 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting User-Perceived Latency of On-Device E2E Speech Recognition
Apr 06, 2021
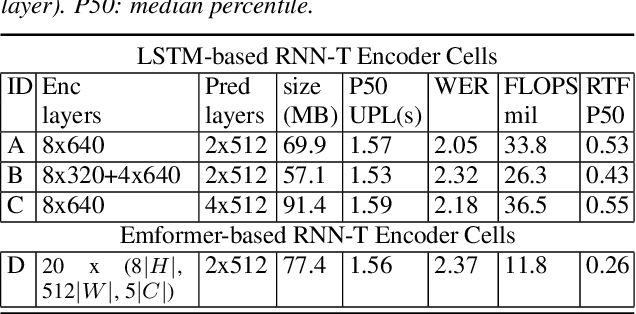
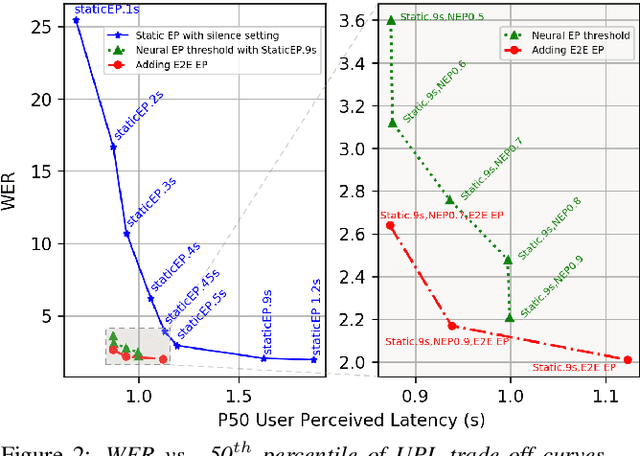
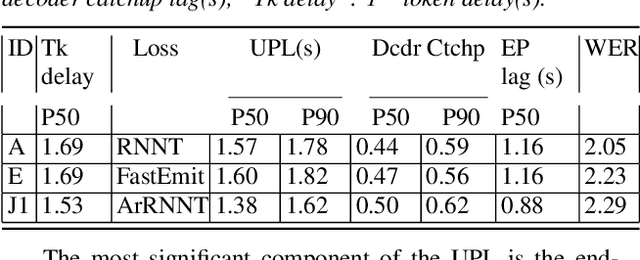
As speech-enabled devices such as smartphones and smart speakers become increasingly ubiquitous, there is growing interest in building automatic speech recognition (ASR) systems that can run directly on-device; end-to-end (E2E) speech recognition models such as recurrent neural network transducers and their variants have recently emerged as prime candidates for this task. Apart from being accurate and compact, such systems need to decode speech with low user-perceived latency (UPL), producing words as soon as they are spoken. This work examines the impact of various techniques -- model architectures, training criteria, decoding hyperparameters, and endpointer parameters -- on UPL. Our analyses suggest that measures of model size (parameters, input chunk sizes), or measures of computation (e.g., FLOPS, RTF) that reflect the model's ability to process input frames are not always strongly correlated with observed UPL. Thus, conventional algorithmic latency measurements might be inadequate in accurately capturing latency observed when models are deployed on embedded devices. Instead, we find that factors affecting token emission latency, and endpointing behavior significantly impact on UPL. We achieve the best trade-off between latency and word error rate when performing ASR jointly with endpointing, and using the recently proposed alignment regularization.
