 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Diffusion-Yielded Score Priors for Image Restoration
Jul 28, 2025Deep image restoration models aim to learn a mapping from degraded image space to natural image space. However, they face several critical challenges: removing degradation, generating realistic details, and ensuring pixel-level consistency. Over time, three major classes of methods have emerged, including MSE-based, GAN-based, and diffusion-based methods. However, they fail to achieve a good balance between restoration quality, fidelity, and speed. We propose a novel method, HYPIR, to address these challenges. Our solution pipeline is straightforward: it involves initializing the image restoration model with a pre-trained diffusion model and then fine-tuning it with adversarial training. This approach does not rely on diffusion loss, iterative sampling, or additional adapters. We theoretically demonstrate that initializing adversarial training from a pre-trained diffusion model positions the initial restoration model very close to the natural image distribution. Consequently, this initialization improves numerical stability, avoids mode collapse, and substantially accelerates the convergence of adversarial training. Moreover, HYPIR inherits the capabilities of diffusion models with rich user control, enabling text-guided restoration and adjustable texture richness. Requiring only a single forward pass, it achieves faster convergence and inference speed than diffusion-based methods. Extensive experiments show that HYPIR outperforms previous state-of-the-art methods, achieving efficient and high-quality image restoration.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation
Sep 08, 2023



Modern displays are capable of rendering video content with high dynamic range (HDR) and wide color gamut (WCG). However, the majority of available resources are still in standard dynamic range (SDR). As a result, there is significant value in transforming existing SDR content into the HDRTV standard. In this paper, we define and analyze the SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Our analysis and observations indicate that a naive end-to-end supervised training pipeline suffers from severe gamut transition errors. To address this issue, we propose a novel three-step solution pipeline called HDRTVNet++, which includes adaptive global color mapping, local enhancement, and highlight refinement. The adaptive global color mapping step uses global statistics as guidance to perform image-adaptive color mapping. A local enhancement network is then deployed to enhance local details. Finally, we combine the two sub-networks above as a generator and achieve highlight consistency through GAN-based joint training. Our method is primarily designed for ultra-high-definition TV content and is therefore effective and lightweight for processing 4K resolution images. We also construct a dataset using HDR videos in the HDR10 standard, named HDRTV1K that contains 1235 and 117 training images and 117 testing images, all in 4K resolution. Besides, we select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Our final results demonstrate state-of-the-art performance both quantitatively and visually. The code, model and dataset are available at https://github.com/xiaom233/HDRTVNet-plus.
Self-Supervised Intensity-Event Stereo Matching
Nov 01, 2022



Event cameras are novel bio-inspired vision sensors that output pixel-level intensity changes in microsecond accuracy with a high dynamic range and low power consumption. Despite these advantages, event cameras cannot be directly applied to computational imaging tasks due to the inability to obtain high-quality intensity and events simultaneously. This paper aims to connect a standalone event camera and a modern intensity camera so that the applications can take advantage of both two sensors. We establish this connection through a multi-modal stereo matching task. We first convert events to a reconstructed image and extend the existing stereo networks to this multi-modality condition. We propose a self-supervised method to train the multi-modal stereo network without using ground truth disparity data. The structure loss calculated on image gradients is used to enable self-supervised learning on such multi-modal data. Exploiting the internal stereo constraint between views with different modalities, we introduce general stereo loss functions, including disparity cross-consistency loss and internal disparity loss, leading to improved performance and robustness compared to existing approaches. The experiments demonstrate the effectiveness of the proposed method, especially the proposed general stereo loss functions, on both synthetic and real datasets. At last, we shed light on employing the aligned events and intensity images in downstream tasks, e.g., video interpolation application.
