 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthoTrack: Continuous 6-DoF UAV Trajectory Estimation Anchored in Public Orthophotos
Jun 24, 2026Continuous 6-DoF pose estimation is essential for autonomous UAV operations. Yet, existing visual odometry and SLAM methods accumulate drift and yield only relative, up-to-scale trajectories. Single-frame geo-localization, in turn, discards temporal continuity and remains too slow for real-time use. We present OrthoTrack, a training-free system that estimates continuous 6-DoF UAV trajectories using only publicly available orthophotos and surface models as a map prior. OrthoTrack matches keyframes against the orthophoto and lifts correspondences to metric 3D via the surface model. It then propagates these map-anchored correspondences to intermediate frames with optical flow, producing absolute, metrically scaled poses at every frame without GPS or post-hoc alignment. We also introduce the MovingDrone Dataset, a large-scale benchmark pairing photorealistic UAV sequences with dense 6-DoF ground truth and co-registered multi-modal geodata including multi-temporal orthophotos. On MovingDrone and real-world benchmarks, OrthoTrack runs in real time on a single GPU. It outperforms all baselines by a large margin, even those receiving oracle scale and alignment. By relying on publicly available geodata, OrthoTrack enables deployment to new regions without site-specific adaptation.
ArtiTwinSplat: Interactable Digital Twin Reconstruction via Gaussian Splatting from RGB-D videos
Jun 23, 2026Deploying robots in unstructured real-world environments needs accurate, interactive models of the objects. Constructing these models at scale remains a critical bottleneck for robotic system integration. We present ArtiTwinSplat, a framework that automatically constructs articulated, photo-realistic digital twins of objects directly from RGB-D videos, requiring no CAD models, simulation assets, or manual annotations. Our method is built on 3D Gaussian Splatting that preserve geometric fidelity and photometric realism, coupled with an unsupervised articulation discovery pipeline that recovers part structure and joint kinematics from observed motion alone. With tracking and optimization stages our method provides stable, queryable digital twins that support real-time rendering, viewpoint control, and interactive manipulation. Unlike prior methods confined to simulation, ArtiTwinSplat operates directly on real-world observations and produces twins that are immediately usable by downstream robot planning and learning systems. This method offers a practical, scalable pathway toward digital twin construction, lowering the integration barrier for articulated object manipulation in embodied AI and human-robot collaboration contexts.
PROSE: Training-Free Egocentric Scene Registration with Vision-Language Models
Jun 15, 2026Registering two captures of the same indoor space taken at different times underpins persistent spatial memory for robots and AR systems, yet the realistic version of this task is egocentric and its most scalable form is RGB-only. Head-mounted cameras yield blurry, fast-moving, partially overlapping views from which dense geometry is hard to recover. Classical registration leans on exactly the clean point clouds this setting lacks, while learned scene-graph methods require a pre-built or annotated graph and a trained matcher that we find brittle under egocentric data. We take a different route, using a pretrained vision-language model as the source of both scene understanding and cross-scan matching. Our method, PROSE (Prompted Scene rEgistration), lifts each RGB sequence into an object-level 3D scene graph using off-the-shelf foundation models for geometry, segmentation, and language, then prompts the same VLM to match object instances across the two RGB sequences. To make this matching tractable and reliable, we leverage object heights as a prior and verify each proposed match with a paired same/different query, then solve for the rigid transform by hypothesizing a candidate per matched object and selecting the one with the strongest geometric consensus. PROSE adds no learned parameters and requires no depth sensor, training, or annotated graph. On the egocentric Aria Digital Twin and Aria Everyday Activities benchmarks, it outperforms both geometric and learned scene-graph baselines in registration accuracy, on ground-truth and RGB-reconstructed point clouds alike, and the scene graph it produces transfers directly to downstream tasks.
