 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS-Dragonfly: Agile and Robust Flight Control of Modular Aerial Robot Systems
Apr 07, 2026Modular Aerial Robot Systems (MARS) comprise multiple drone units with reconfigurable connected formations, providing high adaptability to diverse mission scenarios, fault conditions, and payload capacities. However, existing control algorithms for MARS rely on simplified quasi-static models and rule-based allocation, which generate discontinuous and unbounded motor commands. This leads to attitude error accumulation as the number of drone units scales, ultimately causing severe oscillations during docking, separation, and waypoint tracking. To address these limitations, we first design a compact mechanical system that enables passive docking, detection-free passive locking, and magnetic-assisted separation using a single micro servo. Second, we introduce a force-torque-equivalent and polytope-constraint virtual quadrotor that explicitly models feasible wrench sets. Together, these abstractions capture the full MARS dynamics and enable existing quadrotor controllers to be applied across different configurations. We further optimize the yaw angle that maximizes control authority to enhance agility. Third, building on this abstraction, we design a two-stage predictive-allocation pipeline: a constrained predictive tracker computes virtual inputs while respecting force/torque bounds, and a dynamic allocator maps these inputs to individual modules with balanced objectives to produce smooth, trackable motor commands. Simulations across over 10 configurations and real-world experiments demonstrate stable docking, locking, and separation, as well as effective control performance. To our knowledge, this is the first real-world demonstration of MARS achieving agile flight and transport with 40 deg peak pitch while maintaining an average position error of 0.0896 m. The video is available at: https://youtu.be/yqjccrIpz5o
Training-free Detection and 6D Pose Estimation of Unseen Surgical Instruments
Mar 26, 2026Purpose: Accurate detection and 6D pose estimation of surgical instruments are crucial for many computer-assisted interventions. However, supervised methods lack flexibility for new or unseen tools and require extensive annotated data. This work introduces a training-free pipeline for accurate multi-view 6D pose estimation of unseen surgical instruments, which only requires a textured CAD model as prior knowledge. Methods: Our pipeline consists of two main stages. First, for detection, we generate object mask proposals in each view and score their similarity to rendered templates using a pre-trained feature extractor. Detections are matched across views, triangulated into 3D instance candidates, and filtered using multi-view geometric consistency. Second, for pose estimation, a set of pose hypotheses is iteratively refined and scored using feature-metric scores with cross-view attention. The best hypothesis undergoes a final refinement using a novel multi-view, occlusion-aware contour registration, which minimizes reprojection errors of unoccluded contour points. Results: The proposed method was rigorously evaluated on real-world surgical data from the MVPSP dataset. The method achieves millimeter-accurate pose estimates that are on par with supervised methods under controlled conditions, while maintaining full generalization to unseen instruments. These results demonstrate the feasibility of training-free, marker-less detection and tracking in surgical scenes, and highlight the unique challenges in surgical environments. Conclusion: We present a novel and flexible pipeline that effectively combines state-of-the-art foundational models, multi-view geometry, and contour-based refinement for high-accuracy 6D pose estimation of surgical instruments without task-specific training. This approach enables robust instrument tracking and scene understanding in dynamic clinical environments.
Feed-forward Gaussian Registration for Head Avatar Creation and Editing
Mar 16, 2026We present MATCH (Multi-view Avatars from Topologically Corresponding Heads), a multi-view Gaussian registration method for high-quality head avatar creation and editing. State-of-the-art multi-view head avatar methods require time-consuming head tracking followed by expensive avatar optimization, often resulting in a total creation time of more than one day. MATCH, in contrast, directly predicts Gaussian splat textures in correspondence from calibrated multi-view images in just 0.5 seconds per frame, without requiring data preprocessing. The learned intra-subject correspondence across frames enables fast creation of personalized head avatars, while correspondence across subjects supports applications such as expression transfer, optimization-free tracking, semantic editing, and identity interpolation. We establish these correspondences end-to-end using a transformer-based model that predicts Gaussian splat textures in the fixed UV layout of a template mesh. To achieve this, we introduce a novel registration-guided attention block, where each UV-map token attends exclusively to image tokens depicting its corresponding mesh region. This design improves efficiency and performance compared to dense cross-view attention. MATCH outperforms existing methods in novel-view synthesis, geometry registration, and head avatar generation, while making avatar creation 10 times faster than the closest competing baseline. The code and model weights are available on the project website.
