 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniUMI: Towards Physically Grounded Robot Learning via Human-Aligned Multimodal Interaction
Apr 12, 2026UMI-style interfaces enable scalable robot learning, but existing systems remain largely visuomotor, relying primarily on RGB observations and trajectory while providing only limited access to physical interaction signals. This becomes a fundamental limitation in contact-rich manipulation, where success depends on contact dynamics such as tactile interaction, internal grasping force, and external interaction wrench that are difficult to infer from vision alone. We present OmniUMI, a unified framework for physically grounded robot learning via human-aligned multimodal interaction. OmniUMI synchronously captures RGB, depth, trajectory, tactile sensing, internal grasping force, and external interaction wrench within a compact handheld system, while maintaining collection--deployment consistency through a shared embodiment design. To support human-aligned demonstration, OmniUMI provides dual-force feedback through bilateral gripper feedback and natural perception of external interaction wrench in the handheld embodiment. Built on this interface, we extend diffusion policy with visual, tactile, and force-related observations, and deploy the learned policy through impedance-based execution for unified regulation of motion and contact behavior. Experiments demonstrate reliable sensing and strong downstream performance on force-sensitive pick-and-place, interactive surface erasing, and tactile-informed selective release. Overall, OmniUMI combines physically grounded multimodal data acquisition with human-aligned interaction, providing a scalable foundation for learning contact-rich manipulation.
Ge$^\text{2}$mS-T: Multi-Dimensional Grouping for Ultra-High Energy Efficiency in Spiking Transformer
Apr 10, 2026Spiking Neural Networks (SNNs) offer superior energy efficiency over Artificial Neural Networks (ANNs). However, they encounter significant deficiencies in training and inference metrics when applied to Spiking Vision Transformers (S-ViTs). Existing paradigms including ANN-SNN Conversion and Spatial-Temporal Backpropagation (STBP) suffer from inherent limitations, precluding concurrent optimization of memory, accuracy and energy consumption. To address these issues, we propose Ge$^\text{2}$mS-T, a novel architecture implementing grouped computation across temporal, spatial and network structure dimensions. Specifically, we introduce the Grouped-Exponential-Coding-based IF (ExpG-IF) model, enabling lossless conversion with constant training overhead and precise regulation for spike patterns. Additionally, we develop Group-wise Spiking Self-Attention (GW-SSA) to reduce computational complexity via multi-scale token grouping and multiplication-free operations within a hybrid attention-convolution framework. Experiments confirm that our method can achieve superior performance with ultra-high energy efficiency on challenging benchmarks. To our best knowledge, this is the first work to systematically establish multi-dimensional grouped computation for resolving the triad of memory overhead, learning capability and energy budget in S-ViTs.
BAAI Cardiac Agent: An intelligent multimodal agent for automated reasoning and diagnosis of cardiovascular diseases from cardiac magnetic resonance imaging
Apr 05, 2026Cardiac magnetic resonance (CMR) is a cornerstone for diagnosing cardiovascular disease. However, it remains underutilized due to complex, time-consuming interpretation across multi-sequences, phases, quantitative measures that heavily reliant on specialized expertise. Here, we present BAAI Cardiac Agent, a multimodal intelligent system designed for end-to-end CMR interpretation. The agent integrates specialized cardiac expert models to perform automated segmentation of cardiac structures, functional quantification, tissue characterization and disease diagnosis, and generates structured clinical reports within a unified workflow. Evaluated on CMR datasets from two hospitals (2413 patients) spanning 7-types of major cardiovascular diseases, the agent achieved an area under the receiver-operating-characteristic curve exceeding 0.93 internally and 0.81 externally. In the task of estimating left ventricular function indices, the results generated by this system for core parameters such as ejection fraction, stroke volume, and left ventricular mass are highly consistent with clinical reports, with Pearson correlation coefficients all exceeding 0.90. The agent outperformed state-of-the-art models in segmentation and diagnostic tasks, and generated clinical reports showing high concordance with expert radiologists (six readers across three experience levels). By dynamically orchestrating expert models for coordinated multimodal analysis, this agent framework enables accurate, efficient CMR interpretation and highlights its potentials for complex clinical imaging workflows. Code is available at https://github.com/plantain-herb/Cardiac-Agent.
