 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliberation Model Based Two-Pass End-to-End Speech Recognition
Paper and Code
Mar 17, 2020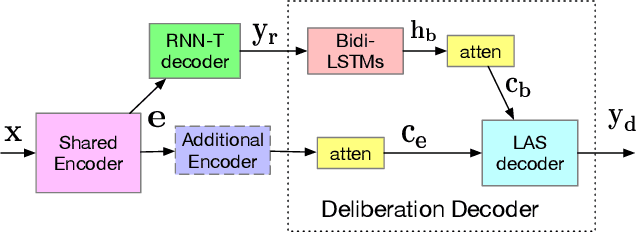
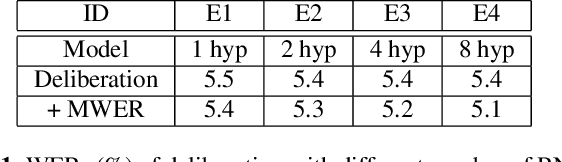
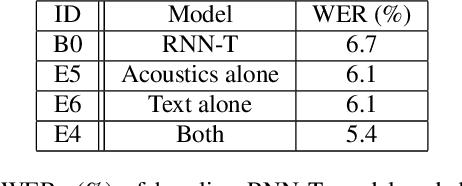
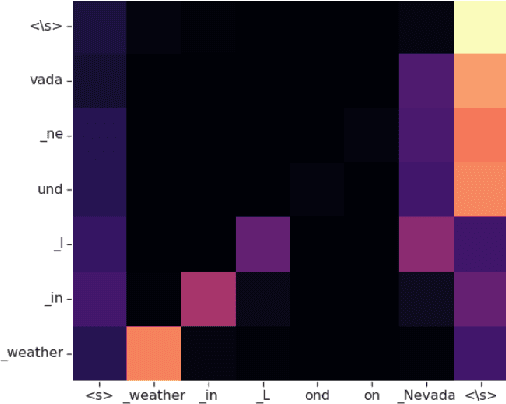
End-to-end (E2E) models have made rapid progress in automatic speech recognition (ASR) and perform competitively relative to conventional models. To further improve the quality, a two-pass model has been proposed to rescore streamed hypotheses using the non-streaming Listen, Attend and Spell (LAS) model while maintaining a reasonable latency. The model attends to acoustics to rescore hypotheses, as opposed to a class of neural correction models that use only first-pass text hypotheses. In this work, we propose to attend to both acoustics and first-pass hypotheses using a deliberation network. A bidirectional encoder is used to extract context information from first-pass hypotheses. The proposed deliberation model achieves 12% relative WER reduction compared to LAS rescoring in Google Voice Search (VS) tasks, and 23% reduction on a proper noun test set. Compared to a large conventional model, our best model performs 21% relatively better for VS. In terms of computational complexity, the deliberation decoder has a larger size than the LAS decoder, and hence requires more computations in second-pass decoding.