 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
End-to-End Speech Recognition Contextualization with Large Language Models
Sep 19, 2023



In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
Modality Confidence Aware Training for Robust End-to-End Spoken Language Understanding
Jul 22, 2023End-to-end (E2E) spoken language understanding (SLU) systems that generate a semantic parse from speech have become more promising recently. This approach uses a single model that utilizes audio and text representations from pre-trained speech recognition models (ASR), and outperforms traditional pipeline SLU systems in on-device streaming scenarios. However, E2E SLU systems still show weakness when text representation quality is low due to ASR transcription errors. To overcome this issue, we propose a novel E2E SLU system that enhances robustness to ASR errors by fusing audio and text representations based on the estimated modality confidence of ASR hypotheses. We introduce two novel techniques: 1) an effective method to encode the quality of ASR hypotheses and 2) an effective approach to integrate them into E2E SLU models. We show accuracy improvements on STOP dataset and share the analysis to demonstrate the effectiveness of our approach.
Improving Fast-slow Encoder based Transducer with Streaming Deliberation
Dec 15, 2022This paper introduces a fast-slow encoder based transducer with streaming deliberation for end-to-end automatic speech recognition. We aim to improve the recognition accuracy of the fast-slow encoder based transducer while keeping its latency low by integrating a streaming deliberation model. Specifically, the deliberation model leverages partial hypotheses from the streaming fast encoder and implicitly learns to correct recognition errors. We modify the parallel beam search algorithm for fast-slow encoder based transducer to be efficient and compatible with the deliberation model. In addition, the deliberation model is designed to process streaming data. To further improve the deliberation performance, a simple text augmentation approach is explored. We also compare LSTM and Conformer models for encoding partial hypotheses. Experiments on Librispeech and in-house data show relative WER reductions (WERRs) from 3% to 5% with a slight increase in model size and negligible extra token emission latency compared with fast-slow encoder based transducer. Compared with vanilla neural transducers, the proposed deliberation model together with fast-slow encoder based transducer obtains relative 10-11% WERRs on Librispeech and around relative 6% WERR on in-house data with smaller emission delays.
Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities
Nov 10, 2022



End-to-end multilingual ASR has become more appealing because of several reasons such as simplifying the training and deployment process and positive performance transfer from high-resource to low-resource languages. However, scaling up the number of languages, total hours, and number of unique tokens is not a trivial task. This paper explores large-scale multilingual ASR models on 70 languages. We inspect two architectures: (1) Shared embedding and output and (2) Multiple embedding and output model. In the shared model experiments, we show the importance of tokenization strategy across different languages. Later, we use our optimal tokenization strategy to train multiple embedding and output model to further improve our result. Our multilingual ASR achieves 13.9%-15.6% average WER relative improvement compared to monolingual models. We show that our multilingual ASR generalizes well on an unseen dataset and domain, achieving 9.5% and 7.5% WER on Multilingual Librispeech (MLS) with zero-shot and finetuning, respectively.
Factorized Blank Thresholding for Improved Runtime Efficiency of Neural Transducers
Nov 02, 2022We show how factoring the RNN-T's output distribution can significantly reduce the computation cost and power consumption for on-device ASR inference with no loss in accuracy. With the rise in popularity of neural-transducer type models like the RNN-T for on-device ASR, optimizing RNN-T's runtime efficiency is of great interest. While previous work has primarily focused on the optimization of RNN-T's acoustic encoder and predictor, this paper focuses the attention on the joiner. We show that despite being only a small part of RNN-T, the joiner has a large impact on the overall model's runtime efficiency. We propose to factorize the joiner into blank and non-blank portions for the purpose of skipping the more expensive non-blank computation when the blank probability exceeds a certain threshold. Since the blank probability can be computed very efficiently and the RNN-T output is dominated by blanks, our proposed method leads to a 26-30% decoding speed-up and 43-53% reduction in on-device power consumption, all the while incurring no accuracy degradation and being relatively simple to implement.
