 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSTORM: Scaling LLM Reasoning on Dynamic Graphs via Adaptive Spatio-Temporal Multi-Agent Collaboration
Jun 15, 2026Large Language Models (LLMs) demonstrate remarkable potential in dynamic graph reasoning, but suffer from a scaling bottleneck: current models can only handle graphs with tens of nodes, constrained by exponential reasoning overhead and finite context windows. While multi-agent systems (MAS) offer collective reasoning and topology-aware orchestration, capabilities naturally suited for graph-structured tasks, their application to dynamic graphs remains unexplored. This paper presents Scaling LLM Reasoning on Dynamic Graphs via Adaptive Spatio-Temporal Multi-Agent Collaboration (AdaSTORM), a framework that reformulates large-scale dynamic graph reasoning into two stages: (i) Adaptive Partitioning, partitioning large-scale dynamic graphs into subregions that match the model's reasoning capacity while minimizing inference cost; and (ii) Collaborative Reasoning, aligning graph partition topologies with a spatio-temporal decoupled multi-agent architecture. AdaSTORM is the first multi-agent framework tailored for dynamic graph reasoning. Extensive experiments show that AdaSTORM successfully breaks through the scaling bottleneck, scaling reasoning to thousand-node graphs with over 90% accuracy across several large-scale dynamic graph settings without external tools, significantly outperforms seven competitive baselines. Furthermore, it achieves state-of-the-art accuracy on existing benchmarks and generalizes robustly to real-world datasets. The source code is available at: https://github.com/irisorchid107/AdaSTORM/.
G2LoRA: Gradient Orthogonal Low-Rank Adaptation Framework for Graph Continual Learning on Text-Attributed Graphs
Jun 01, 2026LLM-as-Aligner has emerged as a prevalent pre-training paradigm for Text-Attributed Graphs(TAGS), aligning graph and text modalities into a shared embedding space via CLIP-style contrastive learning. While effective on individual downstream tasks, we observe severe catastrophic forgetting when such models are sequentially fine-tuned on streaming tasks. Although parameter-efficient fine-tuning alleviates forgetting to some extent, it remains insufficient to resolve task interference and ineffective knowledge transfer. In this work, we study graph continual learning for LLM-as-Aligner models on TAGs, with the goal of mitigating interference while promoting positive transfer across tasks. This setting introduces two fundamental challenges: (1) heterogeneous downstream tasks induce shifting optimization objectives, hindering unified fine-tuning; and (2) graph and text encoders exhibit different sensitivities to adaptation, making uncoordinated updates prone to misalignment. To address these challenges, we propose G2LoRA, a continual learning framework for TAGs. G2LoRA unifies node-, link-, and graph-level tasks under a single graph--text alignment objective, and enables consistent optimization across domain/class/task incremental modes. To reduce task interference while encouraging positive transfer, G2LoRA performs category-aware gradient projection in structured subspaces, resolving conflicting updates and enabling conditional backward transfer to balance forward and backward knowledge flow. To further prevent cross-modal drift, G2LoRA introduces gradient magnitude modulation to coordinate update rates between graph and text encoders. Extensive experiments on benchmark datasets demonstrate that G2LoRA consistently outperforms strong baselines across different backbone architectures, achieving superior continual performance and transferability.
S2Aligner: Pair-Efficient and Transferable Pre-Training for Sparse Text-Attributed Graphs
May 20, 2026Pre-training on text-attributed graphs (TAGs) is central to building transferable graph foundation models, where LLM-as-Aligner methods align graph and text representations through the semantic knowledge of large language models. However, these methods usually assume that node texts provide sufficient and reliable supervision, an assumption often violated in real-world sparse TAGs. When textual anchors are missing, noisy, or uneven across domains, graph structures must be aligned with weak semantic evidence, leading to unreliable structure-semantics correspondence and sparsity-induced transfer bias. This paper presents S2Aligner, a sparsity-aware and structure-enhanced LLM-as-Aligner framework for graph-text pre-training on sparse TAGs. The key idea is to decouple semantic alignment from structural modeling, allowing topology-aware signals to enhance alignment without contaminating the shared semantic space. Specifically, S2Aligner decomposes graph-text representations into semantic and structural components, uses structure-oriented reconstruction with consistency control to inject reliable topology cues into text representations, and suppresses inconsistent structural signals under textual sparsity. Moreover, S2Aligner introduces sparsity-aware cross-domain risk balancing, which calibrates domain risks through a global-domain density ratio and downweights unreliable sparse samples via graph reliability estimation. Theoretical analysis shows that this objective reduces cross-domain generalization gaps by controlling domain risk discrepancy. Extensive experiments across diverse graph domains, sparsity levels, and downstream tasks demonstrate that S2Aligner consistently outperforms existing baselines.
