 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Stereo Image Super-Resolution: Methods and Results
Apr 20, 2022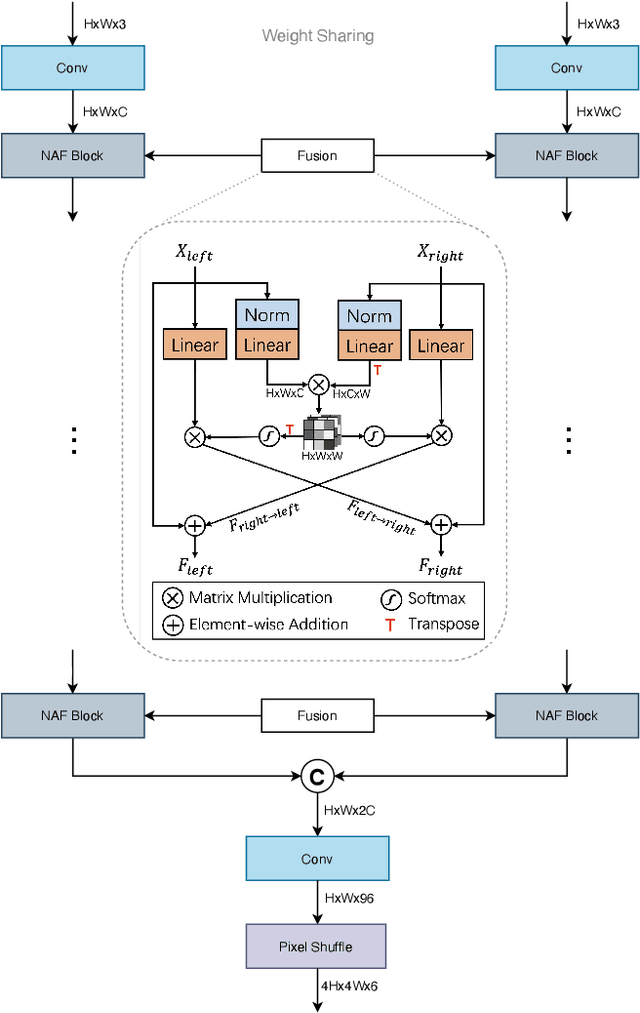
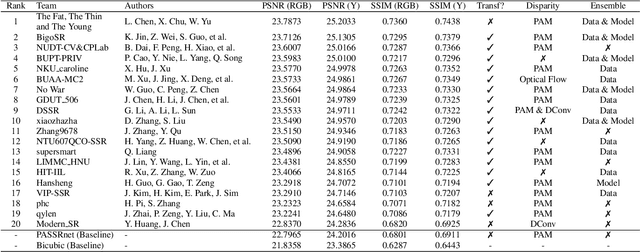
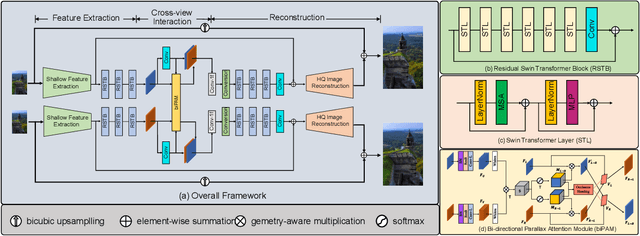
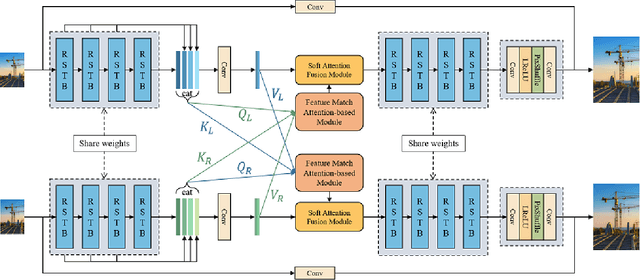
In this paper, we summarize the 1st NTIRE challenge on stereo image super-resolution (restoration of rich details in a pair of low-resolution stereo images) with a focus on new solutions and results. This challenge has 1 track aiming at the stereo image super-resolution problem under a standard bicubic degradation. In total, 238 participants were successfully registered, and 21 teams competed in the final testing phase. Among those participants, 20 teams successfully submitted results with PSNR (RGB) scores better than the baseline. This challenge establishes a new benchmark for stereo image SR.
