 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Audio Hallucination in Egocentric Video Understanding
Apr 26, 2026Egocentric videos provide a distinctive setting in which sound serves as crucial cues to understand user activities and surroundings, particularly when visual information is unstable or occluded due to continuous camera movement. State-of-the-art large audio-visual language models (AV-LLMs) can generate multimodal descriptions. However, we show in this work that they are prone to audio hallucinations, often inferring sounds from visual cues that are visible but not heard. We present a systematic and automatic evaluation framework for analyzing audio hallucinations in egocentric video through a targeted question-answering (Q/A) protocol. We curate a dataset of 300 egocentric videos and design 1,000 sound-focused questions to probe model outputs. To characterize hallucinations, we propose a grounded taxonomy that distinguishes between foreground action sounds from the user activities and background ambient sounds. Our evaluation shows that advanced AV-LLMs, such as Qwen2.5 Omni, exhibit high hallucination rates, achieving only 27.3% and 39.5% accuracy on Q/As related to foreground and background sounds, respectively. With this work, we highlight the need to measure the reliability of multimodal responses, emphasizing that robust evaluation of hallucinations is essential to develop reliable AV-LLMs.
EgoAVU: Egocentric Audio-Visual Understanding
Feb 05, 2026Understanding egocentric videos plays a vital role for embodied intelligence. Recent multi-modal large language models (MLLMs) can accept both visual and audio inputs. However, due to the challenge of obtaining text labels with coherent joint-modality information, whether MLLMs can jointly understand both modalities in egocentric videos remains under-explored. To address this problem, we introduce EgoAVU, a scalable data engine to automatically generate egocentric audio-visual narrations, questions, and answers. EgoAVU enriches human narrations with multimodal context and generates audio-visual narrations through cross-modal correlation modeling. Token-based video filtering and modular, graph-based curation ensure both data diversity and quality. Leveraging EgoAVU, we construct EgoAVU-Instruct, a large-scale training dataset of 3M samples, and EgoAVU-Bench, a manually verified evaluation split covering diverse tasks. EgoAVU-Bench clearly reveals the limitations of existing MLLMs: they bias heavily toward visual signals, often neglecting audio cues or failing to correspond audio with the visual source. Finetuning MLLMs on EgoAVU-Instruct effectively addresses this issue, enabling up to 113% performance improvement on EgoAVU-Bench. Such benefits also transfer to other benchmarks such as EgoTempo and EgoIllusion, achieving up to 28% relative performance gain. Code will be released to the community.
SLAP: Scalable Language-Audio Pretraining with Variable-Duration Audio and Multi-Objective Training
Jan 18, 2026Contrastive language-audio pretraining (CLAP) has achieved notable success in learning semantically rich audio representations and is widely adopted for various audio-related tasks. However, current CLAP models face several key limitations. First, they are typically trained on relatively small datasets, often comprising a few million audio samples. Second, existing CLAP models are restricted to short and fixed duration, which constrains their usage in real-world scenarios with variable-duration audio. Third, the standard contrastive training objective operates on global representations, which may hinder the learning of dense, fine-grained audio features. To address these challenges, we introduce Scalable Language-Audio Pretraining (SLAP), which scales language-audio pretraining to 109 million audio-text pairs with variable audio durations and incorporates multiple training objectives. SLAP unifies contrastive loss with additional self-supervised and captioning losses in a single-stage training, facilitating the learning of richer dense audio representations. The proposed SLAP model achieves new state-of-the-art performance on audio-text retrieval and zero-shot audio classification tasks, demonstrating its effectiveness across diverse benchmarks.
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Jul 04, 2024



We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
On The Open Prompt Challenge In Conditional Audio Generation
Nov 01, 2023



Text-to-audio generation (TTA) produces audio from a text description, learning from pairs of audio samples and hand-annotated text. However, commercializing audio generation is challenging as user-input prompts are often under-specified when compared to text descriptions used to train TTA models. In this work, we treat TTA models as a ``blackbox'' and address the user prompt challenge with two key insights: (1) User prompts are generally under-specified, leading to a large alignment gap between user prompts and training prompts. (2) There is a distribution of audio descriptions for which TTA models are better at generating higher quality audio, which we refer to as ``audionese''. To this end, we rewrite prompts with instruction-tuned models and propose utilizing text-audio alignment as feedback signals via margin ranking learning for audio improvements. On both objective and subjective human evaluations, we observed marked improvements in both text-audio alignment and music audio quality.