Brain-Inspired Multimodal Spiking Neural Network for Image-Text Retrieval
Mar 25, 2026Spiking neural networks (SNNs) have recently shown strong potential in unimodal visual and textual tasks, yet building a directly trained, low-energy, and high-performance SNN for multimodal applications such as image-text retrieval (ITR) remains highly challenging. Existing artificial neural network (ANN)-based methods often pursue richer unimodal semantics using deeper and more complex architectures, while overlooking cross-modal interaction, retrieval latency, and energy efficiency. To address these limitations, we present a brain-inspired Cross-Modal Spike Fusion network (CMSF) and apply it to ITR for the first time. The proposed spike fusion mechanism integrates unimodal features at the spike level, generating enhanced multimodal representations that act as soft supervisory signals to refine unimodal spike embeddings, effectively mitigating semantic loss within CMSF. Despite requiring only two time steps, CMSF achieves top-tier retrieval accuracy, surpassing state-of-the-art ANN counterparts while maintaining exceptionally low energy consumption and high retrieval speed. This work marks a significant step toward multimodal SNNs, offering a brain-inspired framework that unifies temporal dynamics with cross-modal alignment and provides new insights for future spiking-based multimodal research. The code is available at https://github.com/zxt6174/CMSF.
General Self-Prediction Enhancement for Spiking Neurons
Jan 29, 2026Spiking Neural Networks (SNNs) are highly energy-efficient due to event-driven, sparse computation, but their training is challenged by spike non-differentiability and trade-offs among performance, efficiency, and biological plausibility. Crucially, mainstream SNNs ignore predictive coding, a core cortical mechanism where the brain predicts inputs and encodes errors for efficient perception. Inspired by this, we propose a self-prediction enhanced spiking neuron method that generates an internal prediction current from its input-output history to modulate membrane potential. This design offers dual advantages, it creates a continuous gradient path that alleviates vanishing gradients and boosts training stability and accuracy, while also aligning with biological principles, which resembles distal dendritic modulation and error-driven synaptic plasticity. Experiments show consistent performance gains across diverse architectures, neuron types, time steps, and tasks demonstrating broad applicability for enhancing SNNs.
RoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
On-the-fly Large-scale 3D Reconstruction from Multi-Camera Rigs
Dec 09, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled efficient free-viewpoint rendering and photorealistic scene reconstruction. While on-the-fly extensions of 3DGS have shown promise for real-time reconstruction from monocular RGB streams, they often fail to achieve complete 3D coverage due to the limited field of view (FOV). Employing a multi-camera rig fundamentally addresses this limitation. In this paper, we present the first on-the-fly 3D reconstruction framework for multi-camera rigs. Our method incrementally fuses dense RGB streams from multiple overlapping cameras into a unified Gaussian representation, achieving drift-free trajectory estimation and efficient online reconstruction. We propose a hierarchical camera initialization scheme that enables coarse inter-camera alignment without calibration, followed by a lightweight multi-camera bundle adjustment that stabilizes trajectories while maintaining real-time performance. Furthermore, we introduce a redundancy-free Gaussian sampling strategy and a frequency-aware optimization scheduler to reduce the number of Gaussian primitives and the required optimization iterations, thereby maintaining both efficiency and reconstruction fidelity. Our method reconstructs hundreds of meters of 3D scenes within just 2 minutes using only raw multi-camera video streams, demonstrating unprecedented speed, robustness, and Fidelity for on-the-fly 3D scene reconstruction.
Driving in Spikes: An Entropy-Guided Object Detector for Spike Cameras
Nov 19, 2025Object detection in autonomous driving suffers from motion blur and saturation under fast motion and extreme lighting. Spike cameras, offer microsecond latency and ultra high dynamic range for object detection by using per pixel asynchronous integrate and fire. However, their sparse, discrete output cannot be processed by standard image-based detectors, posing a critical challenge for end to end spike stream detection. We propose EASD, an end to end spike camera detector with a dual branch design: a Temporal Based Texture plus Feature Fusion branch for global cross slice semantics, and an Entropy Selective Attention branch for object centric details. To close the data gap, we introduce DSEC Spike, the first driving oriented simulated spike detection benchmark.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


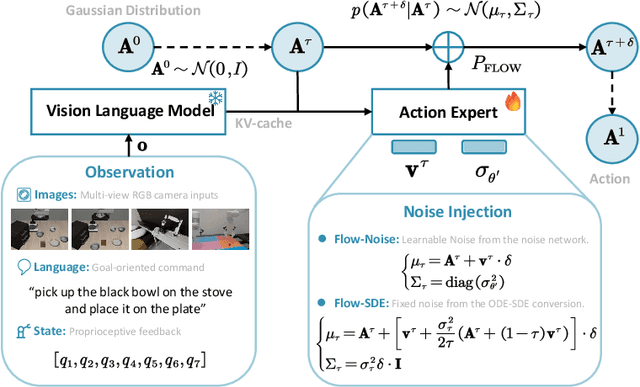
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.