 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025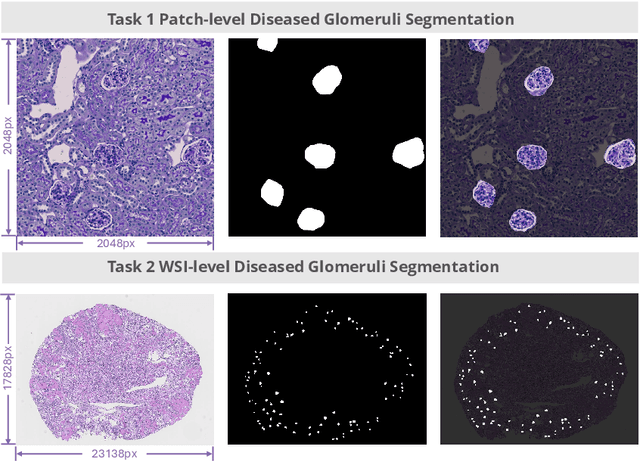

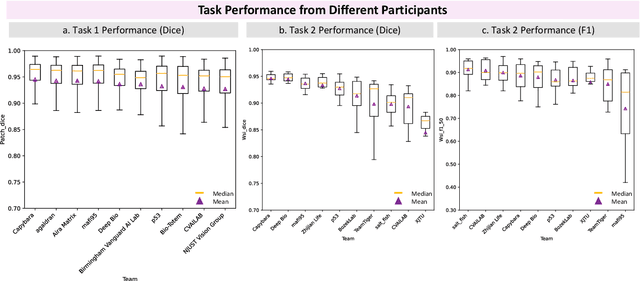

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
One for All: Multi-Domain Joint Training for Point Cloud Based 3D Object Detection
Nov 03, 2024



The current trend in computer vision is to utilize one universal model to address all various tasks. Achieving such a universal model inevitably requires incorporating multi-domain data for joint training to learn across multiple problem scenarios. In point cloud based 3D object detection, however, such multi-domain joint training is highly challenging, because large domain gaps among point clouds from different datasets lead to the severe domain-interference problem. In this paper, we propose \textbf{OneDet3D}, a universal one-for-all model that addresses 3D detection across different domains, including diverse indoor and outdoor scenes, within the \emph{same} framework and only \emph{one} set of parameters. We propose the domain-aware partitioning in scatter and context, guided by a routing mechanism, to address the data interference issue, and further incorporate the text modality for a language-guided classification to unify the multi-dataset label spaces and mitigate the category interference issue. The fully sparse structure and anchor-free head further accommodate point clouds with significant scale disparities. Extensive experiments demonstrate the strong universal ability of OneDet3D to utilize only one trained model for addressing almost all 3D object detection tasks.
Diffusion Model Meets Non-Exemplar Class-Incremental Learning and Beyond
Aug 06, 2024



Non-exemplar class-incremental learning (NECIL) is to resist catastrophic forgetting without saving old class samples. Prior methodologies generally employ simple rules to generate features for replaying, suffering from large distribution gap between replayed features and real ones. To address the aforementioned issue, we propose a simple, yet effective \textbf{Diff}usion-based \textbf{F}eature \textbf{R}eplay (\textbf{DiffFR}) method for NECIL. First, to alleviate the limited representational capacity caused by fixing the feature extractor, we employ Siamese-based self-supervised learning for initial generalizable features. Second, we devise diffusion models to generate class-representative features highly similar to real features, which provides an effective way for exemplar-free knowledge memorization. Third, we introduce prototype calibration to direct the diffusion model's focus towards learning the distribution shapes of features, rather than the entire distribution. Extensive experiments on public datasets demonstrate significant performance gains of our DiffFR, outperforming the state-of-the-art NECIL methods by 3.0\% in average. The code will be made publicly available soon.
Dynamic Object Queries for Transformer-based Incremental Object Detection
Jul 31, 2024