FoleyGen: Visually-Guided Audio Generation
Sep 19, 2023Recent advancements in audio generation have been spurred by the evolution of large-scale deep learning models and expansive datasets. However, the task of video-to-audio (V2A) generation continues to be a challenge, principally because of the intricate relationship between the high-dimensional visual and auditory data, and the challenges associated with temporal synchronization. In this study, we introduce FoleyGen, an open-domain V2A generation system built on a language modeling paradigm. FoleyGen leverages an off-the-shelf neural audio codec for bidirectional conversion between waveforms and discrete tokens. The generation of audio tokens is facilitated by a single Transformer model, which is conditioned on visual features extracted from a visual encoder. A prevalent problem in V2A generation is the misalignment of generated audio with the visible actions in the video. To address this, we explore three novel visual attention mechanisms. We further undertake an exhaustive evaluation of multiple visual encoders, each pretrained on either single-modal or multi-modal tasks. The experimental results on VGGSound dataset show that our proposed FoleyGen outperforms previous systems across all objective metrics and human evaluations.
Enhance audio generation controllability through representation similarity regularization
Sep 15, 2023



This paper presents an innovative approach to enhance control over audio generation by emphasizing the alignment between audio and text representations during model training. In the context of language model-based audio generation, the model leverages input from both textual and audio token representations to predict subsequent audio tokens. However, the current configuration lacks explicit regularization to ensure the alignment between the chosen text representation and the language model's predictions. Our proposal involves the incorporation of audio and text representation regularization, particularly during the classifier-free guidance (CFG) phase, where the text condition is excluded from cross attention during language model training. The aim of this proposed representation regularization is to minimize discrepancies in audio and text similarity compared to other samples within the same training batch. Experimental results on both music and audio generation tasks demonstrate that our proposed methods lead to improvements in objective metrics for both audio and music generation, as well as an enhancement in the human perception for audio generation.
Stack-and-Delay: a new codebook pattern for music generation
Sep 15, 2023In language modeling based music generation, a generated waveform is represented by a sequence of hierarchical token stacks that can be decoded either in an auto-regressive manner or in parallel, depending on the codebook patterns. In particular, flattening the codebooks represents the highest quality decoding strategy, while being notoriously slow. To this end, we propose a novel stack-and-delay style of decoding strategy to improve upon the flat pattern decoding where generation speed is four times faster as opposed to vanilla flat