 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards transferable lightweight neuromorphic computing through a model-free temporal-switch framework
Jul 01, 2026Lightweight neuromorphic computing offers a promising route to efficient AI, with particular benefits for resource-constrained edge deployments. However, its scalable deployment that can reliably transfer the expected performance has long been hindered by device-to-device variations, which necessitate costly and repeated re-training on new copies and undermine the practical advantages. To address this issue, we introduce a model-free temporal-switch (TS) framework to improve the direct transfer performance, without post-training calibration or adjustment. The TS framework provides a methodology to incorporate a broader spectrum of devices in the training process. In the validation using memristor-based reservoir computing, it enables high performance on unseen devices with a directly transferred readout. It achieves improved prediction in the representative Mackey--Glass benchmark, and the accuracy of 92.4% in spoken digit classification. Its efficacy is validated across different memristor families and RC configurations. Theoretical analysis not only reveals the general computational mechanism underlying its efficacy, but also underlines its potential applicability to other physical platforms.
PACE: Two-Timescale Self-Evolution for Small Language Model Agents
May 21, 2026Deploying language-model agents in production often requires substantial compute and human effort to tune prompts, parsers, validators, and other components of the agent pipeline. Self-evolution offers a promising alternative, but most existing frameworks assume access to frontier models that can reliably diagnose failures, propose revisions, and judge their own updates. We study whether frozen small language models (SLMs) can serve as effective self-evolving agents under resource constraints. We propose PACE (Prompt And Control Logic Evolution), a two-timescale framework that coordinates low-risk prompt refinement with higher-risk control-logic updates. PACE evolves prompts under fixed control logic until prompt-level gains saturate, then considers constrained control-logic updates that are accepted through held-out validation. Across three frozen SLM backbones ranging from 4B to 14B parameters and four controlled benchmarks, PACE achieves the best performance on all 12 backbone--benchmark combinations, improving over vanilla SLM agents by up to +9.2% relative improvement and over the stronger single-mode evolution baseline by up to +5.4% relative improvement. A tau-bench case study further shows that PACE improves multi-turn tool-use success over vanilla and prompt-only evolution. These results suggest that reliable SLM agent self-evolution is possible without updating model weights or relying on frontier-model teachers, and that the key benefit is not any single final solver pattern but autonomous, validated discovery of task-appropriate inference strategies.
Unveiling the Resilience of LLM-Enhanced Search Engines against Black-Hat SEO Manipulation
Mar 26, 2026The emergence of Large Language Model-enhanced Search Engines (LLMSEs) has revolutionized information retrieval by integrating web-scale search capabilities with AI-powered summarization. While these systems demonstrate improved efficiency over traditional search engines, their security implications against well-established black-hat Search Engine Optimization (SEO) attacks remain unexplored. In this paper, we present the first systematic study of SEO attacks targeting LLMSEs. Specifically, we examine ten representative LLMSE products (e.g., ChatGPT, Gemini) and construct SEO-Bench, a benchmark comprising 1,000 real-world black-hat SEO websites, to evaluate both open- and closed-source LLMSEs. Our measurements show that LLMSEs mitigate over 99.78% of traditional SEO attacks, with the phase of retrieval serving as the primary filter, intercepting the vast majority of malicious queries. We further propose and evaluate seven LLMSEO attack strategies, demonstrating that off-the-shelf LLMSEs are vulnerable to LLMSEO attacks, i.e., rewritten-query stuffing and segmented texts double the manipulation rate compared to the baseline. This work offers the first in-depth security analysis of the LLMSE ecosystem, providing practical insights for building more resilient AI-driven search systems. We have responsibly reported the identified issues to major vendors.
Seeing Eye to Eye: Enabling Cognitive Alignment Through Shared First-Person Perspective in Human-AI Collaboration
Mar 13, 2026Despite advances in multimodal AI, current vision-based assistants often remain inefficient in collaborative tasks. We identify two key gulfs: a communication gulf, where users must translate rich parallel intentions into verbal commands due to the channel mismatch , and an understanding gulf, where AI struggles to interpret subtle embodied cues. To address these, we propose Eye2Eye, a framework that leverages first-person perspective as a channel for human-AI cognitive alignment. It integrates three components: (1) joint attention coordination for fluid focus alignment, (2) revisable memory to maintain evolving common ground, and (3) reflective feedback allowing users to clarify and refine AI's understanding. We implement this framework in an AR prototype and evaluate it through a user study and a post-hoc pipeline evaluation. Results show that Eye2Eye significantly reduces task completion time and interaction load while increasing trust, demonstrating its components work in concert to improve collaboration.
Controllable Video-to-Music Generation with Multiple Time-Varying Conditions
Jul 28, 2025Music enhances video narratives and emotions, driving demand for automatic video-to-music (V2M) generation. However, existing V2M methods relying solely on visual features or supplementary textual inputs generate music in a black-box manner, often failing to meet user expectations. To address this challenge, we propose a novel multi-condition guided V2M generation framework that incorporates multiple time-varying conditions for enhanced control over music generation. Our method uses a two-stage training strategy that enables learning of V2M fundamentals and audiovisual temporal synchronization while meeting users' needs for multi-condition control. In the first stage, we introduce a fine-grained feature selection module and a progressive temporal alignment attention mechanism to ensure flexible feature alignment. For the second stage, we develop a dynamic conditional fusion module and a control-guided decoder module to integrate multiple conditions and accurately guide the music composition process. Extensive experiments demonstrate that our method outperforms existing V2M pipelines in both subjective and objective evaluations, significantly enhancing control and alignment with user expectations.