MFAGAN: A Compression Framework for Memory-Efficient On-Device Super-Resolution GAN
Jul 27, 2021
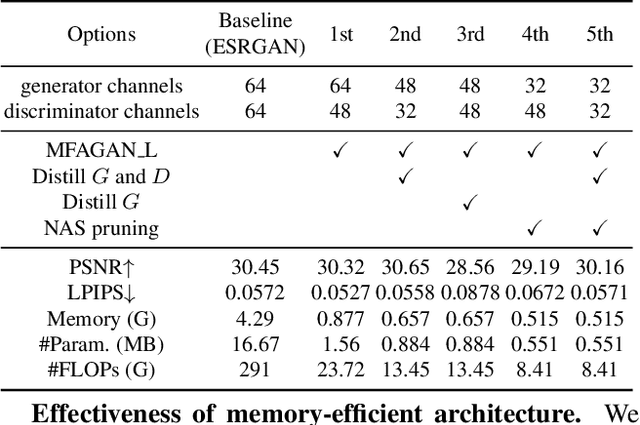
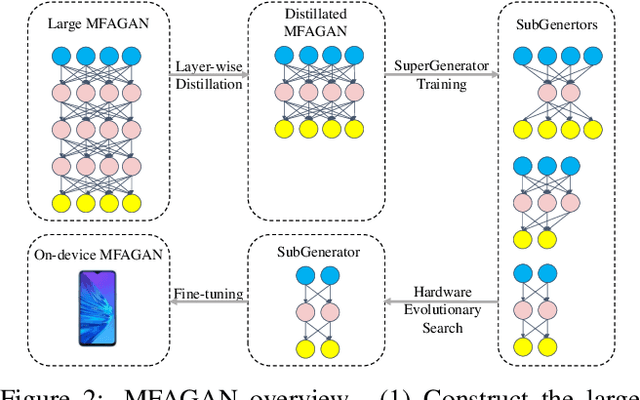

Generative adversarial networks (GANs) have promoted remarkable advances in single-image super-resolution (SR) by recovering photo-realistic images. However, high memory consumption of GAN-based SR (usually generators) causes performance degradation and more energy consumption, hindering the deployment of GAN-based SR into resource-constricted mobile devices. In this paper, we propose a novel compression framework \textbf{M}ulti-scale \textbf{F}eature \textbf{A}ggregation Net based \textbf{GAN} (MFAGAN) for reducing the memory access cost of the generator. First, to overcome the memory explosion of dense connections, we utilize a memory-efficient multi-scale feature aggregation net as the generator. Second, for faster and more stable training, our method introduces the PatchGAN discriminator. Third, to balance the student discriminator and the compressed generator, we distill both the generator and the discriminator. Finally, we perform a hardware-aware neural architecture search (NAS) to find a specialized SubGenerator for the target mobile phone. Benefiting from these improvements, the proposed MFAGAN achieves up to \textbf{8.3}$\times$ memory saving and \textbf{42.9}$\times$ computation reduction, with only minor visual quality degradation, compared with ESRGAN. Empirical studies also show $\sim$\textbf{70} milliseconds latency on Qualcomm Snapdragon 865 chipset.