Dynamic Encoder Transducer: A Flexible Solution For Trading Off Accuracy For Latency
Apr 05, 2021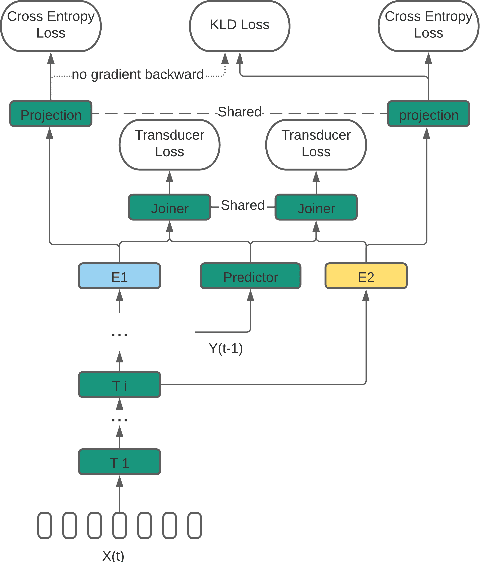
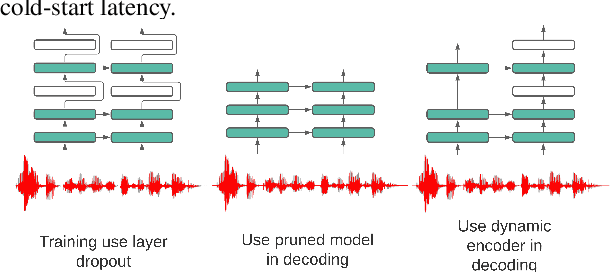
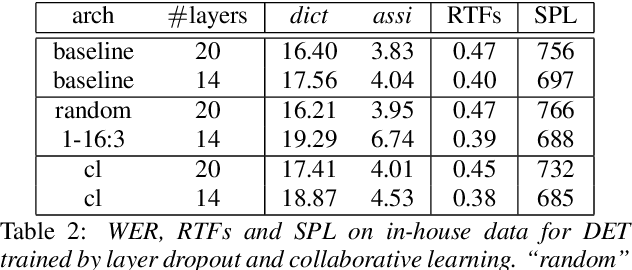
We propose a dynamic encoder transducer (DET) for on-device speech recognition. One DET model scales to multiple devices with different computation capacities without retraining or finetuning. To trading off accuracy and latency, DET assigns different encoders to decode different parts of an utterance. We apply and compare the layer dropout and the collaborative learning for DET training. The layer dropout method that randomly drops out encoder layers in the training phase, can do on-demand layer dropout in decoding. Collaborative learning jointly trains multiple encoders with different depths in one single model. Experiment results on Librispeech and in-house data show that DET provides a flexible accuracy and latency trade-off. Results on Librispeech show that the full-size encoder in DET relatively reduces the word error rate of the same size baseline by over 8%. The lightweight encoder in DET trained with collaborative learning reduces the model size by 25% but still gets similar WER as the full-size baseline. DET gets similar accuracy as a baseline model with better latency on a large in-house data set by assigning a lightweight encoder for the beginning part of one utterance and a full-size encoder for the rest.
Learning Word-Level Confidence For Subword End-to-End ASR
Mar 11, 2021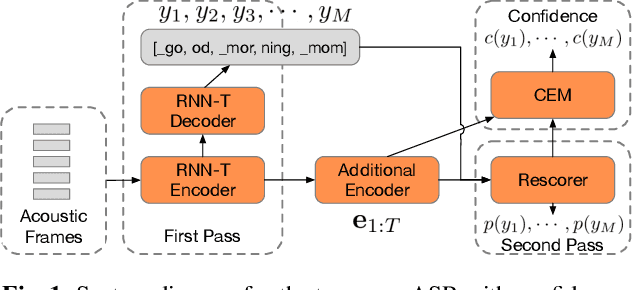

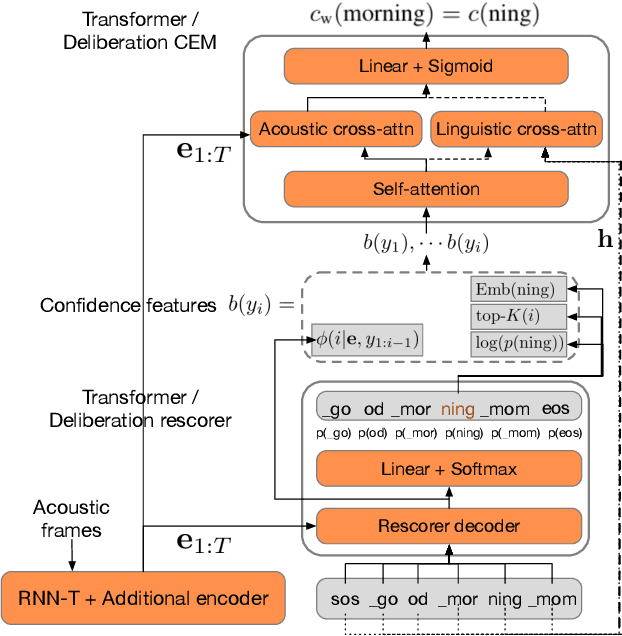
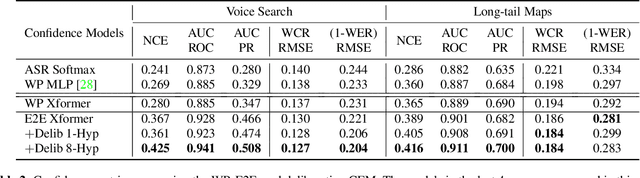
