 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Pose Estimation with Spatial Contextual Information
Jan 07, 2019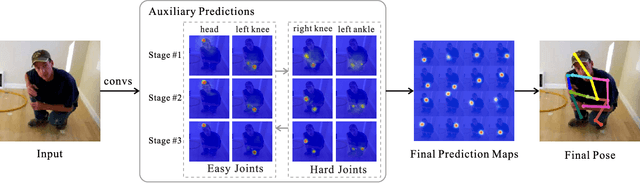
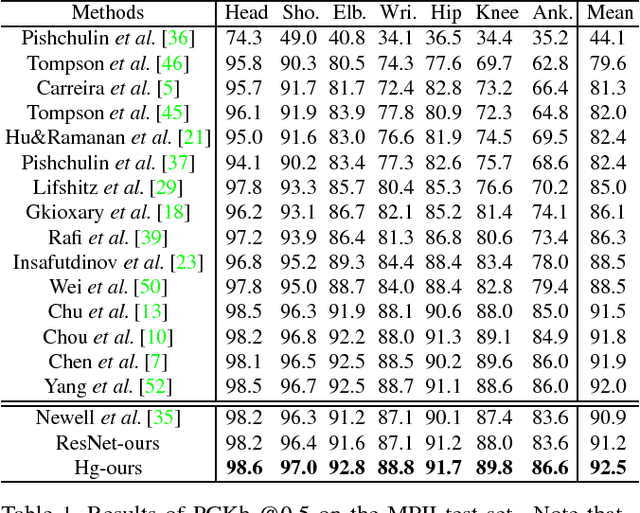
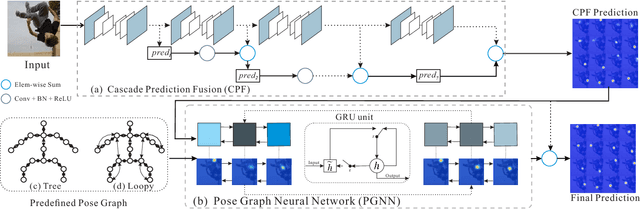
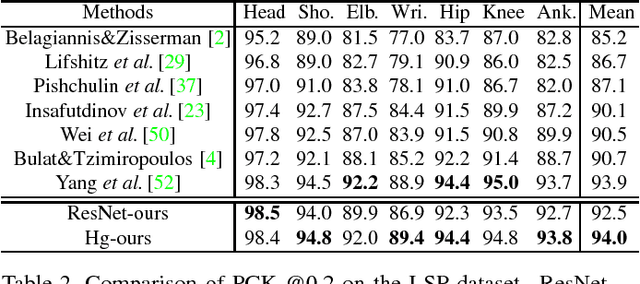
We explore the importance of spatial contextual information in human pose estimation. Most state-of-the-art pose networks are trained in a multi-stage manner and produce several auxiliary predictions for deep supervision. With this principle, we present two conceptually simple and yet computational efficient modules, namely Cascade Prediction Fusion (CPF) and Pose Graph Neural Network (PGNN), to exploit underlying contextual information. Cascade prediction fusion accumulates prediction maps from previous stages to extract informative signals. The resulting maps also function as a prior to guide prediction at following stages. To promote spatial correlation among joints, our PGNN learns a structured representation of human pose as a graph. Direct message passing between different joints is enabled and spatial relation is captured. These two modules require very limited computational complexity. Experimental results demonstrate that our method consistently outperforms previous methods on MPII and LSP benchmark.
ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving
Nov 30, 2018

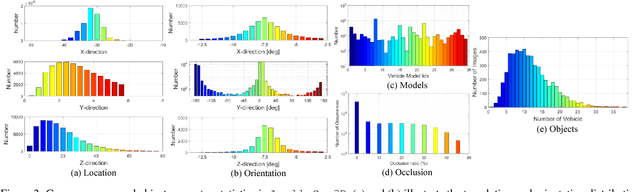
Autonomous driving has attracted remarkable attention from both industry and academia. An important task is to estimate 3D properties(e.g.translation, rotation and shape) of a moving or parked vehicle on the road. This task, while critical, is still under-researched in the computer vision community - partially owing to the lack of large scale and fully-annotated 3D car database suitable for autonomous driving research. In this paper, we contribute the first large-scale database suitable for 3D car instance understanding - ApolloCar3D. The dataset contains 5,277 driving images and over 60K car instances, where each car is fitted with an industry-grade 3D CAD model with absolute model size and semantically labelled keypoints. This dataset is above 20 times larger than PASCAL3D+ and KITTI, the current state-of-the-art. To enable efficient labelling in 3D, we build a pipeline by considering 2D-3D keypoint correspondences for a single instance and 3D relationship among multiple instances. Equipped with such dataset, we build various baseline algorithms with the state-of-the-art deep convolutional neural networks. Specifically, we first segment each car with a pre-trained Mask R-CNN, and then regress towards its 3D pose and shape based on a deformable 3D car model with or without using semantic keypoints. We show that using keypoints significantly improves fitting performance. Finally, we develop a new 3D metric jointly considering 3D pose and 3D shape, allowing for comprehensive evaluation and ablation study. By comparing with human performance we suggest several future directions for further improvements.
Part-level Car Parsing and Reconstruction from Single Street View
Nov 27, 2018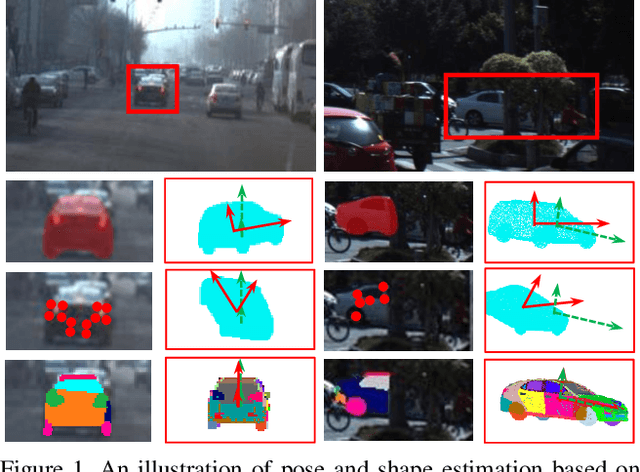
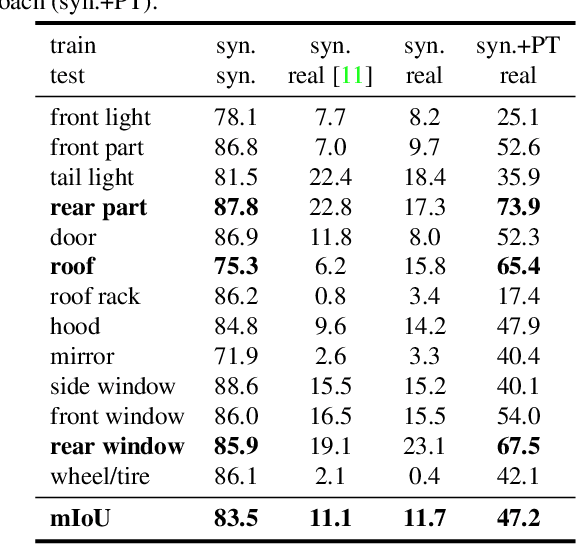
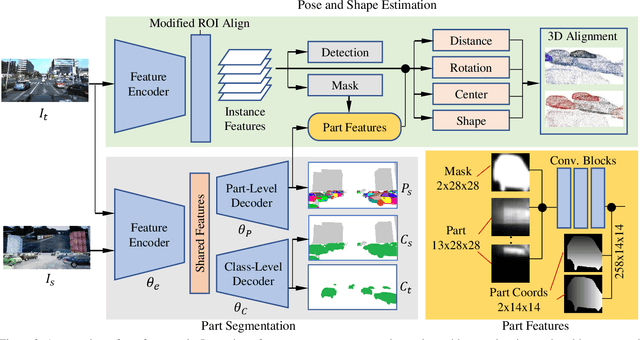
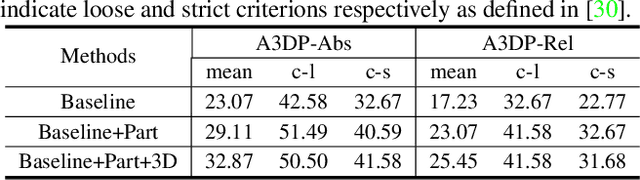
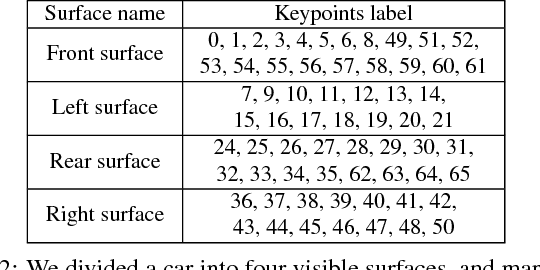
In this paper, we make the first attempt to build a framework to simultaneously estimate semantic parts, shape, translation, and orientation of cars from single street view. Our framework contains three major contributions. Firstly, a novel domain adaptation approach based on the class consistency loss is developed to transfer our part segmentation model from the synthesized images to the real images. Secondly, we propose a novel network structure that leverages part-level