GGPT: Geometry Grounded Point Transformer
Mar 11, 2026Recent feed-forward networks have achieved remarkable progress in sparse-view 3D reconstruction by predicting dense point maps directly from RGB images. However, they often suffer from geometric inconsistencies and limited fine-grained accuracy due to the absence of explicit multi-view constraints. We introduce the Geometry-Grounded Point Transformer (GGPT), a framework that augments feed-forward reconstruction with reliable sparse geometric guidance. We first propose an improved Structure-from-Motion pipeline based on dense feature matching and lightweight geometric optimisation to efficiently estimate accurate camera poses and partial 3D point clouds from sparse input views. Building on this foundation, we propose a geometry-guided 3D point transformer that refines dense point maps under explicit partial-geometry supervision using an optimised guidance encoding. Extensive experiments demonstrate that our method provides a principled mechanism for integrating geometric priors with dense feed-forward predictions, producing reconstructions that are both geometrically consistent and spatially complete, recovering fine structures and filling gaps in textureless areas. Trained solely on ScanNet++ with VGGT predictions, GGPT generalises across architectures and datasets, substantially outperforming state-of-the-art feed-forward 3D reconstruction models in both in-domain and out-of-domain settings.
Masked Modeling for Human Motion Recovery Under Occlusions
Jan 23, 2026Human motion reconstruction from monocular videos is a fundamental challenge in computer vision, with broad applications in AR/VR, robotics, and digital content creation, but remains challenging under frequent occlusions in real-world settings. Existing regression-based methods are efficient but fragile to missing observations, while optimization- and diffusion-based approaches improve robustness at the cost of slow inference speed and heavy preprocessing steps. To address these limitations, we leverage recent advances in generative masked modeling and present MoRo: Masked Modeling for human motion Recovery under Occlusions. MoRo is an occlusion-robust, end-to-end generative framework that formulates motion reconstruction as a video-conditioned task, and efficiently recover human motion in a consistent global coordinate system from RGB videos. By masked modeling, MoRo naturally handles occlusions while enabling efficient, end-to-end inference. To overcome the scarcity of paired video-motion data, we design a cross-modality learning scheme that learns multi-modal priors from a set of heterogeneous datasets: (i) a trajectory-aware motion prior trained on MoCap datasets, (ii) an image-conditioned pose prior trained on image-pose datasets, capturing diverse per-frame poses, and (iii) a video-conditioned masked transformer that fuses motion and pose priors, finetuned on video-motion datasets to integrate visual cues with motion dynamics for robust inference. Extensive experiments on EgoBody and RICH demonstrate that MoRo substantially outperforms state-of-the-art methods in accuracy and motion realism under occlusions, while performing on-par in non-occluded scenarios. MoRo achieves real-time inference at 70 FPS on a single H200 GPU.
