 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReAlign: Optimizing the Visual Document Retriever with Reasoning-Guided Fine-Grained Alignment
Apr 08, 2026Visual document retrieval aims to retrieve a set of document pages relevant to a query from visually rich collections. Existing methods often employ Vision-Language Models (VLMs) to encode queries and visual pages into a shared embedding space, which is then optimized via contrastive training. However, during visual document representation, localized evidence is usually scattered across complex document layouts, making it difficult for retrieval models to capture crucial cues for effective embedding learning. In this paper, we propose Reasoning-Guided Alignment (ReAlign), a method that enhances visual document retrieval by leveraging the reasoning capability of VLMs to provide fine-grained visual document descriptions as supervision signals for training. Specifically, ReAlign employs a superior VLM to identify query-related regions on a page and then generates a query-aware description grounding the cropped visual regions. The retriever is then trained using these region-focused descriptions to align the semantics between queries and visual documents by encouraging the document ranking distribution induced by the region-focused descriptions to match that induced by the original query. Experiments on diverse visually rich document retrieval benchmarks demonstrate that ReAlign consistently improves visual document retrieval performance on both in-domain and out-of-domain datasets, achieving up to 2% relative improvements. Moreover, the advantages of ReAlign generalize across different VLM backbones by guiding models to better focus their attention on critical visual cues for document representation. All code and datasets are available at https://github.com/NEUIR/ReAlign.
UNIKIE-BENCH: Benchmarking Large Multimodal Models for Key Information Extraction in Visual Documents
Feb 03, 2026Key Information Extraction (KIE) from real-world documents remains challenging due to substantial variations in layout structures, visual quality, and task-specific information requirements. Recent Large Multimodal Models (LMMs) have shown promising potential for performing end-to-end KIE directly from document images. To enable a comprehensive and systematic evaluation across realistic and diverse application scenarios, we introduce UNIKIE-BENCH, a unified benchmark designed to rigorously evaluate the KIE capabilities of LMMs. UNIKIE-BENCH consists of two complementary tracks: a constrained-category KIE track with scenario-predefined schemas that reflect practical application needs, and an open-category KIE track that extracts any key information that is explicitly present in the document. Experiments on 15 state-of-the-art LMMs reveal substantial performance degradation under diverse schema definitions, long-tail key fields, and complex layouts, along with pronounced performance disparities across different document types and scenarios. These findings underscore persistent challenges in grounding accuracy and layout-aware reasoning for LMM-based KIE. All codes and datasets are available at https://github.com/NEUIR/UNIKIE-BENCH.