NTIRE 2022 Challenge on Perceptual Image Quality Assessment
Jun 23, 2022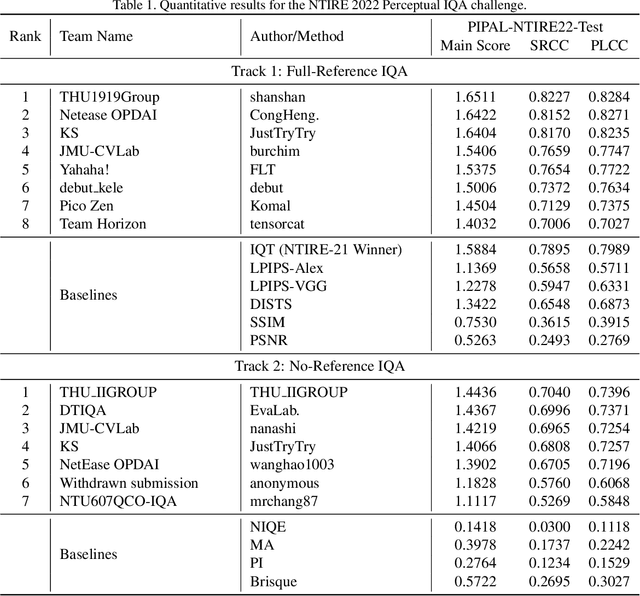
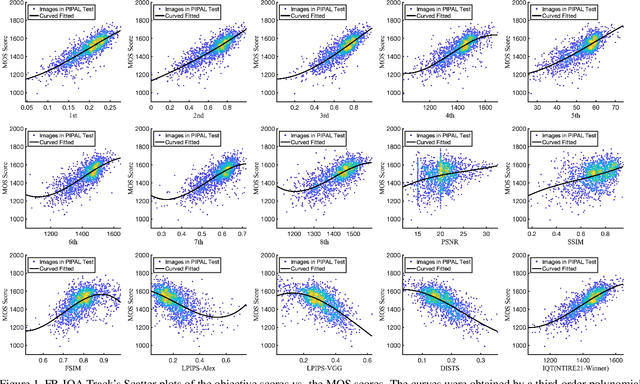
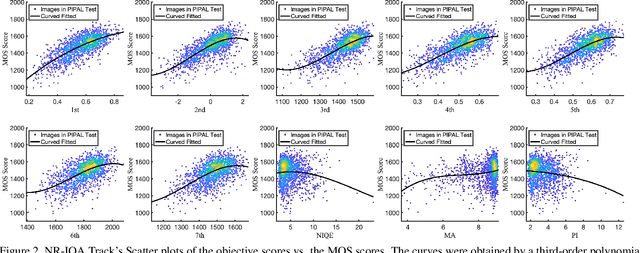
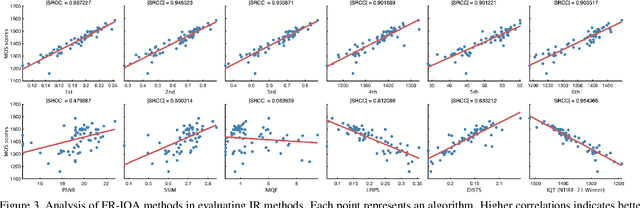
This paper reports on the NTIRE 2022 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2022. This challenge is held to address the emerging challenge of IQA by perceptual image processing algorithms. The output images of these algorithms have completely different characteristics from traditional distortions and are included in the PIPAL dataset used in this challenge. This challenge is divided into two tracks, a full-reference IQA track similar to the previous NTIRE IQA challenge and a new track that focuses on the no-reference IQA methods. The challenge has 192 and 179 registered participants for two tracks. In the final testing stage, 7 and 8 participating teams submitted their models and fact sheets. Almost all of them have achieved better results than existing IQA methods, and the winning method can demonstrate state-of-the-art performance.
A New Journey from SDRTV to HDRTV
Aug 18, 2021Nowadays modern displays are capable to render video content with high dynamic range (HDR) and wide color gamut (WCG). However, most available resources are still in standard dynamic range (SDR). Therefore, there is an urgent demand to transform existing SDR-TV contents into their HDR-TV versions. In this paper, we conduct an analysis of SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Base on the analysis, we propose a three-step solution pipeline including adaptive global color mapping, local enhancement and highlight generation. Moreover, the above analysis inspires us to present a lightweight network that utilizes global statistics as guidance to conduct image-adaptive color mapping. In addition, we construct a dataset using HDR videos in HDR10 standard, named HDRTV1K, and select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Furthermore, our final results achieve state-of-the-art performance in quantitative comparisons and visual quality. The code and dataset are available at https://github.com/chxy95/HDRTVNet.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021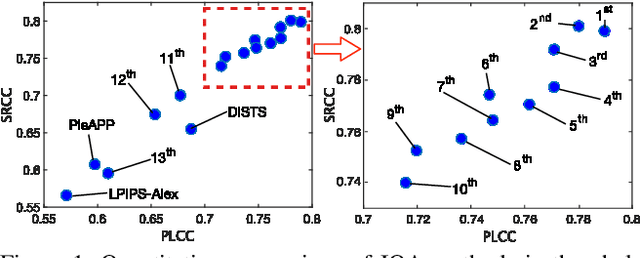