We study the problem of word-level confidence estimation in subword-based end-to-end (E2E) models for automatic speech recognition (ASR). Although prior works have proposed training auxiliary confidence models for ASR systems, they do not extend naturally to systems that operate on word-pieces (WP) as their vocabulary. In particular, ground truth WP correctness labels are needed for training confidence models, but the non-unique tokenization from word to WP causes inaccurate labels to be generated. This paper proposes and studies two confidence models of increasing complexity to solve this problem. The final model uses self-attention to directly learn word-level confidence without needing subword tokenization, and exploits full context features from multiple hypotheses to improve confidence accuracy. Experiments on Voice Search and long-tail test sets show standard metrics (e.g., NCE, AUC, RMSE) improving substantially. The proposed confidence module also enables a model selection approach to combine an on-device E2E model with a hybrid model on the server to address the rare word recognition problem for the E2E model.
Less Is More: Improved RNN-T Decoding Using Limited Label Context and Path Merging
Dec 12, 2020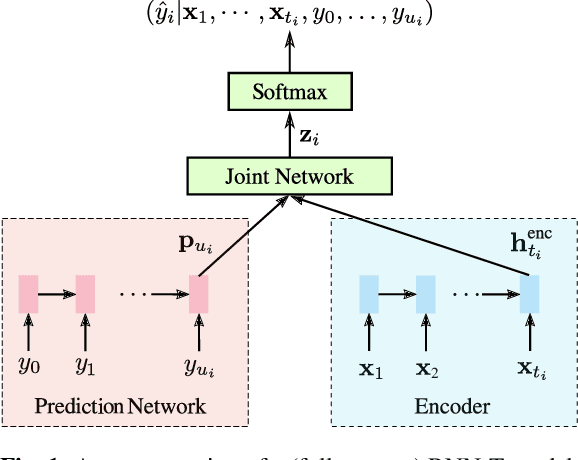
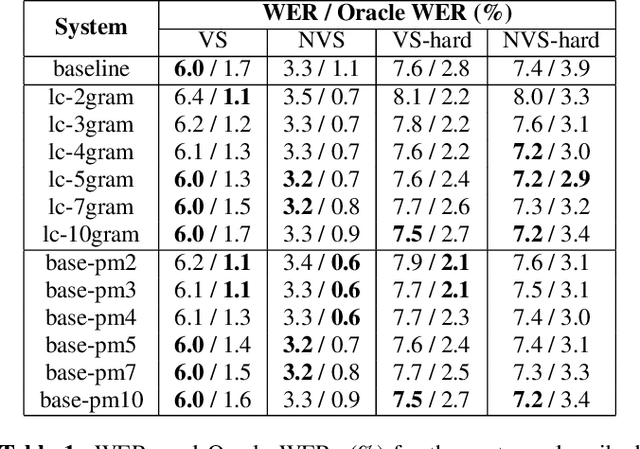
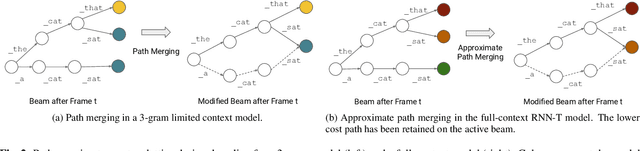
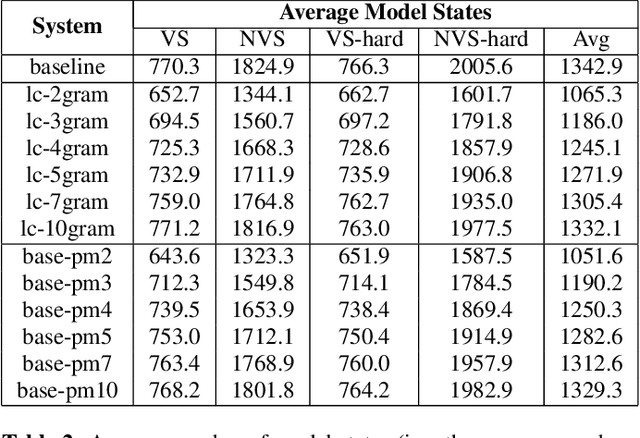
End-to-end models that condition the output label sequence on all previously predicted labels have emerged as popular alternatives to conventional systems for automatic speech recognition (ASR). Since unique label histories correspond to distinct models states, such models are decoded using an approximate beam-search process which produces a tree of hypotheses. In this work, we study the influence of the amount of label context on the model's accuracy, and its impact on the efficiency of the decoding process. We find that we can limit the context of the recurrent neural network transducer (RNN-T) during training to just four previous word-piece labels, without