 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinRL-VLA: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation
Feb 09, 2026Despite strong generalization capabilities, Vision-Language-Action (VLA) models remain constrained by the high cost of expert demonstrations and insufficient real-world interaction. While online reinforcement learning (RL) has shown promise in improving general foundation models, applying RL to VLA manipulation in real-world settings is still hindered by low exploration efficiency and a restricted exploration space. Through systematic real-world experiments, we observe that the effective exploration space of online RL is closely tied to the data distribution of supervised fine-tuning (SFT). Motivated by this observation, we propose TwinRL, a digital twin-real-world collaborative RL framework designed to scale and guide exploration for VLA models. First, a high-fidelity digital twin is efficiently reconstructed from smartphone-captured scenes, enabling realistic bidirectional transfer between real and simulated environments. During the SFT warm-up stage, we introduce an exploration space expansion strategy using digital twins to broaden the support of the data trajectory distribution. Building on this enhanced initialization, we propose a sim-to-real guided exploration strategy to further accelerate online RL. Specifically, TwinRL performs efficient and parallel online RL in the digital twin prior to deployment, effectively bridging the gap between offline and online training stages. Subsequently, we exploit efficient digital twin sampling to identify failure-prone yet informative configurations, which are used to guide targeted human-in-the-loop rollouts on the real robot. In our experiments, TwinRL approaches 100% success in both in-distribution regions covered by real-world demonstrations and out-of-distribution regions, delivering at least a 30% speedup over prior real-world RL methods and requiring only about 20 minutes on average across four tasks.
MapNav: A Novel Memory Representation via Annotated Semantic Maps for VLM-based Vision-and-Language Navigation
Feb 19, 2025



Vision-and-language navigation (VLN) is a key task in Embodied AI, requiring agents to navigate diverse and unseen environments while following natural language instructions. Traditional approaches rely heavily on historical observations as spatio-temporal contexts for decision making, leading to significant storage and computational overhead. In this paper, we introduce MapNav, a novel end-to-end VLN model that leverages Annotated Semantic Map (ASM) to replace historical frames. Specifically, our approach constructs a top-down semantic map at the start of each episode and update it at each timestep, allowing for precise object mapping and structured navigation information. Then, we enhance this map with explicit textual labels for key regions, transforming abstract semantics into clear navigation cues and generate our ASM. MapNav agent using the constructed ASM as input, and use the powerful end-to-end capabilities of VLM to empower VLN. Extensive experiments demonstrate that MapNav achieves state-of-the-art (SOTA) performance in both simulated and real-world environments, validating the effectiveness of our method. Moreover, we will release our ASM generation source code and dataset to ensure reproducibility, contributing valuable resources to the field. We believe that our proposed MapNav can be used as a new memory representation method in VLN, paving the way for future research in this field.
SpikeNVS: Enhancing Novel View Synthesis from Blurry Images via Spike Camera
Apr 12, 2024One of the most critical factors in achieving sharp Novel View Synthesis (NVS) using neural field methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) is the quality of the training images. However, Conventional RGB cameras are susceptible to motion blur. In contrast, neuromorphic cameras like event and spike cameras inherently capture more comprehensive temporal information, which can provide a sharp representation of the scene as additional training data. Recent methods have explored the integration of event cameras to improve the quality of NVS. The event-RGB approaches have some limitations, such as high training costs and the inability to work effectively in the background. Instead, our study introduces a new method that uses the spike camera to overcome these limitations. By considering texture reconstruction from spike streams as ground truth, we design the Texture from Spike (TfS) loss. Since the spike camera relies on temporal integration instead of temporal differentiation used by event cameras, our proposed TfS loss maintains manageable training costs. It handles foreground objects with backgrounds simultaneously. We also provide a real-world dataset captured with our spike-RGB camera system to facilitate future research endeavors. We conduct extensive experiments using synthetic and real-world datasets to demonstrate that our design can enhance novel view synthesis across NeRF and 3DGS. The code and dataset will be made available for public access.
SMOF: Squeezing More Out of Filters Yields Hardware-Friendly CNN Pruning
Oct 21, 2021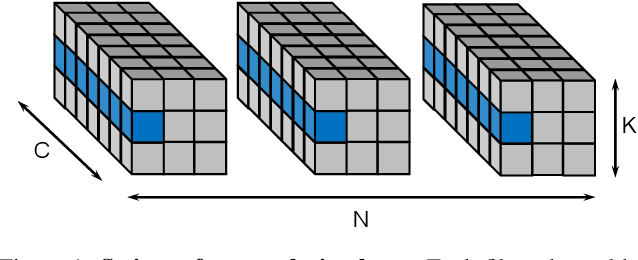
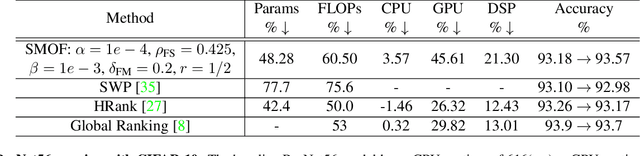
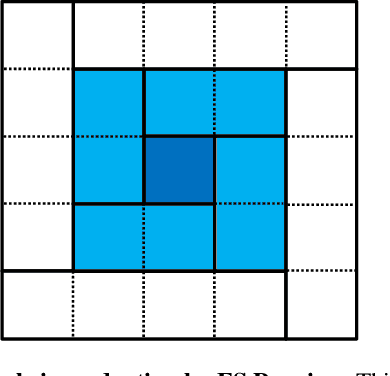
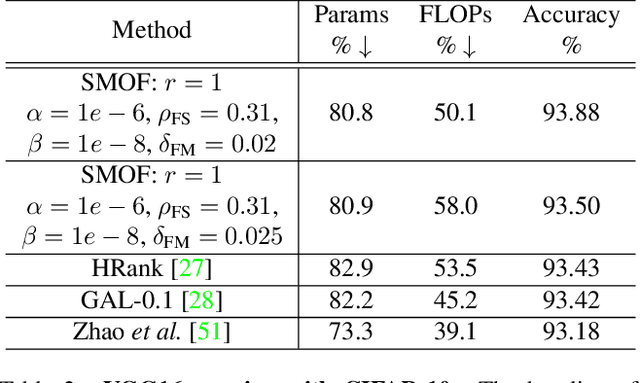
For many years, the family of convolutional neural networks (CNNs) has been a workhorse in deep learning. Recently, many novel CNN structures have been designed to address increasingly challenging tasks. To make them work efficiently on edge devices, researchers have proposed various structured network pruning strategies to reduce their memory and computational cost. However, most of them only focus on reducing the number of filter channels per layer without considering the redundancy within individual filter channels. In this work, we explore pruning from another dimension, the kernel size. We develop a CNN pruning framework called SMOF, which Squeezes More Out of Filters by reducing both kernel size and the number of filter channels. Notably, SMOF is friendly to standard hardware devices without any customized low-level implementations, and the pruning effort by kernel size reduction does not suffer from the fixed-size width constraint in SIMD units of general-purpose processors. The pruned networks can be deployed effortlessly with significant running time reduction. We also support these claims via extensive experiments on various CNN structures and general-purpose processors for mobile devices.