TransforMARS: Fault-Tolerant Self-Reconfiguration for Arbitrarily Shaped Modular Aerial Robot Systems
Sep 17, 2025Modular Aerial Robot Systems (MARS) consist of multiple drone modules that are physically bound together to form a single structure for flight. Exploiting structural redundancy, MARS can be reconfigured into different formations to mitigate unit or rotor failures and maintain stable flight. Prior work on MARS self-reconfiguration has solely focused on maximizing controllability margins to tolerate a single rotor or unit fault for rectangular-shaped MARS. We propose TransforMARS, a general fault-tolerant reconfiguration framework that transforms arbitrarily shaped MARS under multiple rotor and unit faults while ensuring continuous in-air stability. Specifically, we develop algorithms to first identify and construct minimum controllable assemblies containing faulty units. We then plan feasible disassembly-assembly sequences to transport MARS units or subassemblies to form target configuration. Our approach enables more flexible and practical feasible reconfiguration. We validate TransforMARS in challenging arbitrarily shaped MARS configurations, demonstrating substantial improvements over prior works in both the capacity of handling diverse configurations and the number of faults tolerated. The videos and source code of this work are available at the anonymous repository: https://anonymous.4open.science/r/TransforMARS-1030/
Multi-View 3D Point Tracking
Aug 28, 2025We introduce the first data-driven multi-view 3D point tracker, designed to track arbitrary points in dynamic scenes using multiple camera views. Unlike existing monocular trackers, which struggle with depth ambiguities and occlusion, or prior multi-camera methods that require over 20 cameras and tedious per-sequence optimization, our feed-forward model directly predicts 3D correspondences using a practical number of cameras (e.g., four), enabling robust and accurate online tracking. Given known camera poses and either sensor-based or estimated multi-view depth, our tracker fuses multi-view features into a unified point cloud and applies k-nearest-neighbors correlation alongside a transformer-based update to reliably estimate long-range 3D correspondences, even under occlusion. We train on 5K synthetic multi-view Kubric sequences and evaluate on two real-world benchmarks: Panoptic Studio and DexYCB, achieving median trajectory errors of 3.1 cm and 2.0 cm, respectively. Our method generalizes well to diverse camera setups of 1-8 views with varying vantage points and video lengths of 24-150 frames. By releasing our tracker alongside training and evaluation datasets, we aim to set a new standard for multi-view 3D tracking research and provide a practical tool for real-world applications. Project page available at https://ethz-vlg.github.io/mvtracker.
Spline Deformation Field
Jul 10, 2025



Trajectory modeling of dense points usually employs implicit deformation fields, represented as neural networks that map coordinates to relate canonical spatial positions to temporal offsets. However, the inductive biases inherent in neural networks can hinder spatial coherence in ill-posed scenarios. Current methods focus either on enhancing encoding strategies for deformation fields, often resulting in opaque and less intuitive models, or adopt explicit techniques like linear blend skinning, which rely on heuristic-based node initialization. Additionally, the potential of implicit representations for interpolating sparse temporal signals remains under-explored. To address these challenges, we propose a spline-based trajectory representation, where the number of knots explicitly determines the degrees of freedom. This approach enables efficient analytical derivation of velocities, preserving spatial coherence and accelerations, while mitigating temporal fluctuations. To model knot characteristics in both spatial and temporal domains, we introduce a novel low-rank time-variant spatial encoding, replacing conventional coupled spatiotemporal techniques. Our method demonstrates superior performance in temporal interpolation for fitting continuous fields with sparse inputs. Furthermore, it achieves competitive dynamic scene reconstruction quality compared to state-of-the-art methods while enhancing motion coherence without relying on linear blend skinning or as-rigid-as-possible constraints.