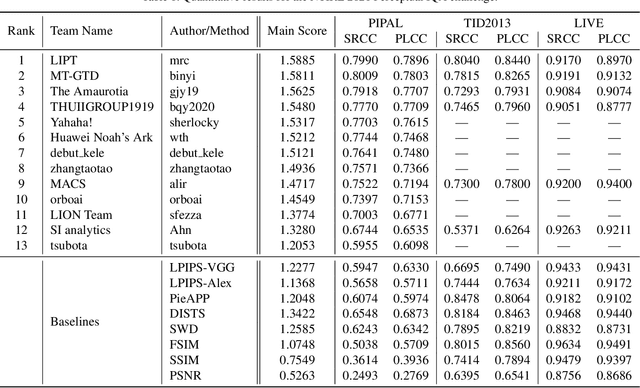

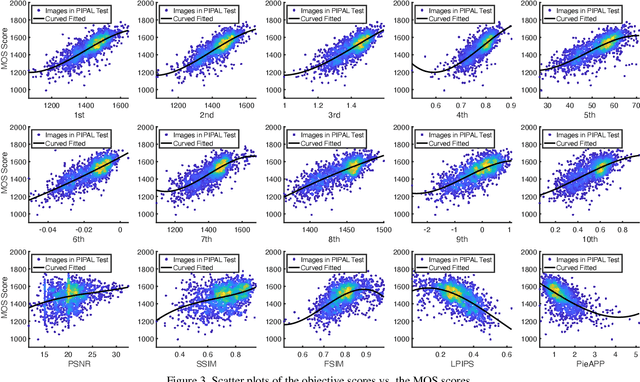
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
EfficientFCN: Holistically-guided Decoding for Semantic Segmentation
Aug 27, 2020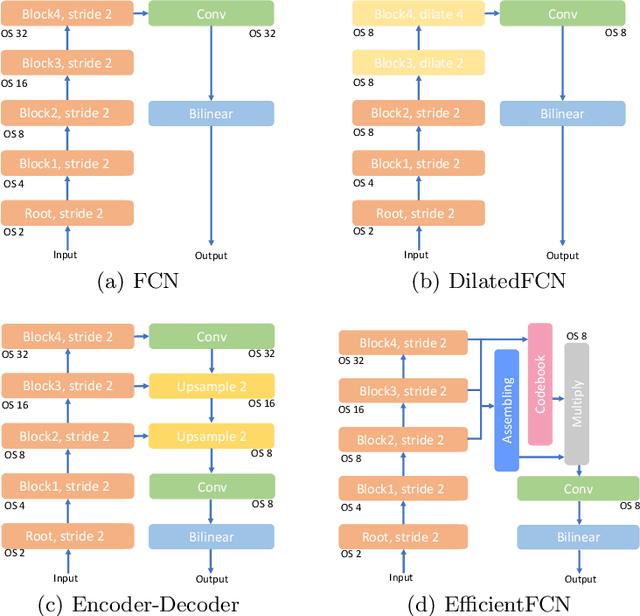
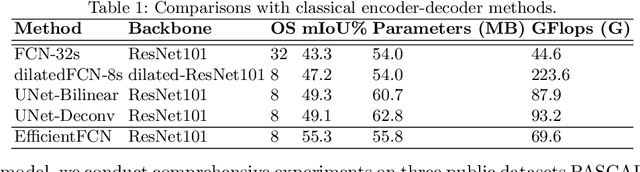
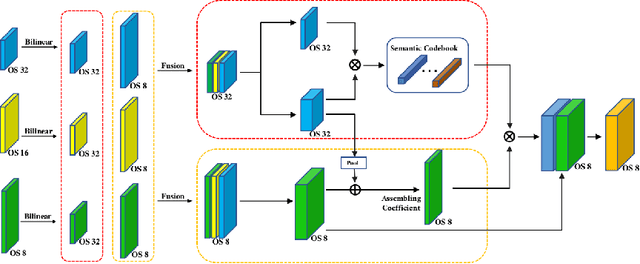

Both performance and efficiency are important to semantic segmentation. State-of-the-art semantic segmentation algorithms are mostly based on dilated Fully Convolutional Networks (dilatedFCN), which adopt dilated convolutions in the backbone networks to extract high-resolution feature maps for achieving high-performance segmentation performance. However, due to many convolution operations are conducted on the high-resolution feature maps, such dilatedFCN-based methods result in large computational complexity and memory consumption. To balance the performance and efficiency, there also exist encoder-decoder structures that gradually recover the spatial information by combining multi-level feature maps from the encoder. However, the performances of existing encoder-decoder methods are far from comparable with the dilatedFCN-based methods. In this paper, we propose the EfficientFCN, whose backbone is a common ImageNet pre-trained network without any dilated convolution. A holistically-guided decoder is introduced to obtain the high-resolution semantic-rich feature maps via the multi-scale features from the encoder. The decoding task is converted to novel codebook generation and codeword assembly task, which takes advantages of the high-level and low-level features from the encoder. Such a framework achieves comparable or even better performance than state-of-the-art methods with only 1/3 of the computational cost. Extensive experiments on PASCAL Context, PASCAL VOC, ADE20K validate the effectiveness of the proposed EfficientFCN.