features from street views and 3D losses for pose and shape estimation. Thirdly, we construct a high quality dataset that contains more than 300 different car models with physical dimensions and part-level annotations based on global and local deformations. We have conducted experiments on both synthesized data and real images. Our results show that the domain adaptation approach can bring 35.5 percentage point performance improvement in terms of mean intersection-over-union score (mIoU) comparing with the baseline network using domain randomization only. Our network for translation and orientation estimation achieves competitive performance on highly complex street views (e.g., 11 cars per image on average). Moreover, our network is able to reconstruct a list of 3D car models with part-level details from street views, which could benefit various applications such as fine-grained car recognition, vehicle re-identification, and traffic simulation.
Simulating LIDAR Point Cloud for Autonomous Driving using Real-world Scenes and Traffic Flows
Nov 17, 2018



We present a LIDAR simulation framework that can automatically generate 3D point cloud based on LIDAR type and placement. The point cloud, annotated with ground truth semantic labels, is to be used as training data to improve environmental perception capabilities for autonomous driving vehicles. Different from previous simulators, we generate the point cloud based on real environment and real traffic flow. More specifically we employ a mobile LIDAR scanner with cameras to capture real world scenes. The input to our simulation framework includes dense 3D point cloud and registered color images. Moving objects (such as cars, pedestrians, bicyclists) are automatically identified and recorded. These objects are then removed from the input point cloud to restore a static background (e.g., environment without movable objects). With that we can insert synthetic models of various obstacles, such as vehicles and pedestrians in the static background to create various traffic scenes. A novel LIDAR renderer takes the composite scene to generate new realistic LIDAR points that are already annotated at point level for synthetic objects. Experimental results show that our system is able to close the performance gap between simulation and real data to be 1 ~ 6% in different applications, and for model fine tuning, only 10% ~ 20% extra real data could help to outperform the original model trained with full real dataset.