Incremental object detection (IOD) aims to sequentially learn new classes, while maintaining the capability to locate and identify old ones. As the training data arrives with annotations only with new classes, IOD suffers from catastrophic forgetting. Prior methodologies mainly tackle the forgetting issue through knowledge distillation and exemplar replay, ignoring the conflict between limited model capacity and increasing knowledge. In this paper, we explore \textit{dynamic object queries} for incremental object detection built on Transformer architecture. We propose the \textbf{Dy}namic object \textbf{Q}uery-based \textbf{DE}tection \textbf{TR}ansformer (DyQ-DETR), which incrementally expands the model representation ability to achieve stability-plasticity tradeoff. First, a new set of learnable object queries are fed into the decoder to represent new classes. These new object queries are aggregated with those from previous phases to adapt both old and new knowledge well. Second, we propose the isolated bipartite matching for object queries in different phases, based on disentangled self-attention. The interaction among the object queries at different phases is eliminated to reduce inter-class confusion. Thanks to the separate supervision and computation over object queries, we further present the risk-balanced partial calibration for effective exemplar replay. Extensive experiments demonstrate that DyQ-DETR significantly surpasses the state-of-the-art methods, with limited parameter overhead. Code will be made publicly available.
Map Optical Properties to Subwavelength Structures Directly via a Diffusion Model
Apr 09, 2024



Subwavelength photonic structures and metamaterials provide revolutionary approaches for controlling light. The inverse design methods proposed for these subwavelength structures are vital to the development of new photonic devices. However, most of the existing inverse design methods cannot realize direct mapping from optical properties to photonic structures but instead rely on forward simulation methods to perform iterative optimization. In this work, we exploit the powerful generative abilities of artificial intelligence (AI) and propose a practical inverse design method based on latent diffusion models. Our method maps directly the optical properties to structures without the requirement of forward simulation and iterative optimization. Here, the given optical properties can work as "prompts" and guide the constructed model to correctly "draw" the required photonic structures. Experiments show that our direct mapping-based inverse design method can generate subwavelength photonic structures at high fidelity while following the given optical properties. This may change the method used for optical design and greatly accelerate the research on new photonic devices.
OV-Uni3DETR: Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
Mar 28, 2024



