 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniIndoor3D: Comprehensive Indoor 3D Reconstruction
May 27, 2025We propose a novel framework for comprehensive indoor 3D reconstruction using Gaussian representations, called OmniIndoor3D. This framework enables accurate appearance, geometry, and panoptic reconstruction of diverse indoor scenes captured by a consumer-level RGB-D camera. Since 3DGS is primarily optimized for photorealistic rendering, it lacks the precise geometry critical for high-quality panoptic reconstruction. Therefore, OmniIndoor3D first combines multiple RGB-D images to create a coarse 3D reconstruction, which is then used to initialize the 3D Gaussians and guide the 3DGS training. To decouple the optimization conflict between appearance and geometry, we introduce a lightweight MLP that adjusts the geometric properties of 3D Gaussians. The introduced lightweight MLP serves as a low-pass filter for geometry reconstruction and significantly reduces noise in indoor scenes. To improve the distribution of Gaussian primitives, we propose a densification strategy guided by panoptic priors to encourage smoothness on planar surfaces. Through the joint optimization of appearance, geometry, and panoptic reconstruction, OmniIndoor3D provides comprehensive 3D indoor scene understanding, which facilitates accurate and robust robotic navigation. We perform thorough evaluations across multiple datasets, and OmniIndoor3D achieves state-of-the-art results in appearance, geometry, and panoptic reconstruction. We believe our work bridges a critical gap in indoor 3D reconstruction. The code will be released at: https://ucwxb.github.io/OmniIndoor3D/
SpikeGen: Generative Framework for Visual Spike Stream Processing
May 23, 2025Neuromorphic Visual Systems, such as spike cameras, have attracted considerable attention due to their ability to capture clear textures under dynamic conditions. This capability effectively mitigates issues related to motion and aperture blur. However, in contrast to conventional RGB modalities that provide dense spatial information, these systems generate binary, spatially sparse frames as a trade-off for temporally rich visual streams. In this context, generative models emerge as a promising solution to address the inherent limitations of sparse data. These models not only facilitate the conditional fusion of existing information from both spike and RGB modalities but also enable the conditional generation based on latent priors. In this study, we introduce a robust generative processing framework named SpikeGen, designed for visual spike streams captured by spike cameras. We evaluate this framework across multiple tasks involving mixed spike-RGB modalities, including conditional image/video deblurring, dense frame reconstruction from spike streams, and high-speed scene novel-view synthesis. Supported by comprehensive experimental results, we demonstrate that leveraging the latent space operation abilities of generative models allows us to effectively address the sparsity of spatial information while fully exploiting the temporal richness of spike streams, thereby promoting a synergistic enhancement of different visual modalities.
AFCL: Analytic Federated Continual Learning for Spatio-Temporal Invariance of Non-IID Data
May 18, 2025Federated Continual Learning (FCL) enables distributed clients to collaboratively train a global model from online task streams in dynamic real-world scenarios. However, existing FCL methods face challenges of both spatial data heterogeneity among distributed clients and temporal data heterogeneity across online tasks. Such data heterogeneity significantly degrades the model performance with severe spatial-temporal catastrophic forgetting of local and past knowledge. In this paper, we identify that the root cause of this issue lies in the inherent vulnerability and sensitivity of gradients to non-IID data. To fundamentally address this issue, we propose a gradient-free method, named Analytic Federated Continual Learning (AFCL), by deriving analytical (i.e., closed-form) solutions from frozen extracted features. In local training, our AFCL enables single-epoch learning with only a lightweight forward-propagation process for each client. In global aggregation, the server can recursively and efficiently update the global model with single-round aggregation. Theoretical analyses validate that our AFCL achieves spatio-temporal invariance of non-IID data. This ideal property implies that, regardless of how heterogeneous the data are distributed across local clients and online tasks, the aggregated model of our AFCL remains invariant and identical to that of centralized joint learning. Extensive experiments show the consistent superiority of our AFCL over state-of-the-art baselines across various benchmark datasets and settings.
ACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
May 18, 2025The development of artificial intelligence demands that models incrementally update knowledge by Continual Learning (CL) to adapt to open-world environments. To meet privacy and security requirements, Continual Unlearning (CU) emerges as an important problem, aiming to sequentially forget particular knowledge acquired during the CL phase. However, existing unlearning methods primarily focus on single-shot joint forgetting and face significant limitations when applied to CU. First, most existing methods require access to the retained dataset for re-training or fine-tuning, violating the inherent constraint in CL that historical data cannot be revisited. Second, these methods often suffer from a poor trade-off between system efficiency and model fidelity, making them vulnerable to being overwhelmed or degraded by adversaries through deliberately frequent requests. In this paper, we identify that the limitations of existing unlearning methods stem fundamentally from their reliance on gradient-based updates. To bridge the research gap at its root, we propose a novel gradient-free method for CU, named Analytic Continual Unlearning (ACU), for efficient and exact forgetting with historical data privacy preservation. In response to each unlearning request, our ACU recursively derives an analytical (i.e., closed-form) solution in an interpretable manner using the least squares method. Theoretical and experimental evaluations validate the superiority of our ACU on unlearning effectiveness, model fidelity, and system efficiency.