degrading word error rate (WER) relative to the full-context baseline. Limiting context also provides opportunities to improve the efficiency of the beam-search process during decoding by removing redundant paths from the active beam, and instead retaining them in the final lattice. This path-merging scheme can also be applied when decoding the baseline full-context model through an approximation. Overall, we find that the proposed path-merging scheme is extremely effective allowing us to improve oracle WERs by up to 36% over the baseline, while simultaneously reducing the number of model evaluations by up to 5.3% without any degradation in WER.
Cascaded encoders for unifying streaming and non-streaming ASR
Oct 27, 2020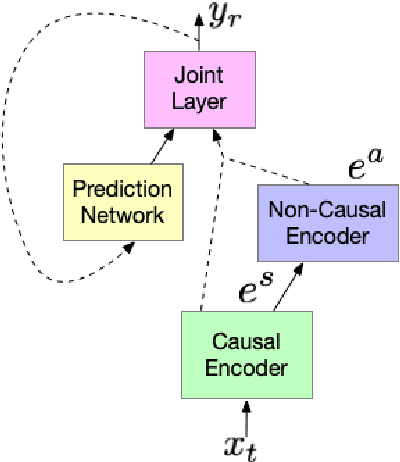
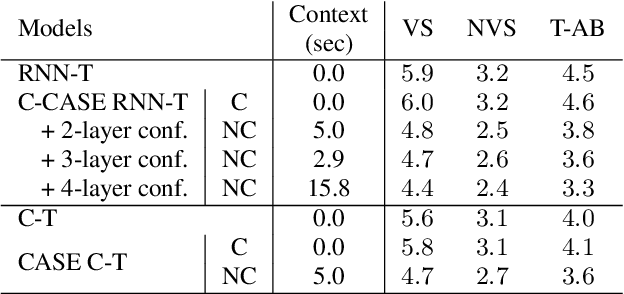
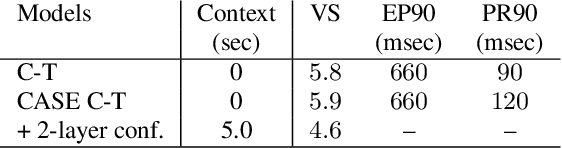
End-to-end (E2E) automatic speech recognition (ASR) models, by now, have shown competitive performance on several benchmarks. These models are structured to either operate in streaming or non-streaming mode. This work presents cascaded encoders for building a single E2E ASR model that can operate in both these modes simultaneously. The proposed model consists of streaming and non-streaming encoders. Input features are first processed by the streaming encoder; the non-streaming encoder operates exclusively on the output of the streaming encoder. A single decoder then learns to decode either using the output of the streaming or the non-streaming encoder. Results show that this model achieves similar word error rates (WER) as a standalone streaming model when operating in streaming mode, and obtains 10% -- 27% relative improvement when operating in non-streaming mode. Our results also show that the proposed approach outperforms existing E2E two-pass models, especially on long-form speech.