Improving Facial Attribute Recognition by Group and Graph Learning
May 28, 2021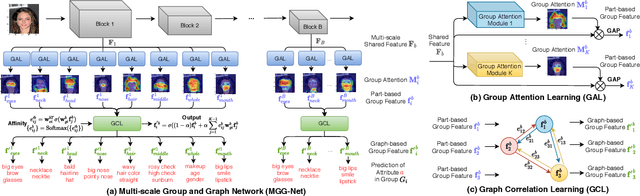
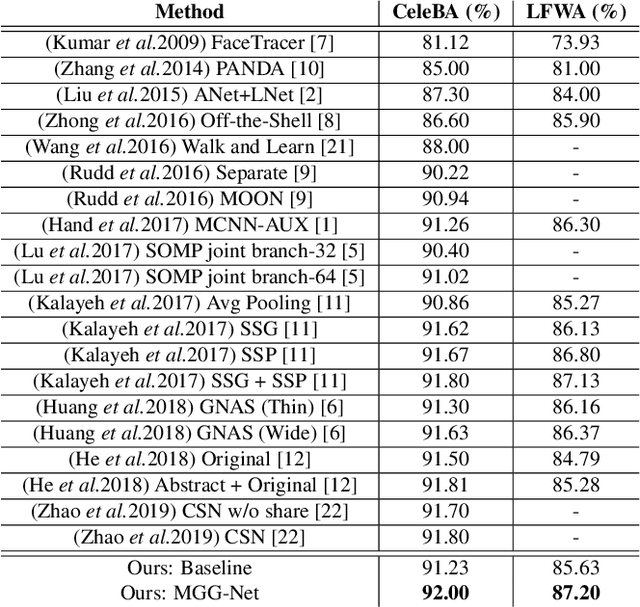
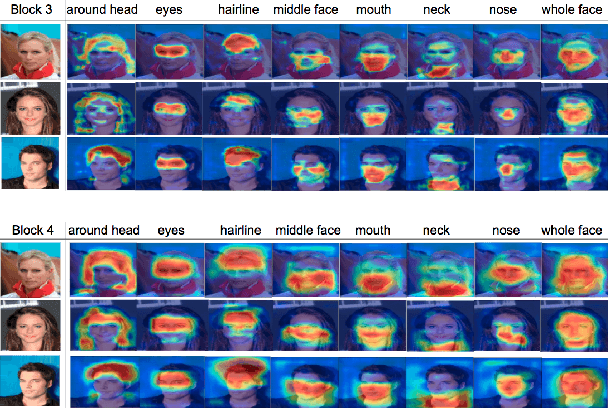
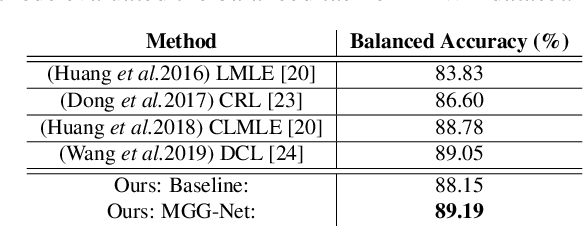
Exploiting the relationships between attributes is a key challenge for improving multiple facial attribute recognition. In this work, we are concerned with two types of correlations that are spatial and non-spatial relationships. For the spatial correlation, we aggregate attributes with spatial similarity into a part-based group and then introduce a Group Attention Learning to generate the group attention and the part-based group feature. On the other hand, to discover the non-spatial relationship, we model a group-based Graph Correlation Learning to explore affinities of predefined part-based groups. We utilize such affinity information to control the communication between all groups and then refine the learned group features. Overall, we propose a unified network called Multi-scale Group and Graph