In the current state of 3D object detection research, the severe scarcity of annotated 3D data, substantial disparities across different data modalities, and the absence of a unified architecture, have impeded the progress towards the goal of universality. In this paper, we propose \textbf{OV-Uni3DETR}, a unified open-vocabulary 3D detector via cycle-modality propagation. Compared with existing 3D detectors, OV-Uni3DETR offers distinct advantages: 1) Open-vocabulary 3D detection: During training, it leverages various accessible data, especially extensive 2D detection images, to boost training diversity. During inference, it can detect both seen and unseen classes. 2) Modality unifying: It seamlessly accommodates input data from any given modality, effectively addressing scenarios involving disparate modalities or missing sensor information, thereby supporting test-time modality switching. 3) Scene unifying: It provides a unified multi-modal model architecture for diverse scenes collected by distinct sensors. Specifically, we propose the cycle-modality propagation, aimed at propagating knowledge bridging 2D and 3D modalities, to support the aforementioned functionalities. 2D semantic knowledge from large-vocabulary learning guides novel class discovery in the 3D domain, and 3D geometric knowledge provides localization supervision for 2D detection images. OV-Uni3DETR achieves the state-of-the-art performance on various scenarios, surpassing existing methods by more than 6\% on average. Its performance using only RGB images is on par with or even surpasses that of previous point cloud based methods. Code and pre-trained models will be released later.
Joint Learning for Scattered Point Cloud Understanding with Hierarchical Self-Distillation
Dec 28, 2023Numerous point-cloud understanding techniques focus on whole entities and have succeeded in obtaining satisfactory results and limited sparsity tolerance. However, these methods are generally sensitive to incomplete point clouds that are scanned with flaws or large gaps. To address this issue, in this paper, we propose an end-to-end architecture that compensates for and identifies partial point clouds on the fly. First, we propose a cascaded solution that integrates both the upstream and downstream networks simultaneously, allowing the task-oriented downstream to identify the points generated by the completion-oriented upstream. These two streams complement each other, resulting in improved performance for both completion and downstream-dependent tasks. Second, to explicitly understand the predicted points' pattern, we introduce hierarchical self-distillation (HSD), which can be applied to arbitrary hierarchy-based point cloud methods. HSD ensures that the deepest classifier with a larger perceptual field and longer code length provides additional regularization to intermediate ones rather than simply aggregating the multi-scale features, and therefore maximizing the mutual information between a teacher and students. We show the advantage of the self-distillation process in the hyperspaces based on the information bottleneck principle. On the classification task, our proposed method performs competitively on the synthetic dataset and achieves superior results on the challenging real-world benchmark when compared to the state-of-the-art models. Additional experiments also demonstrate the superior performance and generality of our framework on the part segmentation task.
Uni3DETR: Unified 3D Detection Transformer
Oct 09, 2023Existing point cloud based 3D detectors are designed for the particular scene, either indoor or outdoor ones. Because of the substantial differences in object distribution and point density within point clouds collected from various environments, coupled with the intricate nature of 3D metrics, there is still a lack of a unified network architecture that can accommodate diverse scenes. In this paper, we propose Uni3DETR, a unified 3D detector that addresses indoor and outdoor 3D detection within the same framework. Specifically, we employ the detection transformer with point-voxel interaction for object prediction, which leverages voxel features and points for cross-attention and behaves resistant to the discrepancies from data. We then propose the mixture of query points, which sufficiently exploits global information for dense small-range indoor scenes and local information for large-range sparse outdoor ones. Furthermore, our proposed decoupled IoU provides an easy-to-optimize training target for localization by disentangling the xy and z space. Extensive experiments validate that Uni3DETR exhibits excellent performance consistently on both indoor and outdoor 3D detection. In contrast to previous specialized detectors, which may perform well on some particular datasets but suffer a substantial degradation on different scenes, Uni3DETR demonstrates the strong generalization ability under heterogeneous conditions (Fig. 1). Codes are available at \href{https://github.com/zhenyuw16/Uni3DETR}{https://github.com/zhenyuw16/Uni3DETR}.
Alice Benchmarks: Connecting Real World Object Re-Identification with the Synthetic
Oct 06, 2023For object re-identification (re-ID), learning from synthetic data has become a promising strategy to cheaply acquire large-scale annotated datasets and effective models, with few privacy concerns. Many interesting research problems arise from this strategy, e.g., how to reduce the domain gap between synthetic source and real-world target. To facilitate developing more new approaches in learning from synthetic data, we introduce the Alice benchmarks, large-scale datasets providing benchmarks as well as evaluation protocols to the research community. Within the Alice benchmarks, two object re-ID tasks are offered: person and vehicle re-ID. We collected and annotated two challenging real-world target datasets: AlicePerson and AliceVehicle, captured under various illuminations, image resolutions, etc. As an important feature of our real target, the clusterability of its training set is not manually guaranteed to make it closer to a real domain adaptation test scenario. Correspondingly, we reuse existing PersonX and VehicleX as synthetic source domains. The primary goal is to train models from synthetic data that can work effectively in the real world. In this paper, we detail the settings of Alice benchmarks, provide an analysis of existing commonly-used domain adaptation methods, and discuss some interesting future directions. An online server will be set up for the community to evaluate methods conveniently and fairly.
Identity-Seeking Self-Supervised Representation Learning for Generalizable Person Re-identification
Aug 17, 2023



This paper aims to learn a domain-generalizable (DG) person re-identification (ReID) representation from large-scale videos \textbf{without any annotation}. Prior DG ReID methods employ limited labeled data for training due to the high cost of annotation, which restricts further advances. To overcome the barriers of data and annotation, we propose to utilize large-scale unsupervised data for training. The key issue lies in how to mine identity information. To this end, we propose an Identity-seeking Self-supervised Representation learning (ISR) method. ISR constructs positive pairs from inter-frame images by modeling the instance association as a maximum-weight bipartite matching problem. A reliability-guided contrastive loss is further presented to suppress the adverse impact of noisy positive pairs, ensuring that reliable positive pairs dominate the learning process. The training cost of ISR scales approximately linearly with the data size, making it feasible to utilize large-scale data for training. The learned representation exhibits superior generalization ability. \textbf{Without human annotation and fine-tuning, ISR achieves 87.0\% Rank-1 on Market-1501 and 56.4\% Rank-1 on MSMT17}, outperforming the best supervised domain-generalizable method by 5.0\% and 19.5\%, respectively. In the pre-training$\rightarrow$fine-tuning scenario, ISR achieves state-of-the-art performance, with 88.4\% Rank-1 on MSMT17. The code is at \url{https://github.com/dcp15/ISR_ICCV2023_Oral}.