Getting Robots Unfrozen and Unlost in Dense Pedestrian Crowds
Sep 30, 2018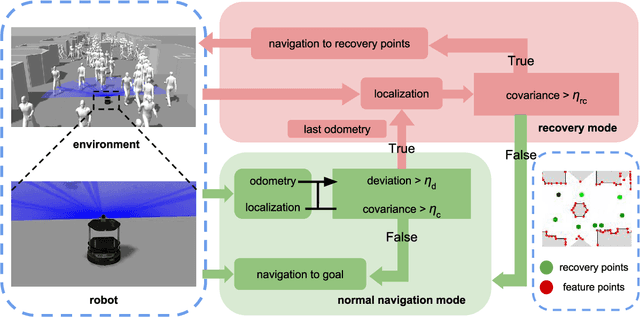
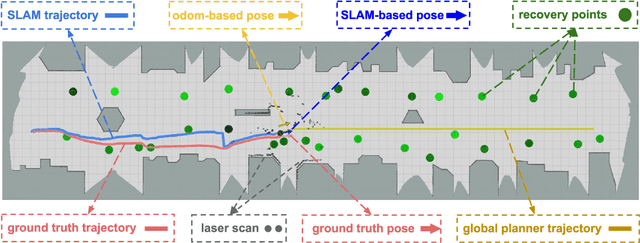
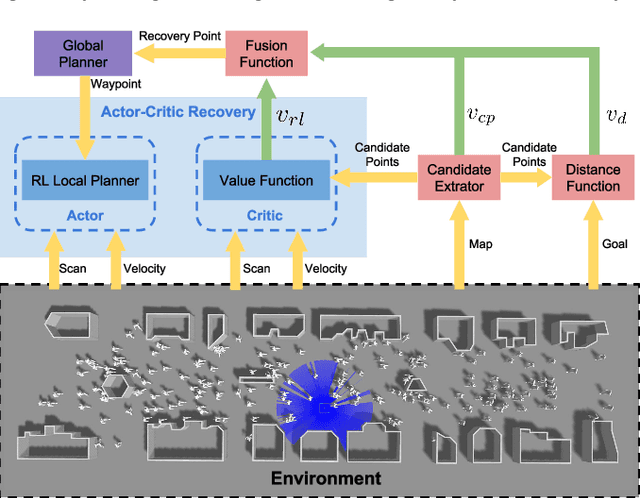
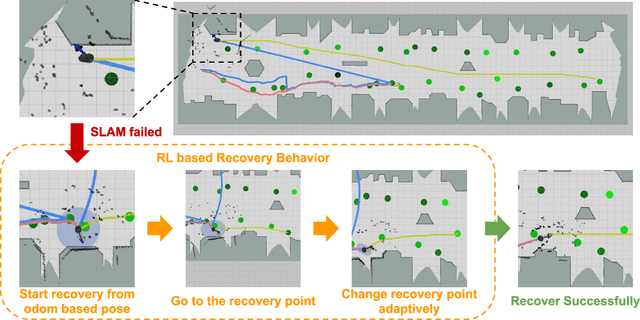
We aim to enable a mobile robot to navigate through environments with dense crowds, e.g., shopping malls, canteens, train stations, or airport terminals. In these challenging environments, existing approaches suffer from two common problems: the robot may get frozen and cannot make any progress toward its goal, or it may get lost due to severe occlusions inside a crowd. Here we propose a navigation framework that handles the robot freezing and the navigation lost problems simultaneously. First, we enhance the robot's mobility and unfreeze the robot in the crowd using a reinforcement learning based local navigation policy developed in our previous work~\cite{long2017towards}, which naturally takes into account the coordination between the robot and the human. Secondly, the robot takes advantage of its excellent local mobility to recover from its localization failure. In particular, it dynamically chooses to approach a set of recovery positions with rich features. To the best of our knowledge, our method is the first approach that simultaneously solves the freezing problem and the navigation lost problem in dense crowds. We evaluate our method in both simulated and real-world environments and demonstrate that it outperforms the state-of-the-art approaches. Videos are available at https://sites.google.com/view/rlslam.