Network. It incorporates these two newly proposed learning strategies and produces coarse-to-fine graph-based group features for improving facial attribute recognition. Comprehensive experiments demonstrate that our approach outperforms the state-of-the-art methods.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

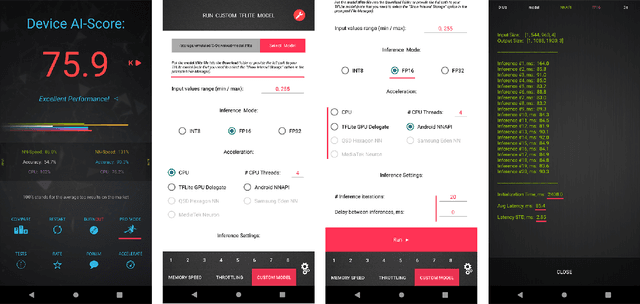
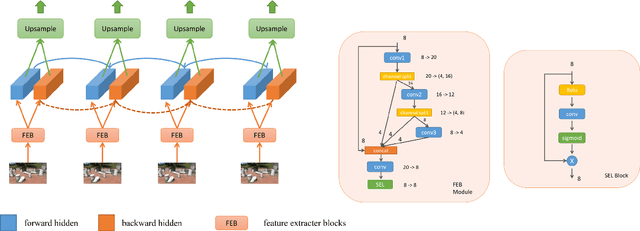
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021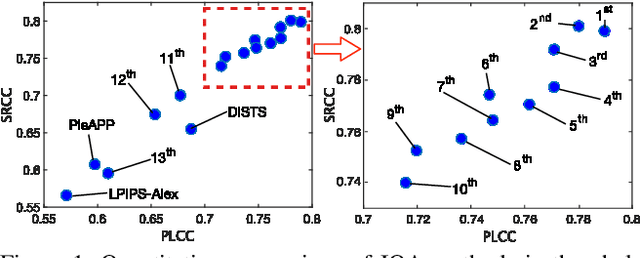
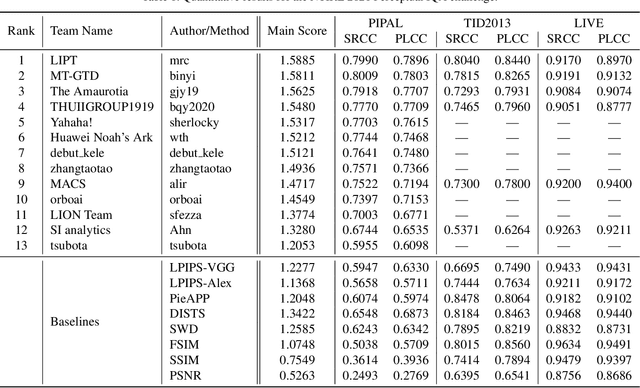

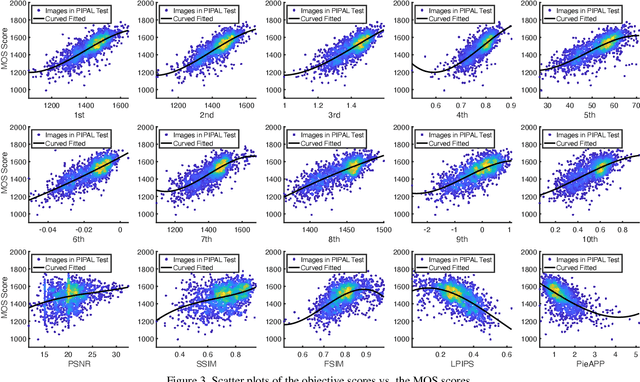
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Flow-based Kernel Prior with Application to Blind Super-Resolution
Mar 29, 2021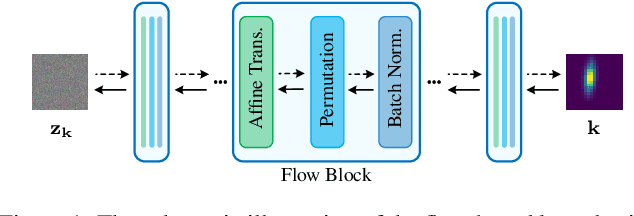

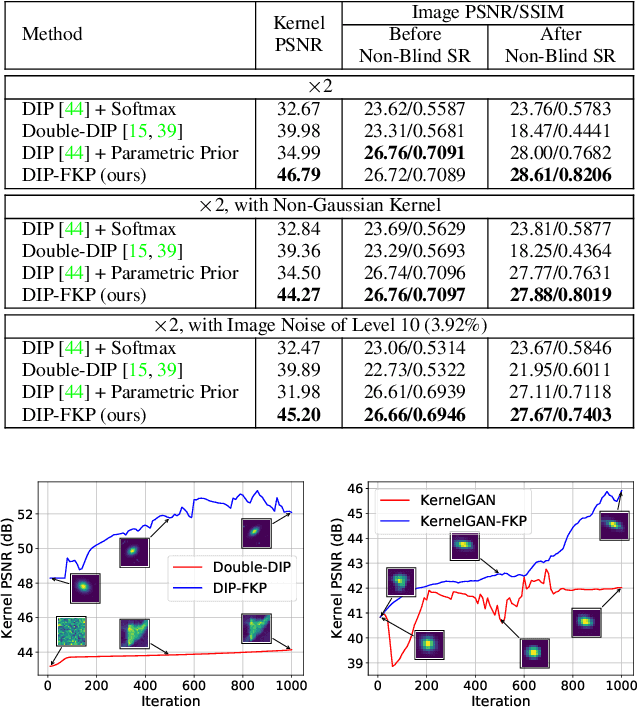
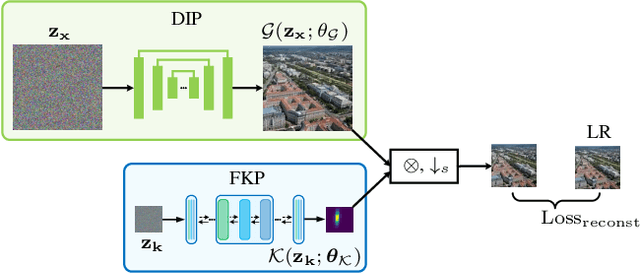
Kernel estimation is generally one of the key problems for blind image super-resolution (SR). Recently, Double-DIP proposes to model the kernel via a network architecture prior, while KernelGAN employs the deep linear network and several regularization losses to constrain the kernel space. However, they fail to fully exploit the general SR kernel assumption that anisotropic Gaussian kernels are sufficient for image SR. To address this issue, this paper proposes a normalizing flow-based kernel prior (FKP) for kernel modeling. By learning an invertible mapping between the anisotropic Gaussian kernel distribution and a tractable latent distribution, FKP can be easily used to replace the kernel modeling modules of Double-DIP and KernelGAN. Specifically, FKP optimizes the kernel in the latent space rather than the network parameter space, which allows it to generate reasonable kernel initialization, traverse the learned kernel manifold and improve the optimization stability. Extensive experiments on synthetic and real-world images demonstrate that the proposed FKP can significantly improve the kernel estimation accuracy with less parameters, runtime and memory usage, leading to state-of-the-art blind SR results.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.