SmartThinker: Progressive Chain-of-Thought Length Calibration for Efficient Large Language Model Reasoning
Mar 09, 2026Large reasoning models (LRMs) like OpenAI o1 and DeepSeek-R1 achieve high accuracy on complex tasks by adopting long chain-of-thought (CoT) reasoning paths. However, the inherent verbosity of these processes frequently results in redundancy and overthinking. To address this issue, existing works leverage Group Relative Policy Optimization (GRPO) to reduce LRM output length, but their static length reward design cannot dynamically adapt according to the relative problem difficulty and response length distribution, causing over-compression and compromised accuracy. Therefore, we propose SmartThinker, a novel GRPO-based efficient reasoning method with progressive CoT length calibration. SmartThinker makes a two-fold contribution: First, it dynamically estimates the optimal length with peak accuracy during training and guides overlong responses toward it to reduce response length while sustaining accuracy. Second, it dynamically modulates the length reward coefficient to avoid the unwarranted penalization of correct reasoning paths. Extensive experiment results show that SmartThinker achieves up to 52.5% average length compression with improved accuracy, and achieves up to 16.6% accuracy improvement on challenging benchmarks like AIME25. The source code can be found at https://github.com/SJTU-RTEAS/SmartThinker.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
LLMTM: Benchmarking and Optimizing LLMs for Temporal Motif Analysis in Dynamic Graphs
Dec 24, 2025The widespread application of Large Language Models (LLMs) has motivated a growing interest in their capacity for processing dynamic graphs. Temporal motifs, as an elementary unit and important local property of dynamic graphs which can directly reflect anomalies and unique phenomena, are essential for understanding their evolutionary dynamics and structural features. However, leveraging LLMs for temporal motif analysis on dynamic graphs remains relatively unexplored. In this paper, we systematically study LLM performance on temporal motif-related tasks. Specifically, we propose a comprehensive benchmark, LLMTM (Large Language Models in Temporal Motifs), which includes six tailored tasks across nine temporal motif types. We then conduct extensive experiments to analyze the impacts of different prompting techniques and LLMs (including nine models: openPangu-7B, the DeepSeek-R1-Distill-Qwen series, Qwen2.5-32B-Instruct, GPT-4o-mini, DeepSeek-R1, and o3) on model performance. Informed by our benchmark findings, we develop a tool-augmented LLM agent that leverages precisely engineered prompts to solve these tasks with high accuracy. Nevertheless, the high accuracy of the agent incurs a substantial cost. To address this trade-off, we propose a simple yet effective structure-aware dispatcher that considers both the dynamic graph's structural properties and the LLM's cognitive load to intelligently dispatch queries between the standard LLM prompting and the more powerful agent. Our experiments demonstrate that the structure-aware dispatcher effectively maintains high accuracy while reducing cost.