H2R: A Human-to-Robot Data Augmentation for Robot Pre-training from Videos
May 17, 2025



Large-scale pre-training using videos has proven effective for robot learning. However, the models pre-trained on such data can be suboptimal for robot learning due to the significant visual gap between human hands and those of different robots. To remedy this, we propose H2R, a simple data augmentation technique that detects human hand keypoints, synthesizes robot motions in simulation, and composites rendered robots into egocentric videos. This process explicitly bridges the visual gap between human and robot embodiments during pre-training. We apply H2R to augment large-scale egocentric human video datasets such as Ego4D and SSv2, replacing human hands with simulated robotic arms to generate robot-centric training data. Based on this, we construct and release a family of 1M-scale datasets covering multiple robot embodiments (UR5 with gripper/Leaphand, Franka) and data sources (SSv2, Ego4D). To verify the effectiveness of the augmentation pipeline, we introduce a CLIP-based image-text similarity metric that quantitatively evaluates the semantic fidelity of robot-rendered frames to the original human actions. We validate H2R across three simulation benchmarks: Robomimic, RLBench and PushT and real-world manipulation tasks with a UR5 robot equipped with Gripper and Leaphand end-effectors. H2R consistently improves downstream success rates, yielding gains of 5.0%-10.2% in simulation and 6.7%-23.3% in real-world tasks across various visual encoders and policy learning methods. These results indicate that H2R improves the generalization ability of robotic policies by mitigating the visual discrepancies between human and robot domains.
FreqMoE: Dynamic Frequency Enhancement for Neural PDE Solvers
May 11, 2025Fourier Neural Operators (FNO) have emerged as promising solutions for efficiently solving partial differential equations (PDEs) by learning infinite-dimensional function mappings through frequency domain transformations. However, the sparsity of high-frequency signals limits computational efficiency for high-dimensional inputs, and fixed-pattern truncation often causes high-frequency signal loss, reducing performance in scenarios such as high-resolution inputs or long-term predictions. To address these challenges, we propose FreqMoE, an efficient and progressive training framework that exploits the dependency of high-frequency signals on low-frequency components. The model first learns low-frequency weights and then applies a sparse upward-cycling strategy to construct a mixture of experts (MoE) in the frequency domain, effectively extending the learned weights to high-frequency regions. Experiments on both regular and irregular grid PDEs demonstrate that FreqMoE achieves up to 16.6% accuracy improvement while using merely 2.1% parameters (47.32x reduction) compared to dense FNO. Furthermore, the approach demonstrates remarkable stability in long-term predictions and generalizes seamlessly to various FNO variants and grid structures, establishing a new ``Low frequency Pretraining, High frequency Fine-tuning'' paradigm for solving PDEs.
RoboOS: A Hierarchical Embodied Framework for Cross-Embodiment and Multi-Agent Collaboration
May 06, 2025The dawn of embodied intelligence has ushered in an unprecedented imperative for resilient, cognition-enabled multi-agent collaboration across next-generation ecosystems, revolutionizing paradigms in autonomous manufacturing, adaptive service robotics, and cyber-physical production architectures. However, current robotic systems face significant limitations, such as limited cross-embodiment adaptability, inefficient task scheduling, and insufficient dynamic error correction. While End-to-end VLA models demonstrate inadequate long-horizon planning and task generalization, hierarchical VLA models suffer from a lack of cross-embodiment and multi-agent coordination capabilities. To address these challenges, we introduce RoboOS, the first open-source embodied system built on a Brain-Cerebellum hierarchical architecture, enabling a paradigm shift from single-agent to multi-agent intelligence. Specifically, RoboOS consists of three key components: (1) Embodied Brain Model (RoboBrain), a MLLM designed for global perception and high-level decision-making; (2) Cerebellum Skill Library, a modular, plug-and-play toolkit that facilitates seamless execution of multiple skills; and (3) Real-Time Shared Memory, a spatiotemporal synchronization mechanism for coordinating multi-agent states. By integrating hierarchical information flow, RoboOS bridges Embodied Brain and Cerebellum Skill Library, facilitating robust planning, scheduling, and error correction for long-horizon tasks, while ensuring efficient multi-agent collaboration through Real-Time Shared Memory. Furthermore, we enhance edge-cloud communication and cloud-based distributed inference to facilitate high-frequency interactions and enable scalable deployment. Extensive real-world experiments across various scenarios, demonstrate RoboOS's versatility in supporting heterogeneous embodiments. Project website: https://github.com/FlagOpen/RoboOS
CrayonRobo: Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
May 04, 2025In robotic, task goals can be conveyed through various modalities, such as language, goal images, and goal videos. However, natural language can be ambiguous, while images or videos may offer overly detailed specifications. To tackle these challenges, we introduce CrayonRobo that leverages comprehensive multi-modal prompts that explicitly convey both low-level actions and high-level planning in a simple manner. Specifically, for each key-frame in the task sequence, our method allows for manual or automatic generation of simple and expressive 2D visual prompts overlaid on RGB images. These prompts represent the required task goals, such as the end-effector pose and the desired movement direction after contact. We develop a training strategy that enables the model to interpret these visual-language prompts and predict the corresponding contact poses and movement directions in SE(3) space. Furthermore, by sequentially executing all key-frame steps, the model can complete long-horizon tasks. This approach not only helps the model explicitly understand the task objectives but also enhances its robustness on unseen tasks by providing easily interpretable prompts. We evaluate our method in both simulated and real-world environments, demonstrating its robust manipulation capabilities.