UniConv: Unifying Retrieval and Response Generation for Large Language Models in Conversations
Jul 09, 2025



The rapid advancement of conversational search systems revolutionizes how information is accessed by enabling the multi-turn interaction between the user and the system. Existing conversational search systems are usually built with two different models. This separation restricts the system from leveraging the intrinsic knowledge of the models simultaneously, which cannot ensure the effectiveness of retrieval benefiting the generation. The existing studies for developing unified models cannot fully address the aspects of understanding conversational context, managing retrieval independently, and generating responses. In this paper, we explore how to unify dense retrieval and response generation for large language models in conversation. We conduct joint fine-tuning with different objectives and design two mechanisms to reduce the inconsistency risks while mitigating data discrepancy. The evaluations on five conversational search datasets demonstrate that our unified model can mutually improve both tasks and outperform the existing baselines.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025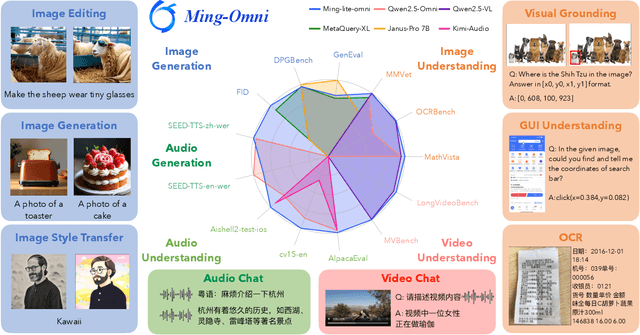
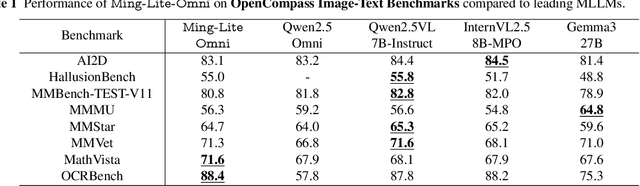
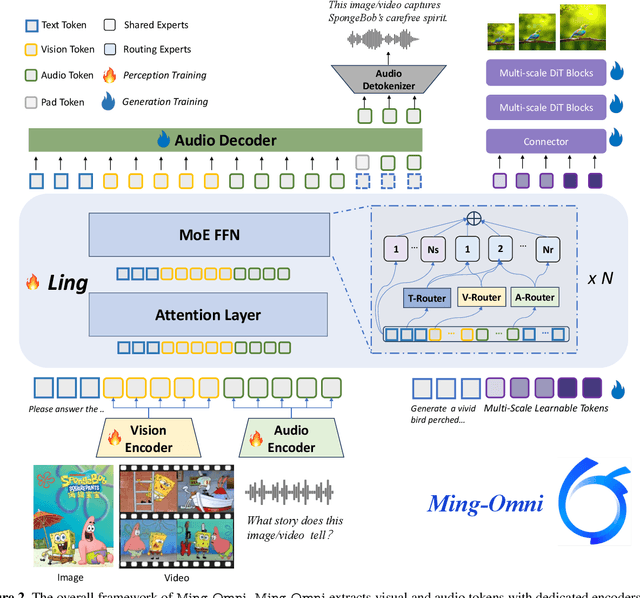
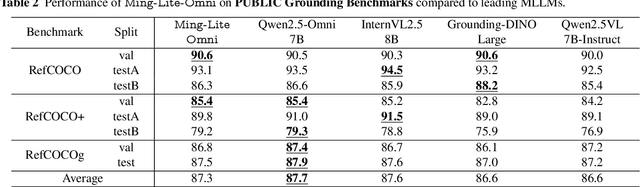
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025



Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
END: Early Noise Dropping for Efficient and Effective Context Denoising
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, they are often distracted by irrelevant or noisy context in input sequences that degrades output quality. This problem affects both long- and short-context scenarios, such as retrieval-augmented generation, table question-answering, and in-context learning. We reveal that LLMs can implicitly identify whether input sequences contain useful information at early layers, prior to token generation. Leveraging this insight, we introduce Early Noise Dropping (\textsc{END}), a novel approach to mitigate this issue without requiring fine-tuning the LLMs. \textsc{END} segments input sequences into chunks and employs a linear prober on the early layers of LLMs to differentiate between informative and noisy chunks. By discarding noisy chunks early in the process, \textsc{END} preserves critical information, reduces distraction, and lowers computational overhead. Extensive experiments demonstrate that \textsc{END} significantly improves both performance and efficiency across different LLMs on multiple evaluation datasets. Furthermore, by investigating LLMs' implicit understanding to the input with the prober, this work also deepens understanding of how LLMs do reasoning with contexts internally.
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.