The ApolloScape Open Dataset for Autonomous Driving and its Application
Sep 26, 2018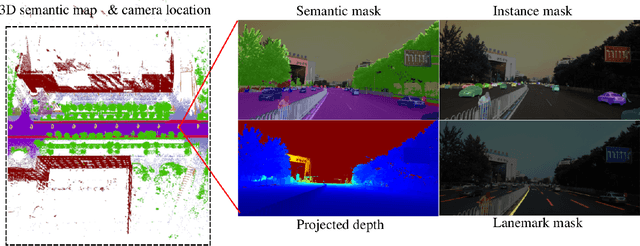
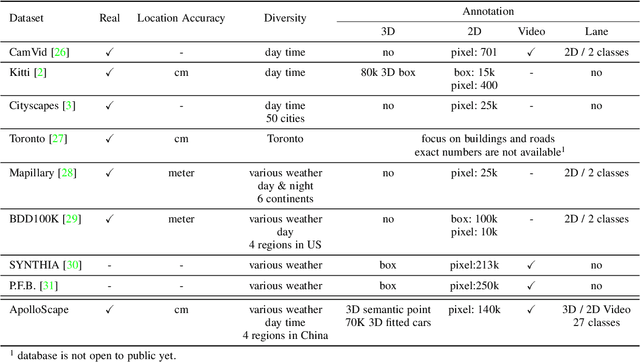
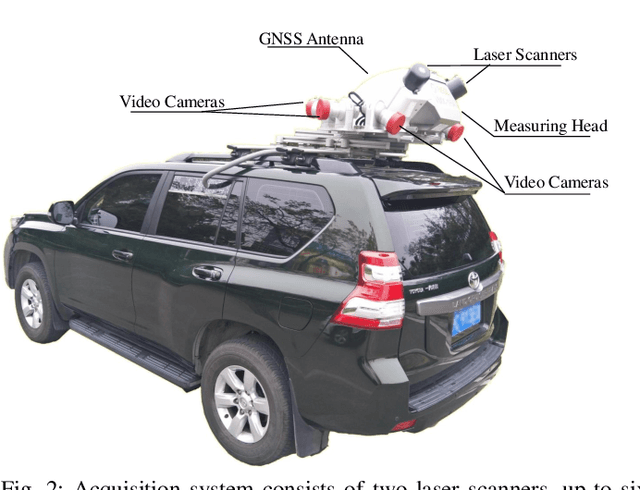
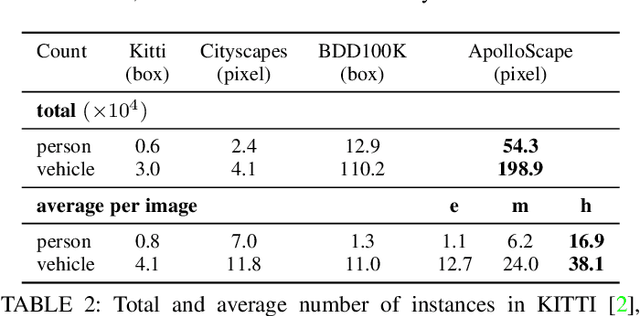
Autonomous driving has attracted tremendous attention especially in the past few years. The key techniques for a self-driving car include solving tasks like 3D map construction, self-localization, parsing the driving road and understanding objects, which enable vehicles to reason and act. However, large scale data set for training and system evaluation is still a bottleneck for developing robust perception models. In this paper, we present the ApolloScape dataset [1] and its applications for autonomous driving. Compared with existing public datasets from real scenes, e.g. KITTI [2] or Cityscapes [3], ApolloScape contains much large and richer labelling including holistic semantic dense point cloud for each site, stereo, per-pixel semantic labelling, lanemark labelling, instance segmentation, 3D car instance, high accurate location for every frame in various driving videos from multiple sites, cities and daytimes. For each task, it contains at lease 15x larger amount of images than SOTA datasets. To label such a complete dataset, we develop various tools and algorithms specified for each task to accelerate the labelling process, such as 3D-2D segment labeling tools, active labelling in videos etc. Depend on ApolloScape, we are able to develop algorithms jointly consider the learning and inference of multiple tasks. In this paper, we provide a sensor fusion scheme integrating camera videos, consumer-grade motion sensors (GPS/IMU), and a 3D semantic map in order to achieve robust self-localization and semantic segmentation for autonomous driving. We show that practically, sensor fusion and joint learning of multiple tasks are beneficial to achieve a more robust and accurate system. We expect our dataset and proposed relevant algorithms can support and motivate researchers for further development of multi-sensor fusion and multi-task learning in the field of computer vision.