SPARQL-LLM: Real-Time SPARQL Query Generation from Natural Language Questions
Dec 16, 2025The advent of large language models is contributing to the emergence of novel approaches that promise to better tackle the challenge of generating structured queries, such as SPARQL queries, from natural language. However, these new approaches mostly focus on response accuracy over a single source while ignoring other evaluation criteria, such as federated query capability over distributed data stores, as well as runtime and cost to generate SPARQL queries. Consequently, they are often not production-ready or easy to deploy over (potentially federated) knowledge graphs with good accuracy. To mitigate these issues, in this paper, we extend our previous work and describe and systematically evaluate SPARQL-LLM, an open-source and triplestore-agnostic approach, powered by lightweight metadata, that generates SPARQL queries from natural language text. First, we describe its architecture, which consists of dedicated components for metadata indexing, prompt building, and query generation and execution. Then, we evaluate it based on a state-of-the-art challenge with multilingual questions, and a collection of questions from three of the most prevalent knowledge graphs within the field of bioinformatics. Our results demonstrate a substantial increase of 24% in the F1 Score on the state-of-the-art challenge, adaptability to high-resource languages such as English and Spanish, as well as ability to form complex and federated bioinformatics queries. Furthermore, we show that SPARQL-LLM is up to 36x faster than other systems participating in the challenge, while costing a maximum of $0.01 per question, making it suitable for real-time, low-cost text-to-SPARQL applications. One such application deployed over real-world decentralized knowledge graphs can be found at https://www.expasy.org/chat.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025



Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
Deep Generative Model-Based Generation of Synthetic Individual-Specific Brain MRI Segmentations
Apr 15, 2025
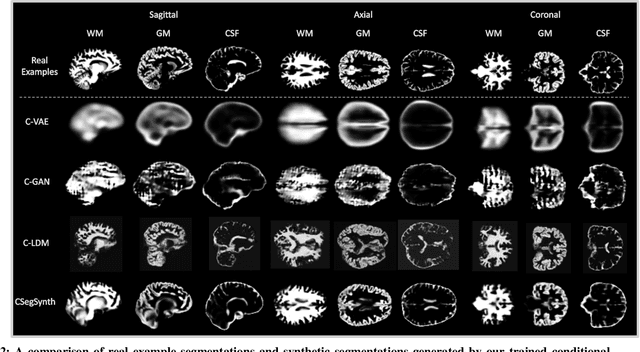


To the best of our knowledge, all existing methods that can generate synthetic brain magnetic resonance imaging (MRI) scans for a specific individual require detailed structural or volumetric information about the individual's brain. However, such brain information is often scarce, expensive, and difficult to obtain. In this paper, we propose the first approach capable of generating synthetic brain MRI segmentations -- specifically, 3D white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF) segmentations -- for individuals using their easily obtainable and often readily available demographic, interview, and cognitive test information. Our approach features a novel deep generative model, CSegSynth, which outperforms existing prominent generative models, including conditional variational autoencoder (C-VAE), conditional generative adversarial network (C-GAN), and conditional latent diffusion model (C-LDM). We demonstrate the high quality of our synthetic segmentations through extensive evaluations. Also, in assessing the effectiveness of the individual-specific generation, we achieve superior volume prediction, with Pearson correlation coefficients reaching 0.80, 0.82, and 0.70 between the ground-truth WM, GM, and CSF volumes of test individuals and those volumes predicted based on generated individual-specific segmentations, respectively.
Uncovering Cross-Domain Recommendation Ability of Large Language Models
Mar 10, 2025



Cross-Domain Recommendation (CDR) seeks to enhance item retrieval in low-resource domains by transferring knowledge from high-resource domains. While recent advancements in Large Language Models (LLMs) have demonstrated their potential in Recommender Systems (RS), their ability to effectively transfer domain knowledge for improved recommendations remains underexplored. To bridge this gap, we propose LLM4CDR, a novel CDR pipeline that constructs context-aware prompts by leveraging users' purchase history sequences from a source domain along with shared features between source and target domains. Through extensive experiments, we show that LLM4CDR achieves strong performance, particularly when using LLMs with large parameter sizes and when the source and target domains exhibit smaller domain gaps. For instance, incorporating CD and Vinyl purchase history for recommendations in Movies and TV yields a 64.28 percent MAP 1 improvement. We further investigate key factors including source domain data, domain gap, prompt design, and LLM size, which impact LLM4CDR's effectiveness in CDR tasks. Our results highlight that LLM4CDR excels when leveraging a single, closely related source domain and benefits significantly from larger LLMs. These insights pave the way for future research on LLM-driven cross-domain recommendations.