 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Is More: Improved RNN-T Decoding Using Limited Label Context and Path Merging
Paper and Code
Dec 12, 2020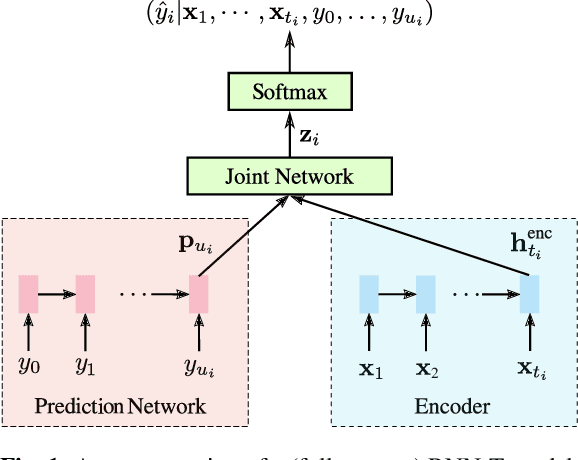
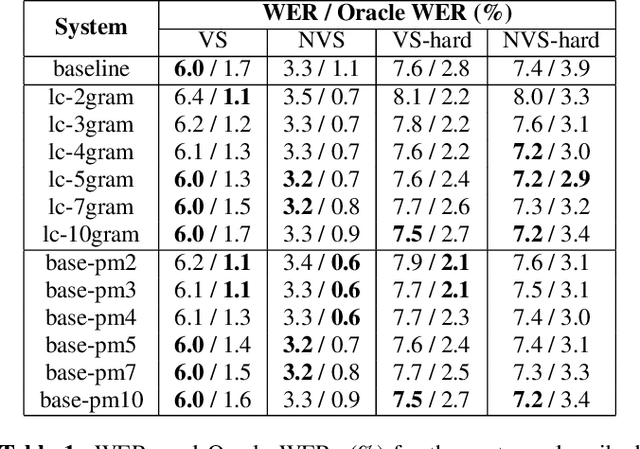
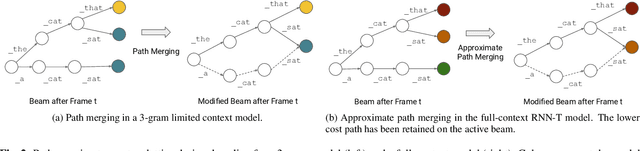
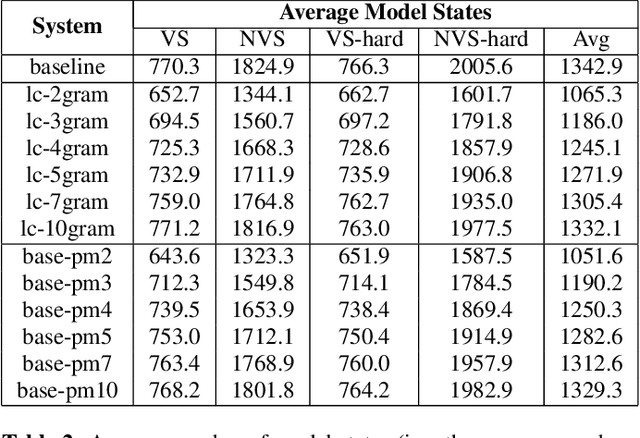
End-to-end models that condition the output label sequence on all previously predicted labels have emerged as popular alternatives to conventional systems for automatic speech recognition (ASR). Since unique label histories correspond to distinct models states, such models are decoded using an approximate beam-search process which produces a tree of hypotheses. In this work, we study the influence of the amount of label context on the model's accuracy, and its impact on the efficiency of the decoding process. We find that we can limit the context of the recurrent neural network transducer (RNN-T) during training to just four previous word-piece labels, without degrading word error rate (WER) relative to the full-context baseline. Limiting context also provides opportunities to improve the efficiency of the beam-search process during decoding by removing redundant paths from the active beam, and instead retaining them in the final lattice. This path-merging scheme can also be applied when decoding the baseline full-context model through an approximation. Overall, we find that the proposed path-merging scheme is extremely effective allowing us to improve oracle WERs by up to 36% over the baseline, while simultaneously reducing the number of model evaluations by up to 5.3% without any degradation in WER.