Replacing Human Audio with Synthetic Audio for On-device Unspoken Punctuation Prediction
Oct 20, 2020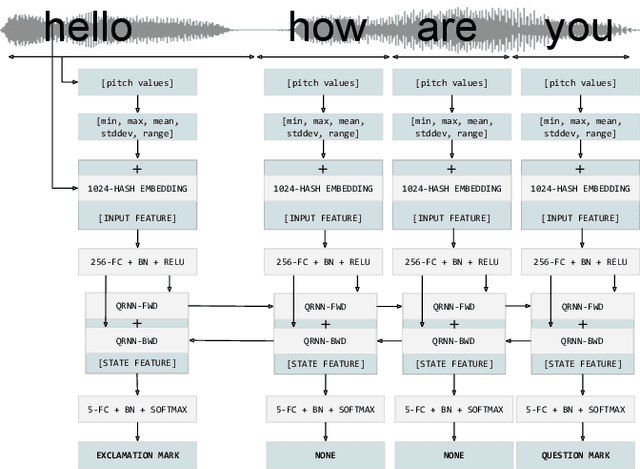

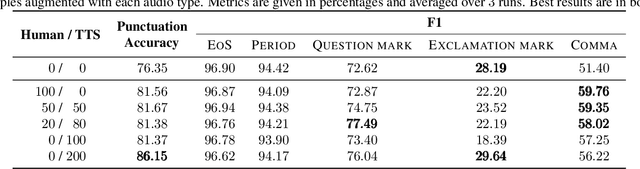

We present a novel multi-modal unspoken punctuation prediction system for the English language which combines acoustic and text features. We demonstrate for the first time, that by relying exclusively on synthetic data generated using a prosody-aware text-to-speech system, we can outperform a model trained with expensive human audio recordings on the unspoken punctuation prediction problem. Our model architecture is well suited for on-device use. This is achieved by leveraging hash-based embeddings of automatic speech recognition text output in conjunction with acoustic features as input to a quasi-recurrent neural network, keeping the model size small and latency low.
RNN-T Models Fail to Generalize to Out-of-Domain Audio: Causes and Solutions
May 17, 2020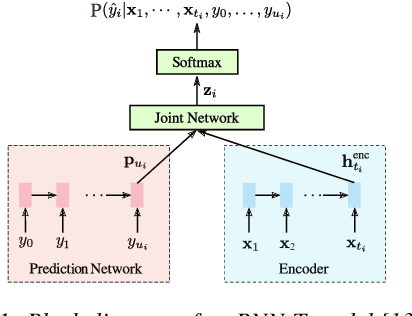
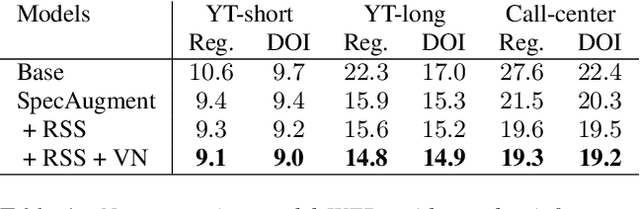
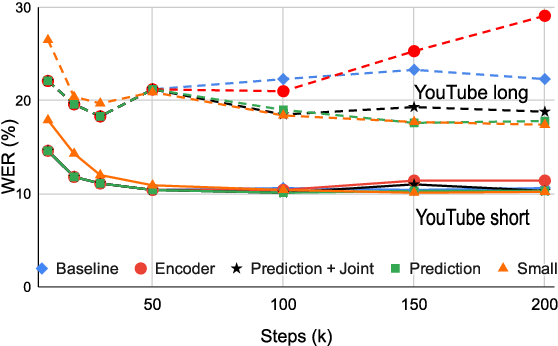
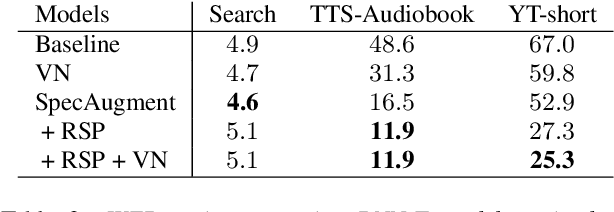
In recent years, all-neural end-to-end approaches have obtained state-of-the-art results on several challenging automatic speech recognition (ASR) tasks. However, most existing works focus on building ASR models where train and test data are drawn from the same domain. This results in poor generalization