Safe Navigation with Human Instructions in Complex Scenes
Sep 12, 2018
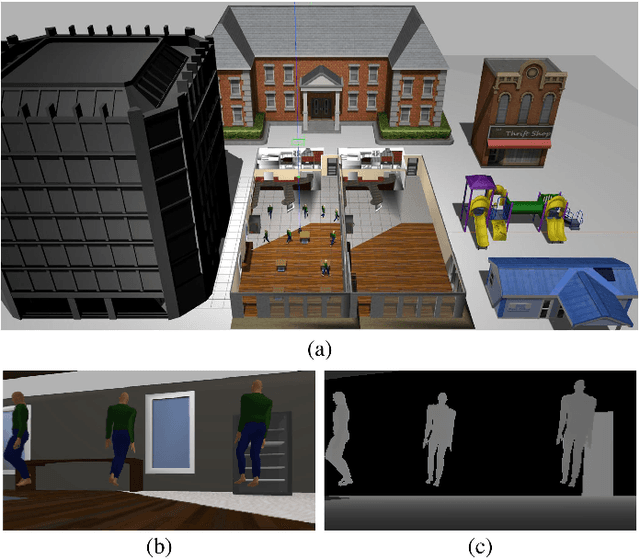
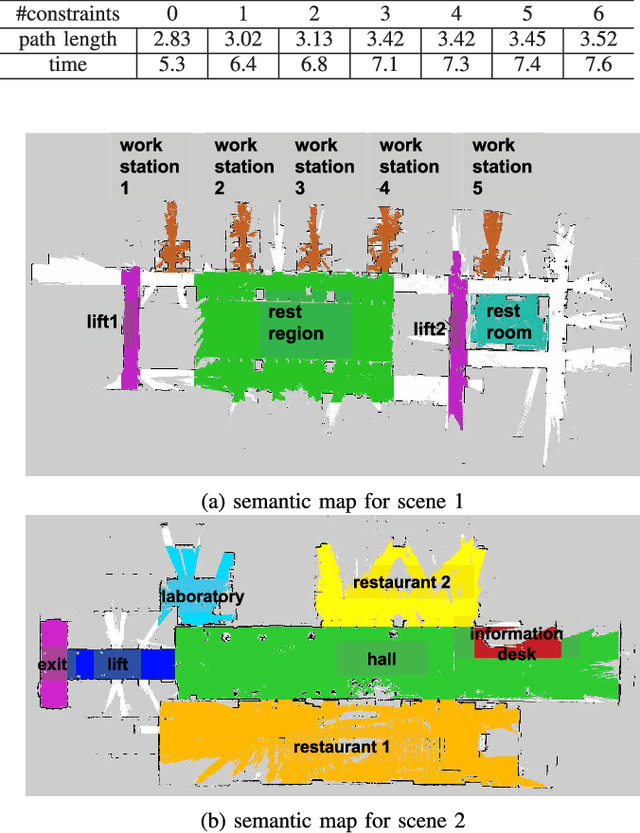
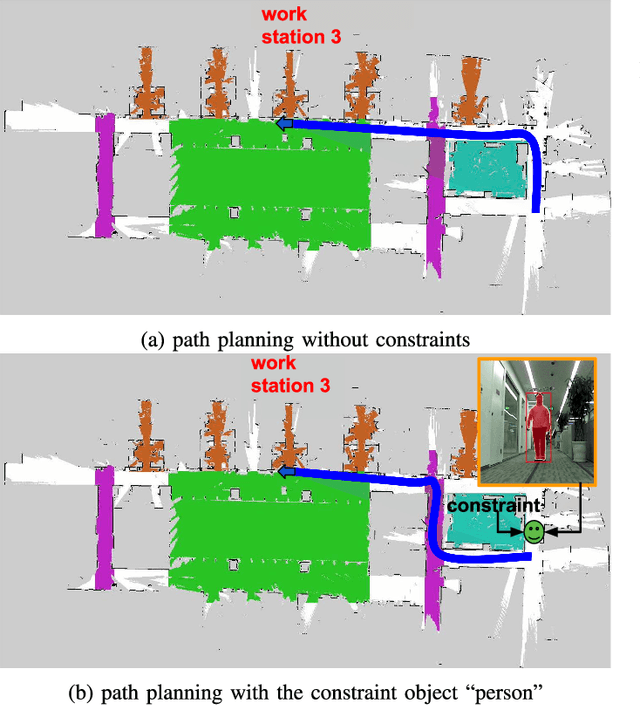
In this paper, we present a robotic navigation algorithm with natural language interfaces, which enables a robot to safely walk through a changing environment with moving persons by following human instructions such as "go to the restaurant and keep away from people". We first classify human instructions into three types: the goal, the constraints, and uninformative phrases. Next, we provide grounding for the extracted goal and constraint items in a dynamic manner along with the navigation process, to deal with the target objects that are too far away for sensor observation and the appearance of moving obstacles like humans. In particular, for a goal phrase (e.g., "go to the restaurant"), we ground it to a location in a predefined semantic map and treat it as a goal for a global motion planner, which plans a collision-free path in the workspace for the robot to follow. For a constraint phrase (e.g., "keep away from people"), we dynamically add the corresponding constraint into a local planner by adjusting the values of a local costmap according to the results returned by the object detection module. The updated costmap is then used to compute a local collision avoidance control for the safe navigation of the robot. By combining natural language processing, motion planning, and computer vision, our developed system is demonstrated to be able to successfully follow natural language navigation instructions to achieve navigation tasks in both simulated and real-world scenarios. Videos are available at https://sites.google.com/view/snhi
RealPoint3D: Point Cloud Generation from a Single Image with Complex Background
Sep 08, 2018
