 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveform Design for Partial-Time Superimposed ISAC Systems
Feb 23, 2026Nowadays, waveforms of integrated sensing and communication (ISAC) are almost based on conventional communication and sensing signal, which bounds both the communication and sensing performance. To deal with this issue, in this paper, a novel waveform design is presented for the partial-time superimposed (PTS) ISAC system. At the base station (BS), a parameter-adjustable linear frequency modulation (LFM) pulse signal and a continuous communication orthogonal frequency division multiplexing (OFDM) signal are employed to broadcast public information and perform sensing tasks, respectively, using a PTS scheme. Pulse compression gain enhances the system's long-range sensing capability, while OFDM ensures the system's high-speed data transmission capability. Meanwhile, the LFM signal is utilized as superimposed pilot for channel estimation, which has higher time-frequency resource utilization and stronger real-time performance compared to orthogonal pilots. We present an accurate parameter estimation method of multi-path sensing signal for reconstructing and interference cancellation in communication users. Additionally, a cyclic maximum likelihood method is introduced for channel estimation and the Cramer-Rao lower bound (CRLB) of channel estimation is derived. Simulations demonstrate the accuracy and robustness of the proposed parameter estimation algorithm as well as the improved channel estimation performance over traditional methods. The proposed waveform design method can achieve reliable data transmission and accurate target sensing.
* 15 pages, 17 figures, journal
Proximity QA: Unleashing the Power of Multi-Modal Large Language Models for Spatial Proximity Analysis
Jan 31, 2024



Multi-modal large language models (MLLMs) have demonstrated remarkable vision-language capabilities, primarily due to the exceptional in-context understanding and multi-task learning strengths of large language models (LLMs). The advent of visual instruction tuning has further enhanced MLLMs' performance in vision-language understanding. However, while existing MLLMs adeptly recognize \textit{what} objects are in an image, they still face challenges in effectively discerning \textit{where} these objects are, particularly along the distance (scene depth) axis. To overcome this limitation in MLLMs, we introduce Proximity Question Answering (Proximity QA), a novel framework designed to enable MLLMs to infer the proximity relationship between objects in images. The framework operates in two phases: the first phase focuses on guiding the models to understand the relative depth of objects, and the second phase further encourages the models to infer the proximity relationships between objects based on their depth perceptions. We also propose a VQA dataset called Proximity-110K, containing additional instructions that incorporate depth information and the proximity relationships of objects. We have conducted extensive experiments to validate Proximity QA's superior ability in depth perception and proximity analysis, outperforming other state-of-the-art MLLMs. Code and dataset will be released at \textcolor{magenta}{https://github.com/NorthSummer/ProximityQA.git}.
Detecting Transaction-based Tax Evasion Activities on Social Media Platforms Using Multi-modal Deep Neural Networks
Jul 27, 2020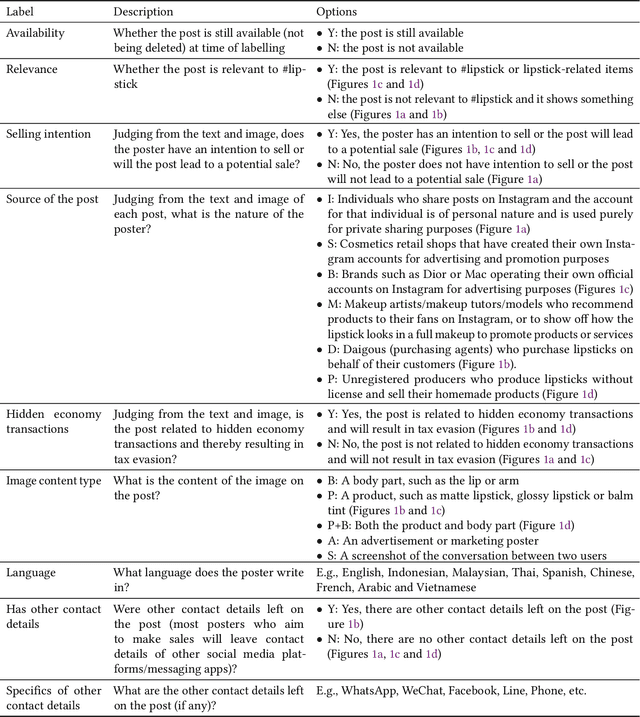

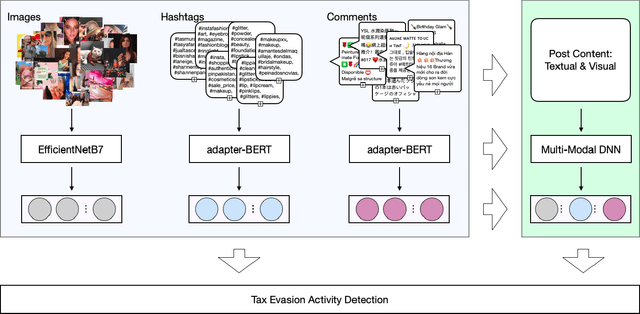
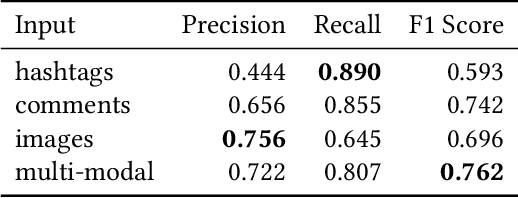
Social media platforms now serve billions of users by providing convenient means of communication, content sharing and even payment between different users. Due to such convenient and anarchic nature, they have also been used rampantly to promote and conduct business activities between unregistered market participants without paying taxes. Tax authorities worldwide face difficulties in regulating these hidden economy activities by traditional regulatory means. This paper presents a machine learning based Regtech tool for international tax authorities to detect transaction-based tax evasion activities on social media platforms. To build such a tool, we collected a dataset of 58,660 Instagram posts and manually labelled 2,081 sampled posts with multiple properties related to transaction-based tax evasion activities. Based on the dataset, we developed a multi-modal deep neural network to automatically detect suspicious posts. The proposed model combines comments, hashtags and image modalities to produce the final output. As shown by our experiments, the combined model achieved an AUC of 0.808 and F1 score of 0.762, outperforming any single modality models. This tool could help tax authorities to identify audit targets in an efficient and effective manner, and combat social e-commerce tax evasion in scale.