characteristics on mismatched-domains: e.g., end-to-end models trained on short segments perform poorly when evaluated on longer utterances. In this work, we analyze the generalization properties of streaming and non-streaming recurrent neural network transducer (RNN-T) based end-to-end models in order to identify model components that negatively affect generalization performance. We propose two solutions: combining multiple regularization techniques during training, and using dynamic overlapping inference. On a long-form YouTube test set, when the non-streaming RNN-T model is trained with shorter segments of data, the proposed combination improves word error rate (WER) from 22.3% to 14.8%; when the streaming RNN-T model trained on short Search queries, the proposed techniques improve WER on the YouTube set from 67.0% to 25.3%. Finally, when trained on Librispeech, we find that dynamic overlapping inference improves WER on YouTube from 99.8% to 33.0%.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020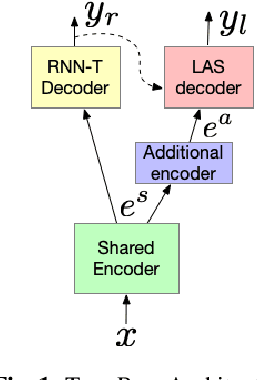
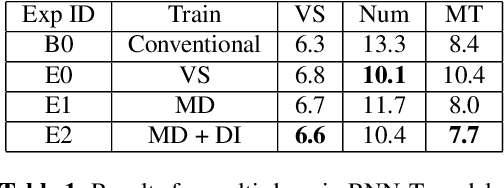
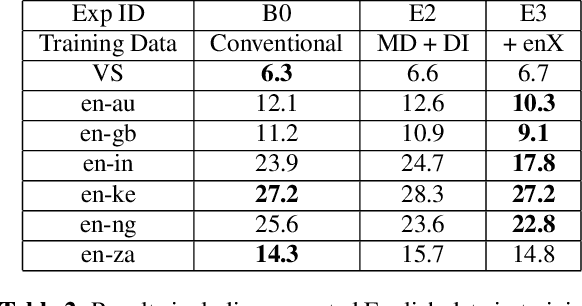
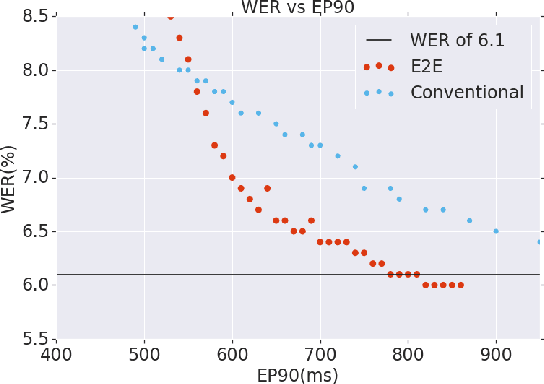
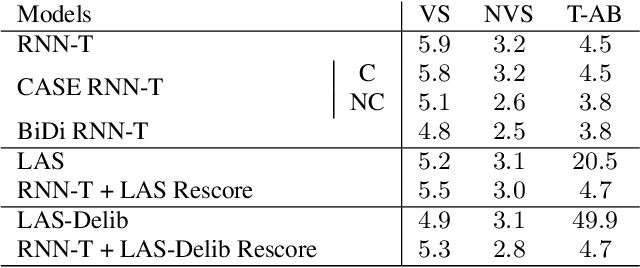
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
Deliberation Model Based Two-Pass End-to-End Speech Recognition
Mar 17, 2020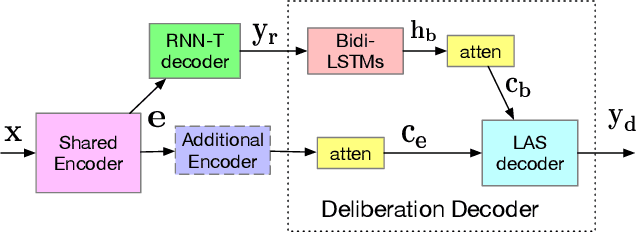
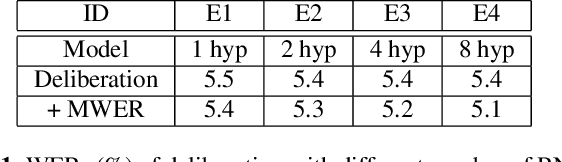
