 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAION: Aerial Indoor Object-Goal Navigation Using Dual-Policy Reinforcement Learning
Jan 22, 2026Object-Goal Navigation (ObjectNav) requires an agent to autonomously explore an unknown environment and navigate toward target objects specified by a semantic label. While prior work has primarily studied zero-shot ObjectNav under 2D locomotion, extending it to aerial platforms with 3D locomotion capability remains underexplored. Aerial robots offer superior maneuverability and search efficiency, but they also introduce new challenges in spatial perception, dynamic control, and safety assurance. In this paper, we propose AION for vision-based aerial ObjectNav without relying on external localization or global maps. AION is an end-to-end dual-policy reinforcement learning (RL) framework that decouples exploration and goal-reaching behaviors into two specialized policies. We evaluate AION on the AI2-THOR benchmark and further assess its real-time performance in IsaacSim using high-fidelity drone models. Experimental results show that AION achieves superior performance across comprehensive evaluation metrics in exploration, navigation efficiency, and safety. The video can be found at https://youtu.be/TgsUm6bb7zg.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
TransforMARS: Fault-Tolerant Self-Reconfiguration for Arbitrarily Shaped Modular Aerial Robot Systems
Sep 17, 2025Modular Aerial Robot Systems (MARS) consist of multiple drone modules that are physically bound together to form a single structure for flight. Exploiting structural redundancy, MARS can be reconfigured into different formations to mitigate unit or rotor failures and maintain stable flight. Prior work on MARS self-reconfiguration has solely focused on maximizing controllability margins to tolerate a single rotor or unit fault for rectangular-shaped MARS. We propose TransforMARS, a general fault-tolerant reconfiguration framework that transforms arbitrarily shaped MARS under multiple rotor and unit faults while ensuring continuous in-air stability. Specifically, we develop algorithms to first identify and construct minimum controllable assemblies containing faulty units. We then plan feasible disassembly-assembly sequences to transport MARS units or subassemblies to form target configuration. Our approach enables more flexible and practical feasible reconfiguration. We validate TransforMARS in challenging arbitrarily shaped MARS configurations, demonstrating substantial improvements over prior works in both the capacity of handling diverse configurations and the number of faults tolerated. The videos and source code of this work are available at the anonymous repository: https://anonymous.4open.science/r/TransforMARS-1030/
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
SIGN: Safety-Aware Image-Goal Navigation for Autonomous Drones via Reinforcement Learning
Aug 17, 2025Image-goal navigation (ImageNav) tasks a robot with autonomously exploring an unknown environment and reaching a location that visually matches a given target image. While prior works primarily study ImageNav for ground robots, enabling this capability for autonomous drones is substantially more challenging due to their need for high-frequency feedback control and global localization for stable flight. In this paper, we propose a novel sim-to-real framework that leverages visual reinforcement learning (RL) to achieve ImageNav for drones. To enhance visual representation ability, our approach trains the vision backbone with auxiliary tasks, including image perturbations and future transition prediction, which results in more effective policy training. The proposed algorithm enables end-to-end ImageNav with direct velocity control, eliminating the need for external localization. Furthermore, we integrate a depth-based safety module for real-time obstacle avoidance, allowing the drone to safely navigate in cluttered environments. Unlike most existing drone navigation methods that focus solely on reference tracking or obstacle avoidance, our framework supports comprehensive navigation behaviors--autonomous exploration, obstacle avoidance, and image-goal seeking--without requiring explicit global mapping. Code and model checkpoints will be released upon acceptance.