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022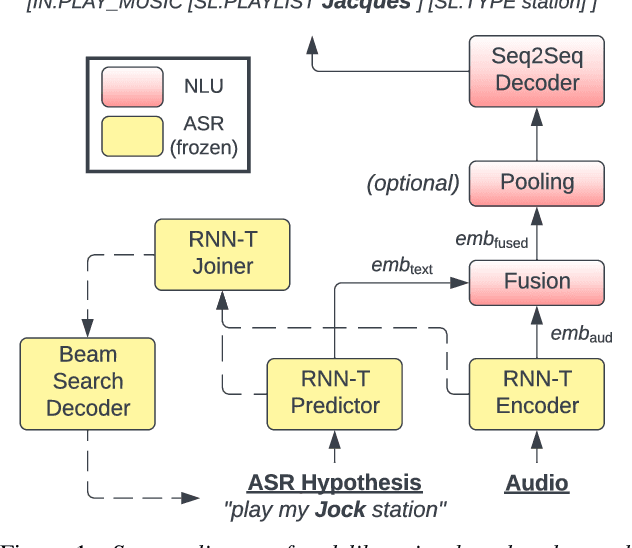

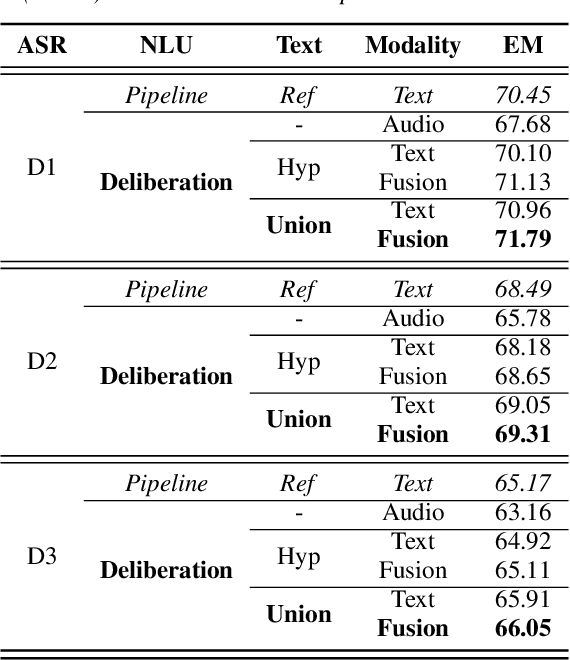
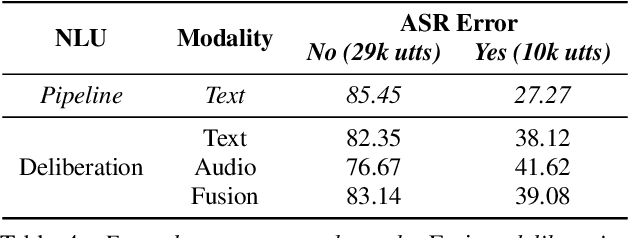
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Neural-FST Class Language Model for End-to-End Speech Recognition
Jan 31, 2022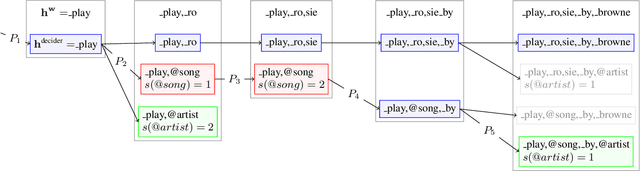
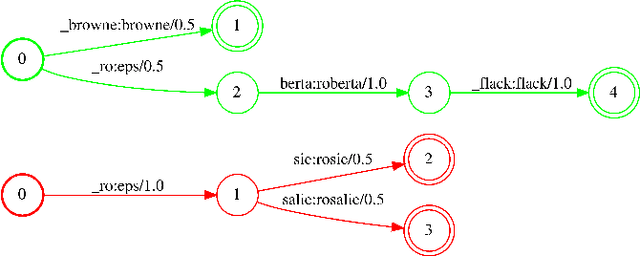
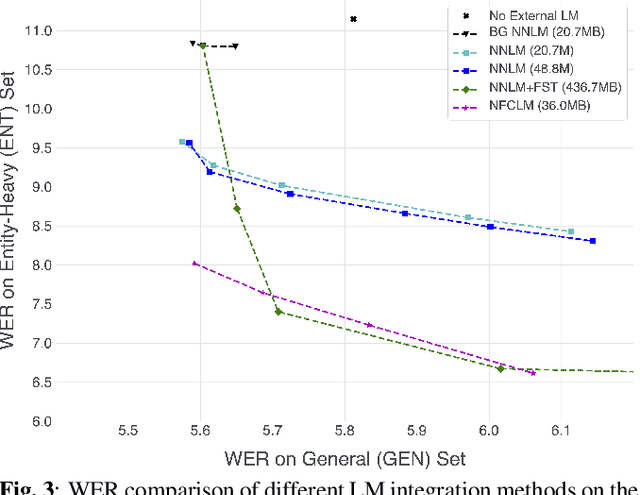
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
Evaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021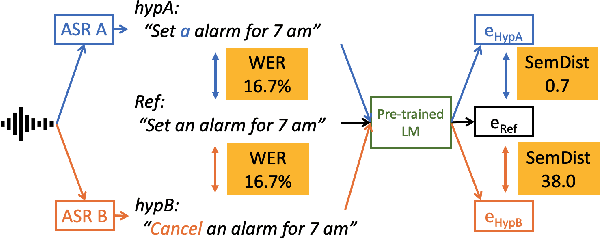
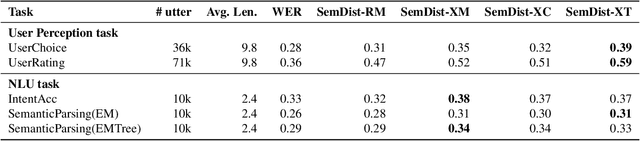
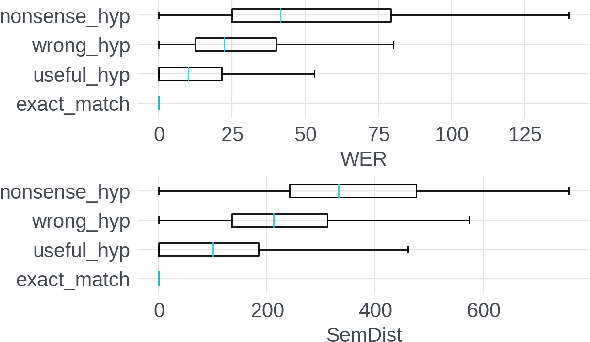
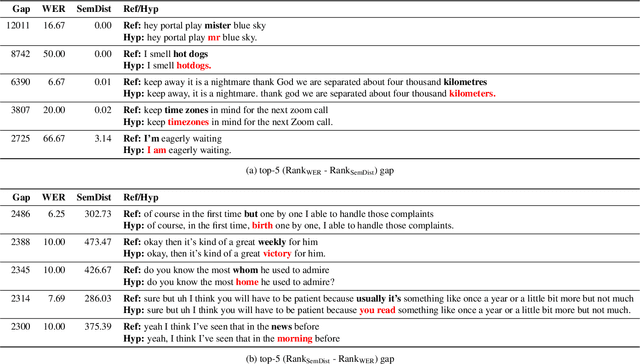
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.
Collaborative Training of Acoustic Encoders for Speech Recognition
Jul 13, 2021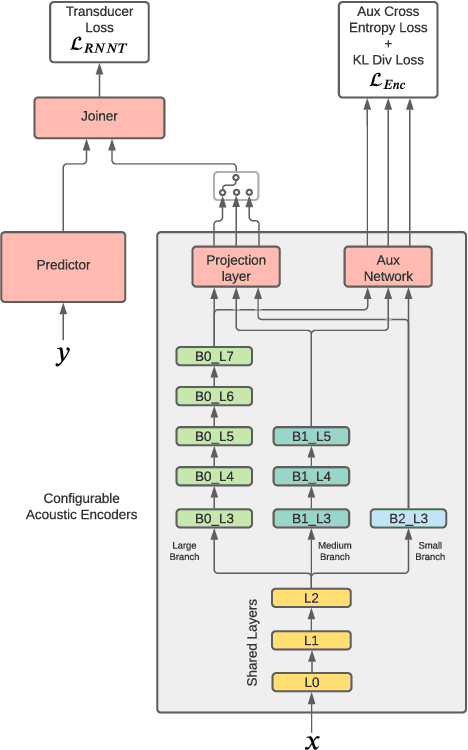
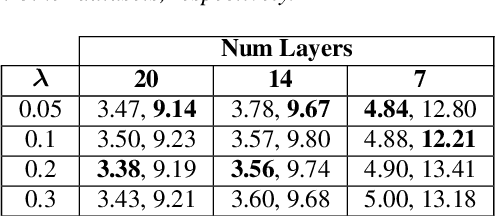
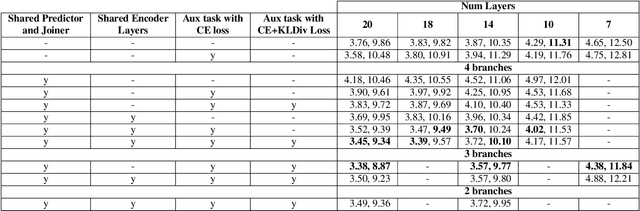
On-device speech recognition requires training models of different sizes for deploying on devices with various computational budgets. When building such different models, we can benefit from training them jointly to take advantage of the knowledge shared between them. Joint training is also efficient since it reduces the redundancy in the training procedure's data handling operations. We propose a method for collaboratively training acoustic encoders of different sizes for speech recognition. We use a sequence transducer setup where different acoustic encoders share a common predictor and joiner modules. The acoustic encoders are also trained using co-distillation through an auxiliary task for frame level chenone prediction, along with the transducer loss. We perform experiments using the LibriSpeech corpus and demonstrate that the collaboratively trained acoustic encoders can provide up to a 11% relative improvement in the word error rate on both the test partitions.