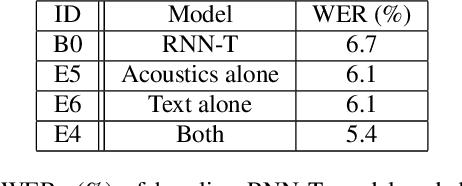
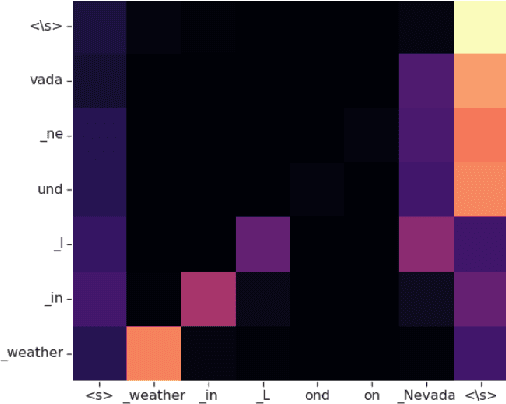
End-to-end (E2E) models have made rapid progress in automatic speech recognition (ASR) and perform competitively relative to conventional models. To further improve the quality, a two-pass model has been proposed to rescore streamed hypotheses using the non-streaming Listen, Attend and Spell (LAS) model while maintaining a reasonable latency. The model attends to acoustics to rescore hypotheses, as opposed to a class of neural correction models that use only first-pass text hypotheses. In this work, we propose to attend to both acoustics and first-pass hypotheses using a deliberation network. A bidirectional encoder is used to extract context information from first-pass hypotheses. The proposed deliberation model achieves 12% relative WER reduction compared to LAS rescoring in Google Voice Search (VS) tasks, and 23% reduction on a proper noun test set. Compared to a large conventional model, our best model performs 21% relatively better for VS. In terms of computational complexity, the deliberation decoder has a larger size than the LAS decoder, and hence requires more computations in second-pass decoding.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019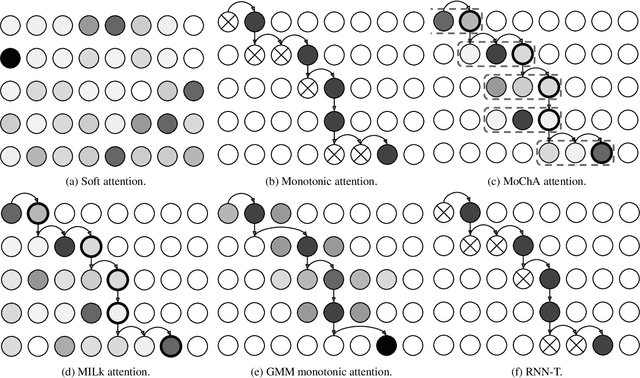

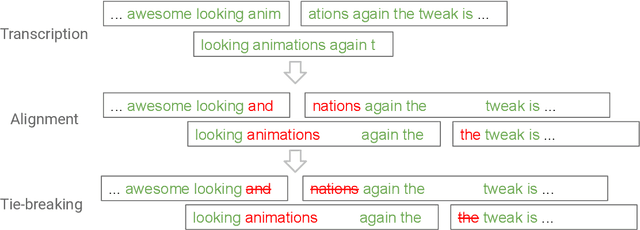
End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.