Improving Deep Video Compression by Resolution-adaptive Flow Coding
Sep 13, 2020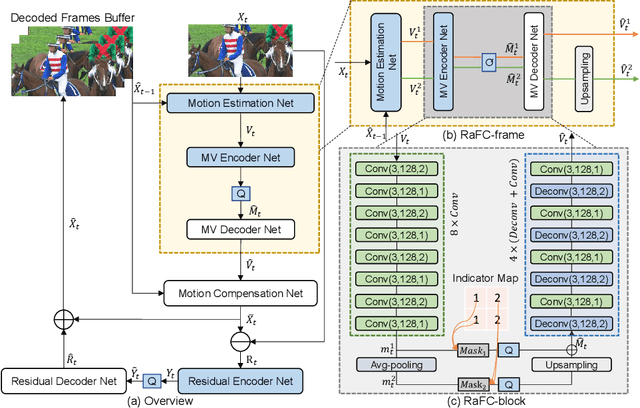
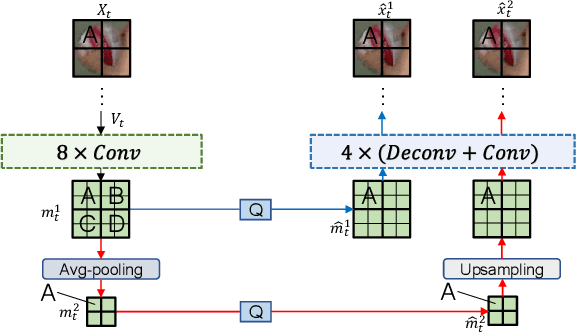

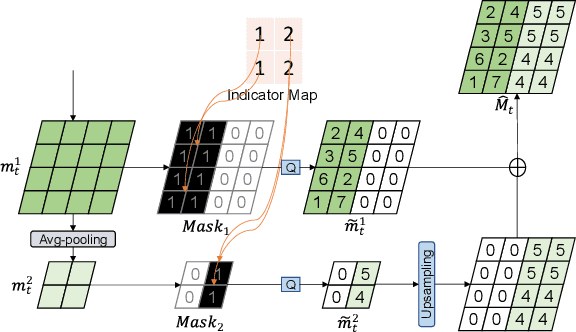
In the learning based video compression approaches, it is an essential issue to compress pixel-level optical flow maps by developing new motion vector (MV) encoders. In this work, we propose a new framework called Resolution-adaptive Flow Coding (RaFC) to effectively compress the flow maps globally and locally, in which we use multi-resolution representations instead of single-resolution representations for both the input flow maps and the output motion features of the MV encoder. To handle complex or simple motion patterns globally, our frame-level scheme RaFC-frame automatically decides the optimal flow map resolution for each video frame. To cope different types of motion patterns locally, our block-level scheme called RaFC-block can also select the optimal resolution for each local block of motion features. In addition, the rate-distortion criterion is applied to both RaFC-frame and RaFC-block and select the optimal motion coding mode for effective flow coding. Comprehensive experiments on four benchmark datasets HEVC, VTL, UVG and MCL-JCV clearly demonstrate the effectiveness of our overall RaFC framework after combing RaFC-frame and RaFC-block for video compression.
Video Super-Resolution with Recurrent Structure-Detail Network
Aug 02, 2020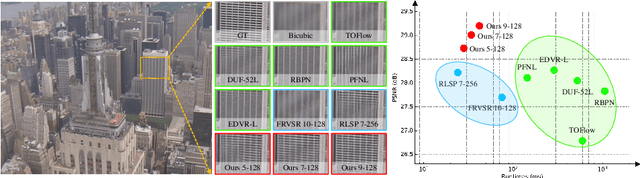

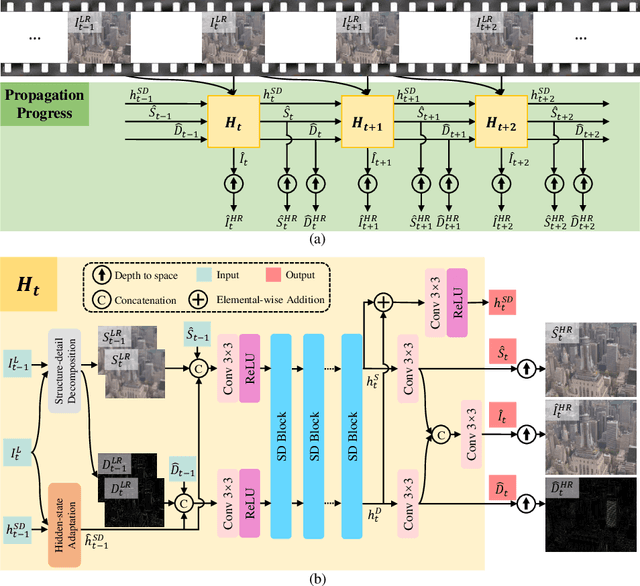

Most video super-resolution methods super-resolve a single reference frame with the help of neighboring frames in a temporal sliding window. They are less efficient compared to the recurrent-based methods. In this work, we propose a novel recurrent video super-resolution method which is both effective and efficient in exploiting previous frames to super-resolve the current frame. It divides the input into structure and detail components which are fed to a recurrent unit composed of several proposed two-stream structure-detail blocks. In addition, a hidden state adaptation module that allows the current frame to selectively use information from hidden state is introduced to enhance its robustness to appearance change and error accumulation. Extensive ablation study validate the effectiveness of the proposed modules. Experiments on several benchmark datasets demonstrate the superior performance of the proposed method compared to state-of-the-art methods on video super-resolution.