Learning to Predict Context-adaptive Convolution for Semantic Segmentation
Apr 17, 2020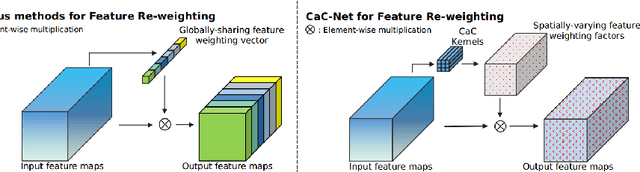
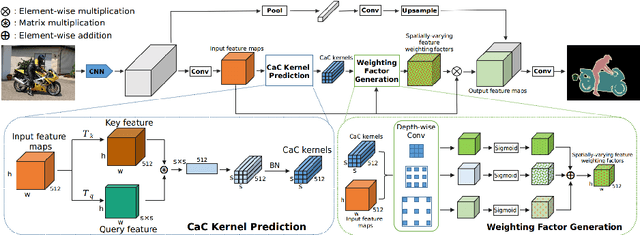
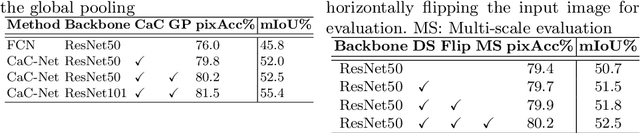

Long-range contextual information is essential for achieving high-performance semantic segmentation. Previous feature re-weighting methods demonstrate that using global context for re-weighting feature channels can effectively improve the accuracy of semantic segmentation. However, the globally-sharing feature re-weighting vector might not be optimal for regions of different classes in the input image. In this paper, we propose a Context-adaptive Convolution Network (CaC-Net) to predict a spatially-varying feature weighting vector for each spatial location of the semantic feature maps. In CaC-Net, a set of context-adaptive convolution kernels are predicted from the global contextual information in a parameter-efficient manner. When used for convolution with the semantic feature maps, the predicted convolutional kernels can generate the spatially-varying feature weighting factors capturing both global and local contextual information. Comprehensive experimental results show that our CaC-Net achieves superior segmentation performance on three public datasets, PASCAL Context, PASCAL VOC 2012 and ADE20K.
Trinity of Pixel Enhancement: a Joint Solution for Demosaicking, Denoising and Super-Resolution
May 07, 2019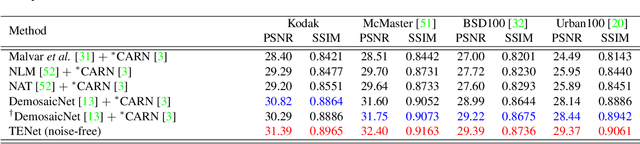

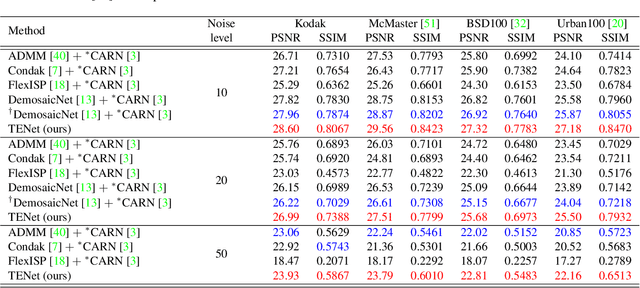
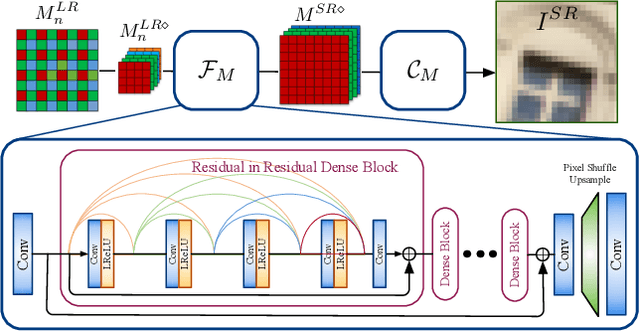
Demosaicing, denoising and super-resolution (SR) are of practical importance in digital image processing and have been studied independently in the passed decades. Despite the recent improvement of learning-based image processing methods in image quality, there lacks enough analysis into their interactions and characteristics under a realistic setting of the mixture problem of demosaicing, denoising and SR. In existing solutions, these tasks are simply combined to obtain a high-resolution image from a low-resolution raw mosaic image, resulting in a performance drop of the final image quality. In this paper, we first rethink the mixture problem from a holistic perspective and then propose the Trinity Enhancement Network (TENet), a specially designed learning-based method for the mixture problem, which adopts a novel image processing pipeline order and a joint learning strategy. In order to obtain the correct color sampling for training, we also contribute a new dataset namely PixelShift200, which consists of high-quality full color sampled real-world images using the advanced pixel shift technique. Experiments demonstrate that our TENet is superior to existing solutions in both quantitative and qualitative perspective. Our experiments also show the necessity of the proposed PixelShift200 dataset.