3D point cloud generation by the deep neural network from a single image has been attracting more and more researchers' attention. However, recently-proposed methods require the objects be captured with relatively clean backgrounds, fixed viewpoint, while this highly limits its application in the real environment. To overcome these drawbacks, we proposed to integrate the prior 3D shape knowledge into the network to guide the 3D generation. By taking additional 3D information, the proposed network can handle the 3D object generation from a single real image captured from any viewpoint and complex background. Specifically, giving a query image, we retrieve the nearest shape model from a pre-prepared 3D model database. Then, the image together with the retrieved shape model is fed into the proposed network to generate the fine-grained 3D point cloud. The effectiveness of our proposed framework has been verified on different kinds of datasets. Experimental results show that the proposed framework achieves state-of-the-art accuracy compared to other volumetric-based and point set generation methods. Furthermore, the proposed framework works well for real images in complex backgrounds with various view angles.
A Network Structure to Explicitly Reduce Confusion Errors in Semantic Segmentation
Aug 01, 2018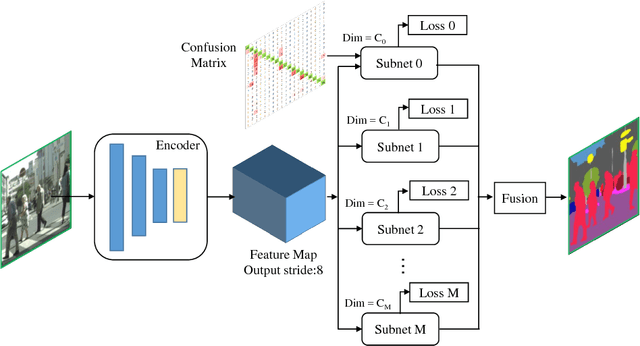
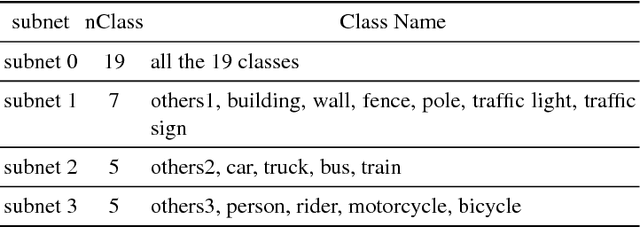
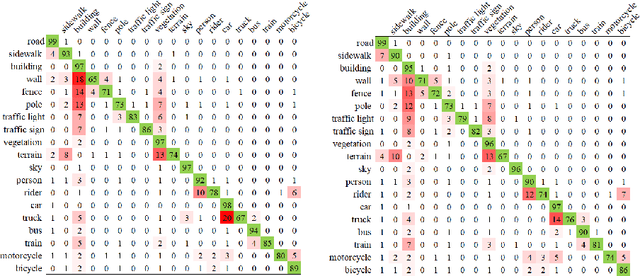
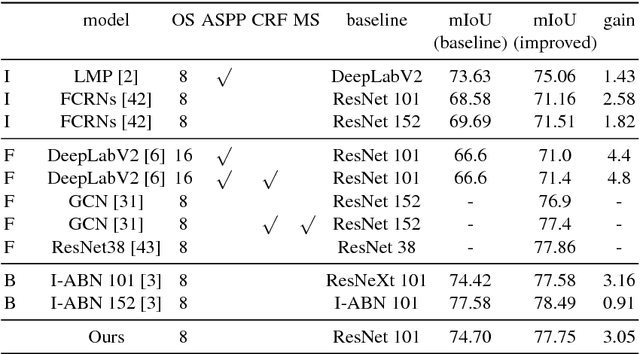
Confusing classes that are ubiquitous in real world often degrade performance for many vision related applications like object detection, classification, and segmentation. The confusion errors are not only caused by similar visual patterns but also amplified by various factors during the training of our designed models, such as reduced feature resolution in the encoding process or imbalanced data distributions. A large amount of deep learning based network structures has been proposed in recent years to deal with these individual factors and improve network performance. However, to our knowledge, no existing work in semantic image segmentation is designed to tackle confusion errors explicitly. In this paper, we present a novel and general network structure that reduces confusion errors in more direct manner and apply the network for semantic segmentation. There are two major contributions in our network structure: 1) We ensemble subnets with heterogeneous output spaces based on the discriminative confusing groups. The training for each subnet can distinguish confusing classes within the group without affecting unrelated classes outside the group. 