You Only Look Yourself: Unsupervised and Untrained Single Image Dehazing Neural Network
Jun 30, 2020
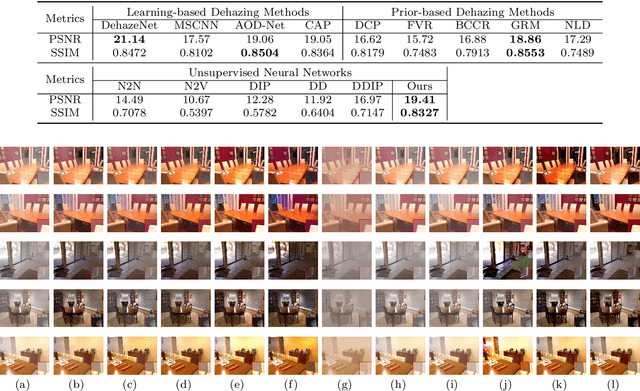
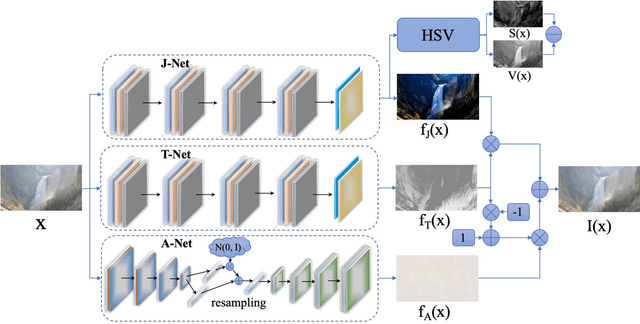
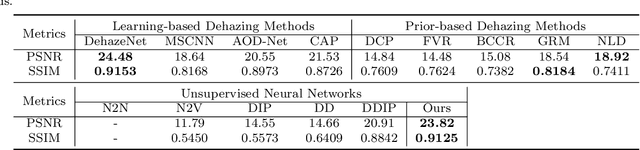
In this paper, we study two challenging and less-touched problems in single image dehazing, namely, how to make deep learning achieve image dehazing without training on the ground-truth clean image (unsupervised) and a image collection (untrained). An unsupervised neural network will avoid the intensive labor collection of hazy-clean image pairs, and an untrained model is a ``real'' single image dehazing approach which could remove haze based on only the observed hazy image itself and no extra images is used. Motivated by the layer disentanglement idea, we propose a novel method, called you only look yourself (\textbf{YOLY}) which could be one of the first unsupervised and untrained neural networks for image dehazing. In brief, YOLY employs three jointly subnetworks to separate the observed hazy image into several latent layers, \textit{i.e.}, scene radiance layer, transmission map layer, and atmospheric light layer. After that, these three layers are further composed to the hazy image in a self-supervised manner. Thanks to the unsupervised and untrained characteristics of YOLY, our method bypasses the conventional training paradigm of deep models on hazy-clean pairs or a large scale dataset, thus avoids the labor-intensive data collection and the domain shift issue. Besides, our method also provides an effective learning-based haze transfer solution thanks to its layer disentanglement mechanism. Extensive experiments show the promising performance of our method in image dehazing compared with 14 methods on four databases.