From Frames to Temporal Graphs: In-Context Egocentric Action Recognition with Vision-Language Models
Jun 13, 2026Action reasoning in egocentric video requires capturing fine-grained transitions of hand-object interactions, a task where general-purpose Vision-Language Models (VLMs) often struggle when operating directly on raw pixels. We propose to decouple visual perception from symbolic reasoning by converting videos into Temporal Action Graphs. In a multi-stage prompting pipeline, we first generate dense natural language narratives over short temporal windows as a semantic bottleneck, then formalize them into structured, open-vocabulary graph representations. On the EGTEA and Epic-Kitchens-100 datasets, the symbolic representation unlocks efficient in-context learning: few-shot graph demonstrations yield substantial accuracy gains over zero-shot frame and graph-based inference alike. Even in the zero-shot setting, graph-based reasoning remains competitive with pixel-based inference despite potential pretraining contamination favoring the latter. Across 11 open-weight VLMs from 6 model families ranging from 2B to 235B parameters, our findings indicate that current VLMs are more effective as symbolic reasoners than as direct visual observers. By projecting video into the language domain, we provide a scalable, fine-tuning-free alternative to end-to-end approaches that better leverages these models' latent reasoning strengths. The code will be made public.
FunFact: Building Probabilistic Functional 3D Scene Graphs via Factor-Graph Reasoning
Apr 04, 2026Recent work in 3D scene understanding is moving beyond purely spatial analysis toward functional scene understanding. However, existing methods often consider functional relationships between object pairs in isolation, failing to capture the scene-wide interdependence that humans use to resolve ambiguity. We introduce FunFact, a framework for constructing probabilistic open-vocabulary functional 3D scene graphs from posed RGB-D images. FunFact first builds an object- and part-centric 3D map and uses foundation models to propose semantically plausible functional relations. These candidates are converted into factor graph variables and constrained by both LLM-derived common-sense priors and geometric priors. This formulation enables joint probabilistic inference over all functional edges and their marginals, yielding substantially better calibrated confidence scores. To benchmark this setting, we introduce FunThor, a synthetic dataset based on AI2-THOR with part-level geometry and rule-based functional annotations. Experiments on SceneFun3D, FunGraph3D, and FunThor show that FunFact improves node and relation discovery recall and significantly reduces calibration error for ambiguous relations, highlighting the benefits of holistic probabilistic modeling for functional scene understanding. See our project page at https://funfact-scenegraph.github.io/
Articulated 3D Scene Graphs for Open-World Mobile Manipulation
Feb 18, 2026Semantics has enabled 3D scene understanding and affordance-driven object interaction. However, robots operating in real-world environments face a critical limitation: they cannot anticipate how objects move. Long-horizon mobile manipulation requires closing the gap between semantics, geometry, and kinematics. In this work, we present MoMa-SG, a novel framework for building semantic-kinematic 3D scene graphs of articulated scenes containing a myriad of interactable objects. Given RGB-D sequences containing multiple object articulations, we temporally segment object interactions and infer object motion using occlusion-robust point tracking. We then lift point trajectories into 3D and estimate articulation models using a novel unified twist estimation formulation that robustly estimates revolute and prismatic joint parameters in a single optimization pass. Next, we associate objects with estimated articulations and detect contained objects by reasoning over parent-child relations at identified opening states. We also introduce the novel Arti4D-Semantic dataset, which uniquely combines hierarchical object semantics including parent-child relation labels with object axis annotations across 62 in-the-wild RGB-D sequences containing 600 object interactions and three distinct observation paradigms. We extensively evaluate the performance of MoMa-SG on two datasets and ablate key design choices of our approach. In addition, real-world experiments on both a quadruped and a mobile manipulator demonstrate that our semantic-kinematic scene graphs enable robust manipulation of articulated objects in everyday home environments. We provide code and data at: https://momasg.cs.uni-freiburg.de.
An Artificial Intelligence-based Assistant for the Visually Impaired
Nov 11, 2025



This paper describes an artificial intelligence-based assistant application, AIDEN, developed during 2023 and 2024, aimed at improving the quality of life for visually impaired individuals. Visually impaired individuals face challenges in identifying objects, reading text, and navigating unfamiliar environments, which can limit their independence and reduce their quality of life. Although solutions such as Braille, audio books, and screen readers exist, they may not be effective in all situations. This application leverages state-of-the-art machine learning algorithms to identify and describe objects, read text, and answer questions about the environment. Specifically, it uses You Only Look Once architectures and a Large Language and Vision Assistant. The system incorporates several methods to facilitate the user's interaction with the system and access to textual and visual information in an appropriate manner. AIDEN aims to enhance user autonomy and access to information, contributing to an improved perception of daily usability, as supported by user feedback.