EgoM2P: Egocentric Multimodal Multitask Pretraining
Jun 09, 2025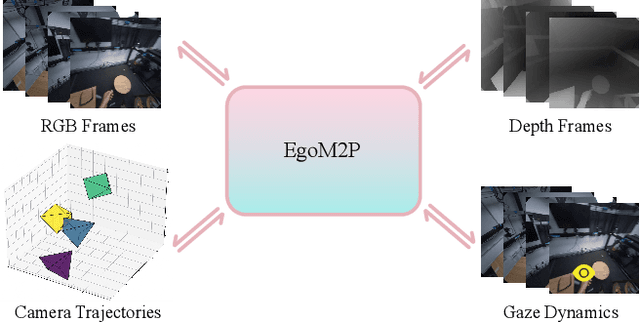

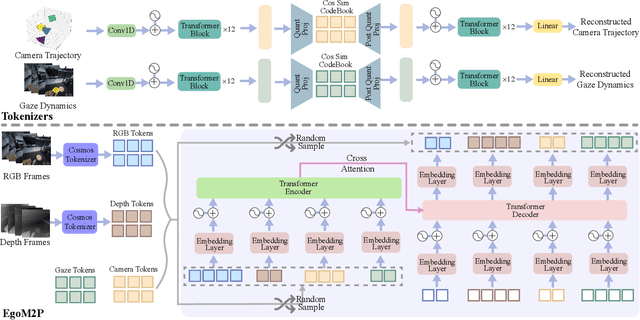
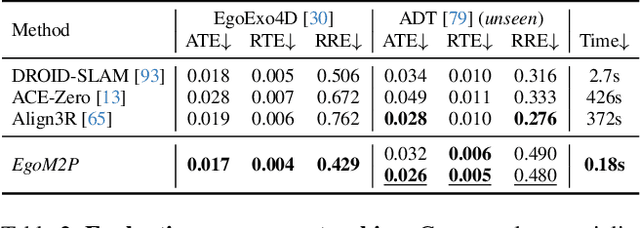
Understanding multimodal signals in egocentric vision, such as RGB video, depth, camera poses, and gaze, is essential for applications in augmented reality, robotics, and human-computer interaction. These capabilities enable systems to better interpret the camera wearer's actions, intentions, and surrounding environment. However, building large-scale egocentric multimodal and multitask models presents unique challenges. Egocentric data are inherently heterogeneous, with large variations in modality coverage across devices and settings. Generating pseudo-labels for missing modalities, such as gaze or head-mounted camera trajectories, is often infeasible, making standard supervised learning approaches difficult to scale. Furthermore, dynamic camera motion and the complex temporal and spatial structure of first-person video pose additional challenges for the direct application of existing multimodal foundation models. To address these challenges, we introduce a set of efficient temporal tokenizers and propose EgoM2P, a masked modeling framework that learns from temporally aware multimodal tokens to train a large, general-purpose model for egocentric 4D understanding. This unified design supports multitasking across diverse egocentric perception and synthesis tasks, including gaze prediction, egocentric camera tracking, and monocular depth estimation from egocentric video. EgoM2P also serves as a generative model for conditional egocentric video synthesis. Across these tasks, EgoM2P matches or outperforms specialist models while being an order of magnitude faster. We will fully open-source EgoM2P to support the community and advance egocentric vision research. Project page: https://egom2p.github.io/
Text-based Animatable 3D Avatars with Morphable Model Alignment
Apr 22, 2025The generation of high-quality, animatable 3D head avatars from text has enormous potential in content creation applications such as games, movies, and embodied virtual assistants. Current text-to-3D generation methods typically combine parametric head models with 2D diffusion models using score distillation sampling to produce 3D-consistent results. However, they struggle to synthesize realistic details and suffer from misalignments between the appearance and the driving parametric model, resulting in unnatural animation results. We discovered that these limitations stem from ambiguities in the 2D diffusion predictions during 3D avatar distillation, specifically: i) the avatar's appearance and geometry is underconstrained by the text input, and ii) the semantic alignment between the predictions and the parametric head model is insufficient because the diffusion model alone cannot incorporate information from the parametric model. In this work, we propose a novel framework, AnimPortrait3D, for text-based realistic animatable 3DGS avatar generation with morphable model alignment, and introduce two key strategies to address these challenges. First, we tackle appearance and geometry ambiguities by utilizing prior information from a pretrained text-to-3D model to initialize a 3D avatar with robust appearance, geometry, and rigging relationships to the morphable model. Second, we refine the initial 3D avatar for dynamic expressions using a ControlNet that is conditioned on semantic and normal maps of the morphable model to ensure accurate alignment. As a result, our method outperforms existing approaches in terms of synthesis quality, alignment, and animation fidelity. Our experiments show that the proposed method advances the state of the art in text-based, animatable 3D head avatar generation.