decoding. This brings the inference time close to that of the delay decoding strategy, and allows for faster inference on GPU for small batch sizes. For the same inference efficiency budget as the delay pattern, we show that the proposed approach performs better in objective evaluations, almost closing the gap with the flat pattern in terms of quality. The results are corroborated by subjective evaluations which show that samples generated by the new model are slightly more often preferred to samples generated by the competing model given the same text prompts.
Streaming Transformer Transducer Based Speech Recognition Using Non-Causal Convolution
Oct 07, 2021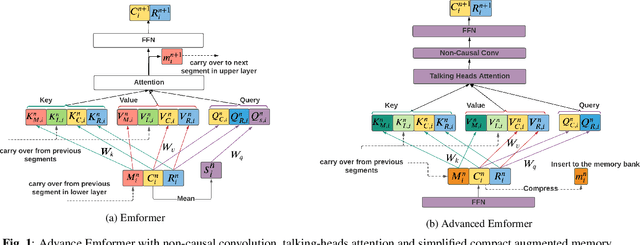
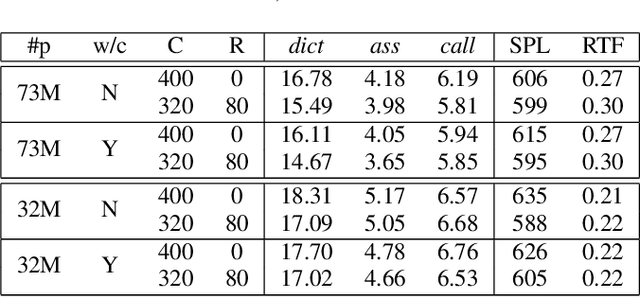
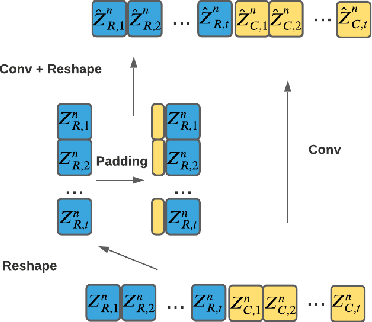
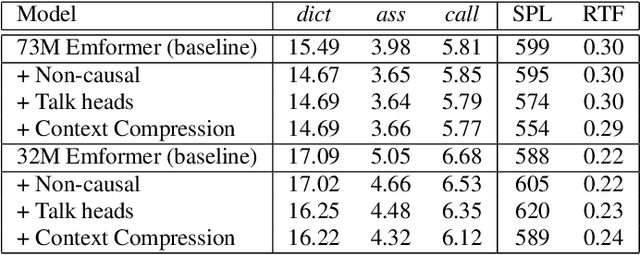
This paper improves the streaming transformer transducer for speech recognition by using non-causal convolution. Many works apply the causal convolution to improve streaming transformer ignoring the lookahead context. We propose to use non-causal convolution to process the center block and lookahead context separately. This method leverages the lookahead context in convolution and maintains similar training and decoding efficiency. Given the similar latency, using the non-causal convolution with lookahead context gives better accuracy than causal convolution, especially for open-domain dictation scenarios. Besides, this paper applies talking-head attention and a novel history context compression scheme to further improve the performance. The talking-head attention improves the multi-head self-attention by transferring information among different heads. The history context compression method introduces more extended history context compactly. On our in-house data, the proposed methods improve a small Emformer baseline with lookahead context by relative WERR 5.1\%, 14.5\%, 8.4\% on open-domain dictation, assistant general scenarios, and assistant calling scenarios, respectively.
Collaborative Training of Acoustic Encoders for Speech Recognition
Jul 13, 2021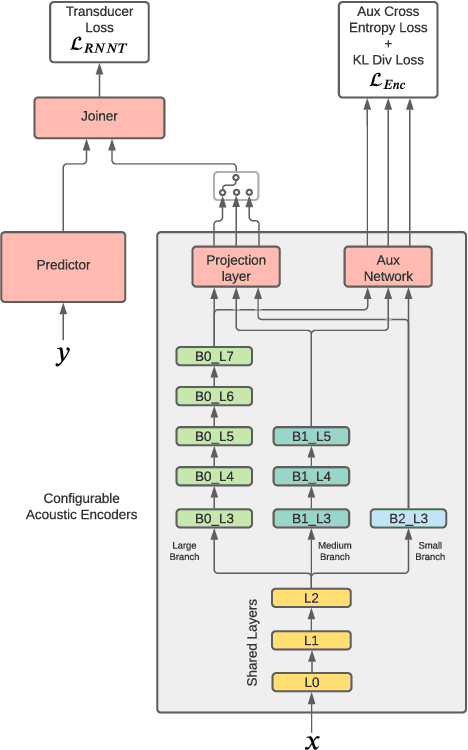
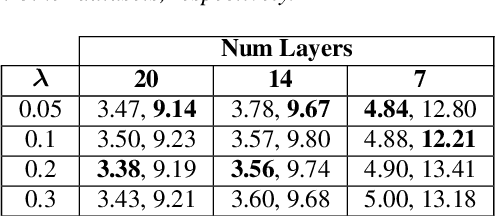
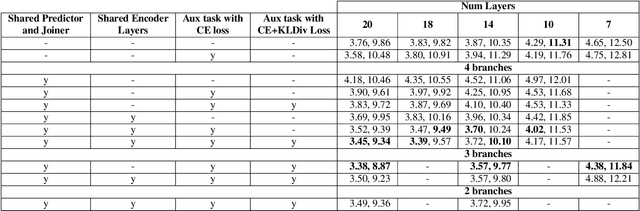
On-device speech recognition requires training models of different sizes for deploying on devices with various computational budgets. When building such different models, we can benefit from training them jointly to take advantage of the knowledge shared between them. Joint training is also efficient since it reduces the redundancy in the training procedure's data handling operations. We propose a method for collaboratively training acoustic encoders of different sizes for speech recognition. We use a sequence transducer setup where different acoustic encoders share a common predictor and joiner modules. The acoustic encoders are also trained using co-distillation through an auxiliary task for frame level chenone prediction, along with the transducer loss. We perform experiments using the LibriSpeech corpus and demonstrate that the collaboratively trained acoustic encoders can provide up to a 11% relative improvement in the word error rate on both the test partitions.