstacle avoidance, altitude constraints, and maximum screening coverage. Simulation results demonstrate that our approach significantly improves trajectory optimality and computational efficiency compared to conventional convex optimization methods. This research provides critical insights and practical contributions toward deploying efficient multi-drone systems for real-time thermal screening in urban areas. For reader who are interested in our research, we release our source code at https://github.com/Cherry0302/Enhanced-TR-SCO.
UAV-UGV Cooperative Trajectory Optimization and Task Allocation for Medical Rescue Tasks in Post-Disaster Environments
Jun 06, 2025



In post-disaster scenarios, rapid and efficient delivery of medical resources is critical and challenging due to severe damage to infrastructure. To provide an optimized solution, we propose a cooperative trajectory optimization and task allocation framework leveraging unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs). This study integrates a Genetic Algorithm (GA) for efficient task allocation among multiple UAVs and UGVs, and employs an informed-RRT* (Rapidly-exploring Random Tree Star) algorithm for collision-free trajectory generation. Further optimization of task sequencing and path efficiency is conducted using Covariance Matrix Adaptation Evolution Strategy (CMA-ES). Simulation experiments conducted in a realistic post-disaster environment demonstrate that our proposed approach significantly improves the overall efficiency of medical rescue operations compared to traditional strategies, showing substantial reductions in total mission completion time and traveled distance. Additionally, the cooperative utilization of UAVs and UGVs effectively balances their complementary advantages, highlighting the system' s scalability and practicality for real-world deployment.