 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNN-T Models Fail to Generalize to Out-of-Domain Audio: Causes and Solutions
Paper and Code
May 17, 2020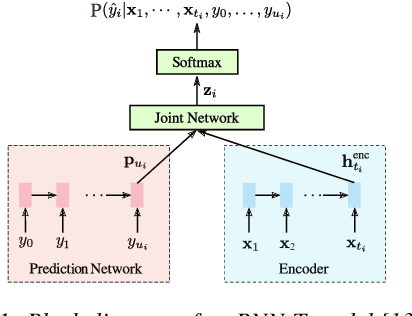
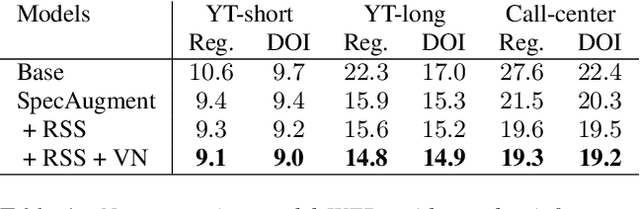
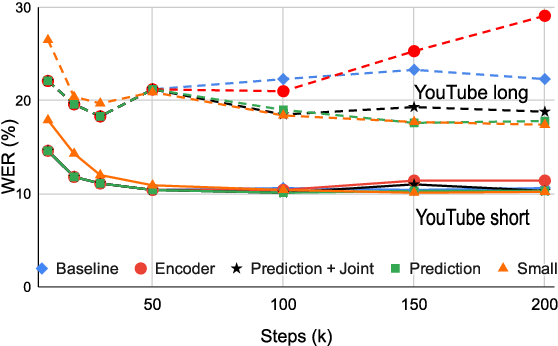
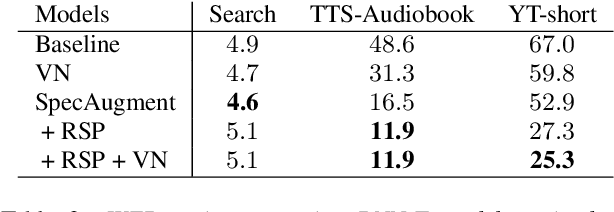
In recent years, all-neural end-to-end approaches have obtained state-of-the-art results on several challenging automatic speech recognition (ASR) tasks. However, most existing works focus on building ASR models where train and test data are drawn from the same domain. This results in poor generalization characteristics on mismatched-domains: e.g., end-to-end models trained on short segments perform poorly when evaluated on longer utterances. In this work, we analyze the generalization properties of streaming and non-streaming recurrent neural network transducer (RNN-T) based end-to-end models in order to identify model components that negatively affect generalization performance. We propose two solutions: combining multiple regularization techniques during training, and using dynamic overlapping inference. On a long-form YouTube test set, when the non-streaming RNN-T model is trained with shorter segments of data, the proposed combination improves word error rate (WER) from 22.3% to 14.8%; when the streaming RNN-T model trained on short Search queries, the proposed techniques improve WER on the YouTube set from 67.0% to 25.3%. Finally, when trained on Librispeech, we find that dynamic overlapping inference improves WER on YouTube from 99.8% to 33.0%.