Video Perception Models for 3D Scene Synthesis
Jun 25, 2025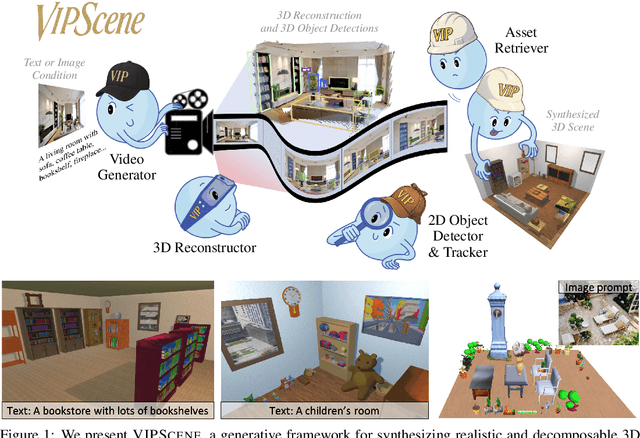



Traditionally, 3D scene synthesis requires expert knowledge and significant manual effort. Automating this process could greatly benefit fields such as architectural design, robotics simulation, virtual reality, and gaming. Recent approaches to 3D scene synthesis often rely on the commonsense reasoning of large language models (LLMs) or strong visual priors of modern image generation models. However, current LLMs demonstrate limited 3D spatial reasoning ability, which restricts their ability to generate realistic and coherent 3D scenes. Meanwhile, image generation-based methods often suffer from constraints in viewpoint selection and multi-view inconsistencies. In this work, we present Video Perception models for 3D Scene synthesis (VIPScene), a novel framework that exploits the encoded commonsense knowledge of the 3D physical world in video generation models to ensure coherent scene layouts and consistent object placements across views. VIPScene accepts both text and image prompts and seamlessly integrates video generation, feedforward 3D reconstruction, and open-vocabulary perception models to semantically and geometrically analyze each object in a scene. This enables flexible scene synthesis with high realism and structural consistency. For more precise analysis, we further introduce First-Person View Score (FPVScore) for coherence and plausibility evaluation, utilizing continuous first-person perspective to capitalize on the reasoning ability of multimodal large language models. Extensive experiments show that VIPScene significantly outperforms existing methods and generalizes well across diverse scenarios. The code will be released.
Spot-On: A Mixed Reality Interface for Multi-Robot Cooperation
May 28, 2025



Recent progress in mixed reality (MR) and robotics is enabling increasingly sophisticated forms of human-robot collaboration. Building on these developments, we introduce a novel MR framework that allows multiple quadruped robots to operate in semantically diverse environments via a MR interface. Our system supports collaborative tasks involving drawers, swing doors, and higher-level infrastructure such as light switches. A comprehensive user study verifies both the design and usability of our app, with participants giving a "good" or "very good" rating in almost all cases. Overall, our approach provides an effective and intuitive framework for MR-based multi-robot collaboration in complex, real-world scenarios.
Lost & Found: Updating Dynamic 3D Scene Graphs from Egocentric Observations
Nov 28, 2024



Recent approaches have successfully focused on the segmentation of static reconstructions, thereby equipping downstream applications with semantic 3D understanding. However, the world in which we live is dynamic, characterized by numerous interactions between the environment and humans or robotic agents. Static semantic maps are unable to capture this information, and the naive solution of rescanning the environment after every change is both costly and ineffective in tracking e.g. objects being stored away in drawers. With Lost & Found we present an approach that addresses this limitation. Based solely on egocentric recordings with corresponding hand position and camera pose estimates, we are able to track the 6DoF poses of the moving object within the detected interaction interval. These changes are applied online to a transformable scene graph that captures object-level relations. Compared to state-of-the-art object pose trackers, our approach is more reliable in handling the challenging egocentric viewpoint and the lack of depth information. It outperforms the second-best approach by 34% and 56% for translational and orientational error, respectively, and produces visibly smoother 6DoF object trajectories. In addition, we illustrate how the acquired interaction information in the dynamic scene graph can be employed in the context of robotic applications that would otherwise be unfeasible: We show how our method allows to command a mobile manipulator through teach & repeat, and how information about prior interaction allows a mobile manipulator to retrieve an object hidden in a drawer. Code, videos and corresponding data are accessible at https://behretj.github.io/LostAndFound.