2) We propose an improved cross-entropy loss function that maximizes the probability assigned to the correct class and penalizes the probabilities assigned to the confusing classes at the same time. Our network structure is a general structure and can be easily adapted to any other networks to further reduce confusion errors. Without any changes in the feature encoder and post-processing steps, our experiments demonstrate consistent and significant improvements on different baseline models on Cityscapes and PASCAL VOC datasets (e.g., 3.05% over ResNet-101 and 1.30% over ResNet-38).
Depth Estimation via Affinity Learned with Convolutional Spatial Propagation Network
Aug 01, 2018
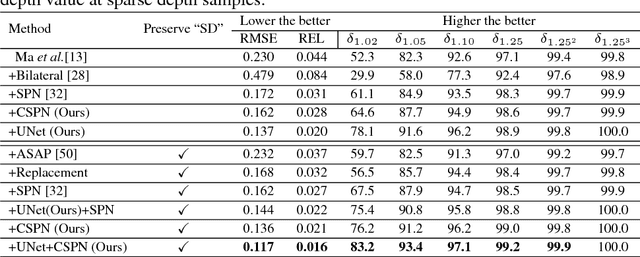
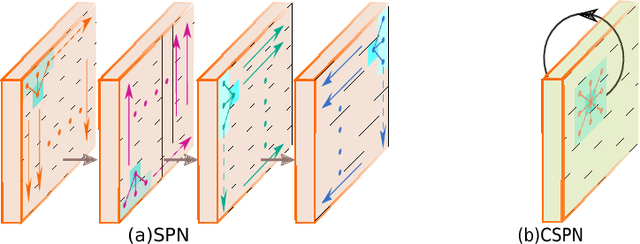
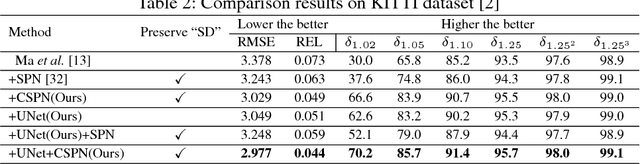
Depth estimation from a single image is a fundamental problem in computer vision. In this paper, we propose a simple yet effective convolutional spatial propagation network (CSPN) to learn the affinity matrix for depth prediction. Specifically, we adopt an efficient linear propagation model, where the propagation is performed with a manner of recurrent convolutional operation, and the affinity among neighboring pixels is learned through a deep convolutional neural network (CNN). We apply the designed CSPN to two depth estimation tasks given a single image: (1) To refine the depth output from state-of-the-art (SOTA) existing methods; and (2) to convert sparse depth samples to a dense depth map by embedding the depth samples within the propagation procedure. The second task is inspired by the availability of LIDARs that provides sparse but accurate depth measurements. We experimented the proposed CSPN over two popular benchmarks for depth estimation, i.e. NYU v2 and KITTI, where we show that our proposed approach improves in not only quality (e.g., 30% more reduction in depth error), but also speed (e.g., 2 to 5 times faster) than prior SOTA methods.