Co$^{3}$Gesture: Towards Coherent Concurrent Co-speech 3D Gesture Generation with Interactive Diffusion
May 03, 2025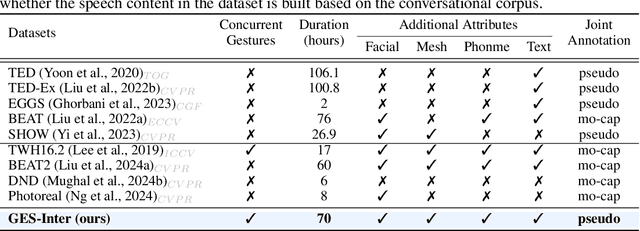

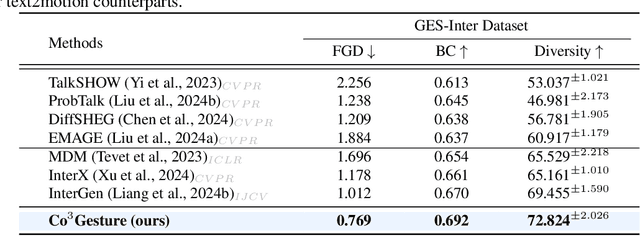
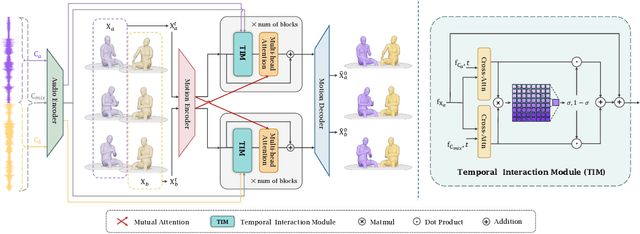
Generating gestures from human speech has gained tremendous progress in animating virtual avatars. While the existing methods enable synthesizing gestures cooperated by individual self-talking, they overlook the practicality of concurrent gesture modeling with two-person interactive conversations. Moreover, the lack of high-quality datasets with concurrent co-speech gestures also limits handling this issue. To fulfill this goal, we first construct a large-scale concurrent co-speech gesture dataset that contains more than 7M frames for diverse two-person interactive posture sequences, dubbed GES-Inter. Additionally, we propose Co$^3$Gesture, a novel framework that enables coherent concurrent co-speech gesture synthesis including two-person interactive movements. Considering the asymmetric body dynamics of two speakers, our framework is built upon two cooperative generation branches conditioned on separated speaker audio. Specifically, to enhance the coordination of human postures with respect to corresponding speaker audios while interacting with the conversational partner, we present a Temporal Interaction Module (TIM). TIM can effectively model the temporal association representation between two speakers' gesture sequences as interaction guidance and fuse it into the concurrent gesture generation. Then, we devise a mutual attention mechanism to further holistically boost learning dependencies of interacted concurrent motions, thereby enabling us to generate vivid and coherent gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected GES-Inter dataset. The dataset and source code are publicly available at \href{https://mattie-e.github.io/Co3/}{\textit{https://mattie-e.github.io/Co3/}}.
ManipDreamer: Boosting Robotic Manipulation World Model with Action Tree and Visual Guidance
Apr 23, 2025



While recent advancements in robotic manipulation video synthesis have shown promise, significant challenges persist in ensuring effective instruction-following and achieving high visual quality. Recent methods, like RoboDreamer, utilize linguistic decomposition to divide instructions into separate lower-level primitives, conditioning the world model on these primitives to achieve compositional instruction-following. However, these separate primitives do not consider the relationships that exist between them. Furthermore, recent methods neglect valuable visual guidance, including depth and semantic guidance, both crucial for enhancing visual quality. This paper introduces ManipDreamer, an advanced world model based on the action tree and visual guidance. To better learn the relationships between instruction primitives, we represent the instruction as the action tree and assign embeddings to tree nodes, each instruction can acquire its embeddings by navigating through the action tree. The instruction embeddings can be used to guide the world model. To enhance visual quality, we combine depth and semantic guidance by introducing a visual guidance adapter compatible with the world model. This visual adapter enhances both the temporal and physical consistency of video generation. Based on the action tree and visual guidance, ManipDreamer significantly boosts the instruction-following ability and visual quality. Comprehensive evaluations on robotic manipulation benchmarks reveal that ManipDreamer achieves large improvements in video quality metrics in both seen and unseen tasks, with PSNR improved from 19.55 to 21.05, SSIM improved from 0.7474 to 0.7982 and reduced Flow Error from 3.506 to 3.201 in unseen tasks, compared to the recent RoboDreamer model. Additionally, our method increases the success rate of robotic manipulation tasks by 2.5% in 6 RLbench tasks on average.