ReCUT: Balancing Reasoning Length and Accuracy in LLMs via Stepwise Trails and Preference Optimization
Jun 12, 2025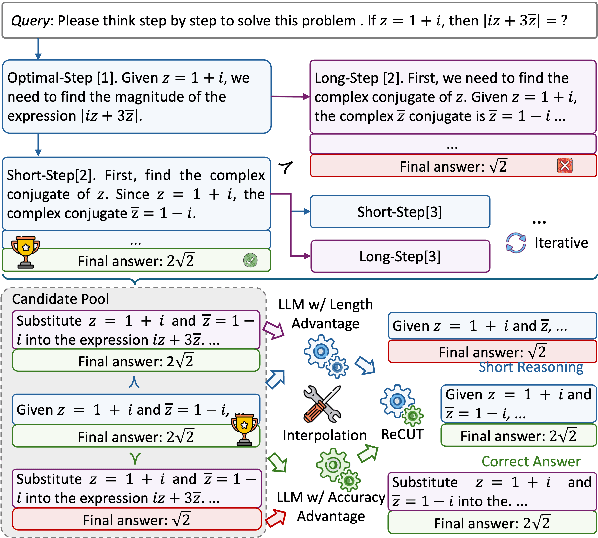
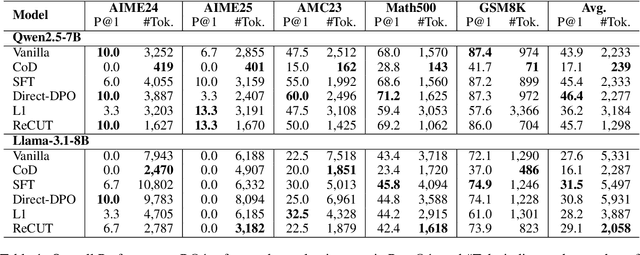
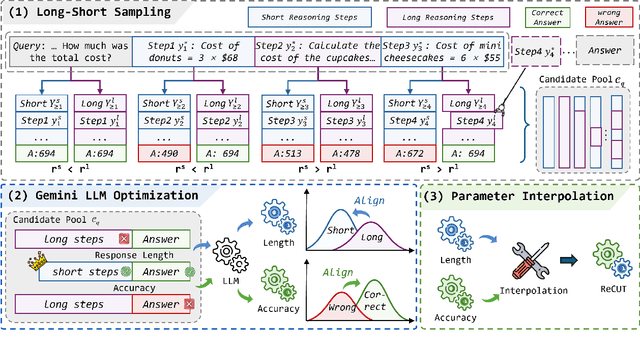
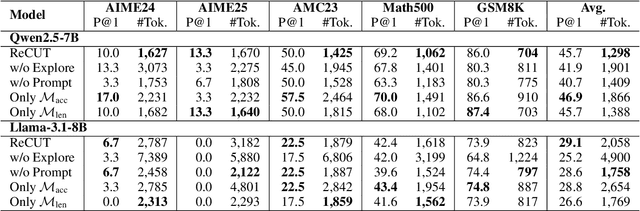
Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of Large Language Models (LLMs). However, these methods often suffer from overthinking, leading to unnecessarily lengthy or redundant reasoning traces. Existing approaches attempt to mitigate this issue through curating multiple reasoning chains for training LLMs, but their effectiveness is often constrained by the quality of the generated data and prone to overfitting. To address the challenge, we propose Reasoning Compression ThroUgh Stepwise Trials (ReCUT), a novel method aimed at balancing the accuracy and length of reasoning trajectory. Specifically, ReCUT employs a stepwise exploration mechanism and a long-short switched sampling strategy, enabling LLMs to incrementally generate diverse reasoning paths. These paths are evaluated and used to construct preference pairs to train two specialized models (Gemini LLMs)-one optimized for reasoning accuracy, the other for shorter reasoning. A final integrated model is obtained by interpolating the parameters of these two models. Experimental results across multiple math reasoning datasets and backbone models demonstrate that ReCUT significantly reduces reasoning lengths by approximately 30-50%, while maintaining or improving reasoning accuracy compared to various baselines. All codes and data will be released via https://github.com/NEUIR/ReCUT.
Learning More Effective Representations for Dense Retrieval through Deliberate Thinking Before Search
Feb 18, 2025



Recent dense retrievers usually thrive on the emergency capabilities of Large Language Models (LLMs), using them to encode queries and documents into an embedding space for retrieval. These LLM-based dense retrievers have shown promising performance across various retrieval scenarios. However, relying on a single embedding to represent documents proves less effective in capturing different perspectives of documents for matching. In this paper, we propose Deliberate Thinking based Dense Retriever (DEBATER), which enhances these LLM-based retrievers by enabling them to learn more effective document representations through a step-by-step thinking process. DEBATER introduces the Chain-of-Deliberation mechanism to iteratively optimize document representations using a continuous chain of thought. To consolidate information from various thinking steps, DEBATER also incorporates the Self Distillation mechanism, which identifies the most informative thinking steps and integrates them into a unified text embedding. Experimental results show that DEBATER significantly outperforms existing methods across several retrieval benchmarks, demonstrating superior accuracy and robustness. All codes are available at https://github.com/OpenBMB/DEBATER.