Video Perception Models for 3D Scene Synthesis
Jun 25, 2025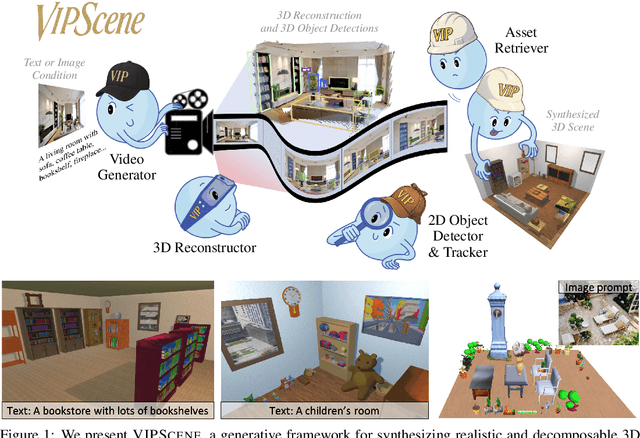



Traditionally, 3D scene synthesis requires expert knowledge and significant manual effort. Automating this process could greatly benefit fields such as architectural design, robotics simulation, virtual reality, and gaming. Recent approaches to 3D scene synthesis often rely on the commonsense reasoning of large language models (LLMs) or strong visual priors of modern image generation models. However, current LLMs demonstrate limited 3D spatial reasoning ability, which restricts their ability to generate realistic and coherent 3D scenes. Meanwhile, image generation-based methods often suffer from constraints in viewpoint selection and multi-view inconsistencies. In this work, we present Video Perception models for 3D Scene synthesis (VIPScene), a novel framework that exploits the encoded commonsense knowledge of the 3D physical world in video generation models to ensure coherent scene layouts and consistent object placements across views. VIPScene accepts both text and image prompts and seamlessly integrates video generation, feedforward 3D reconstruction, and open-vocabulary perception models to semantically and geometrically analyze each object in a scene. This enables flexible scene synthesis with high realism and structural consistency. For more precise analysis, we further introduce First-Person View Score (FPVScore) for coherence and plausibility evaluation, utilizing continuous first-person perspective to capitalize on the reasoning ability of multimodal large language models. Extensive experiments show that VIPScene significantly outperforms existing methods and generalizes well across diverse scenarios. The code will be released.
3D-SSM: A Novel 3D Selective Scan Module for Remote Sensing Change Detection
Jun 24, 2025Existing Mamba-based approaches in remote sensing change detection have enhanced scanning models, yet remain limited by their inability to capture long-range dependencies between image channels effectively, which restricts their feature representation capabilities. To address this limitation, we propose a 3D selective scan module (3D-SSM) that captures global information from both the spatial plane and channel perspectives, enabling a more comprehensive understanding of the data.Based on the 3D-SSM, we present two key components: a spatiotemporal interaction module (SIM) and a multi-branch feature extraction module (MBFEM). The SIM facilitates bi-temporal feature integration by enabling interactions between global and local features across images from different time points, thereby enhancing the detection of subtle changes. Meanwhile, the MBFEM combines features from the frequency domain, spatial domain, and 3D-SSM to provide a rich representation of contextual information within the image. Our proposed method demonstrates favourable performance compared to state-of-the-art change detection methods on five benchmark datasets through extensive experiments. Code is available at https://github.com/VerdantMist/3D-SSM
Self-Supervised Enhancement for Depth from a Lightweight ToF Sensor with Monocular Images
Jun 16, 2025Depth map enhancement using paired high-resolution RGB images offers a cost-effective solution for improving low-resolution depth data from lightweight ToF sensors. Nevertheless, naively adopting a depth estimation pipeline to fuse the two modalities requires groundtruth depth maps for supervision. To address this, we propose a self-supervised learning framework, SelfToF, which generates detailed and scale-aware depth maps. Starting from an image-based self-supervised depth estimation pipeline, we add low-resolution depth as inputs, design a new depth consistency loss, propose a scale-recovery module, and finally obtain a large performance boost. Furthermore, since the ToF signal sparsity varies in real-world applications, we upgrade SelfToF to SelfToF* with submanifold convolution and guided feature fusion. Consequently, SelfToF* maintain robust performance across varying sparsity levels in ToF data. Overall, our proposed method is both efficient and effective, as verified by extensive experiments on the NYU and ScanNet datasets. The code will be made public.