 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Dynamic Environments with Scene Graph Memory
Jun 12, 2023Embodied AI agents that search for objects in large environments such as households often need to make efficient decisions by predicting object locations based on partial information. We pose this as a new type of link prediction problem: link prediction on partially observable dynamic graphs. Our graph is a representation of a scene in which rooms and objects are nodes, and their relationships are encoded in the edges; only parts of the changing graph are known to the agent at each timestep. This partial observability poses a challenge to existing link prediction approaches, which we address. We propose a novel state representation -- Scene Graph Memory (SGM) -- with captures the agent's accumulated set of observations, as well as a neural net architecture called a Node Edge Predictor (NEP) that extracts information from the SGM to search efficiently. We evaluate our method in the Dynamic House Simulator, a new benchmark that creates diverse dynamic graphs following the semantic patterns typically seen at homes, and show that NEP can be trained to predict the locations of objects in a variety of environments with diverse object movement dynamics, outperforming baselines both in terms of new scene adaptability and overall accuracy. The codebase and more can be found at https://www.scenegraphmemory.com.
ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
May 18, 2023Recent advancements in multimodal pre-training methods have shown promising efficacy in 3D representation learning by aligning multimodal features across 3D shapes, their 2D counterparts, and language descriptions. However, the methods used by existing multimodal pre-training frameworks to gather multimodal data for 3D applications lack scalability and comprehensiveness, potentially constraining the full potential of multimodal learning. The main bottleneck lies in the language modality's scalability and comprehensiveness. To address this, we introduce ULIP-2, a tri-modal pre-training framework that leverages state-of-the-art large multimodal models to automatically generate holistic language counterparts for 3D objects. It does not require any 3D annotations, and is therefore scalable to large datasets. We conduct experiments on two large-scale 3D datasets, Objaverse and ShapeNet, and augment them with tri-modal datasets of 3D point clouds, images, and language for training ULIP-2. ULIP-2 achieves significant improvements on downstream zero-shot classification on ModelNet40 (74.0% in top-1 accuracy); on the real-world ScanObjectNN benchmark, it obtains 91.5% in overall accuracy with only 1.4 million parameters, signifying a breakthrough in scalable multimodal 3D representation learning without human 3D annotations. The code, along with the generated tri-modal datasets, can be found at https://github.com/salesforce/ULIP.
Causal Policy Gradient for Whole-Body Mobile Manipulation
May 11, 2023Developing the next generation of household robot helpers requires combining locomotion and interaction capabilities, which is generally referred to as mobile manipulation (MoMa). MoMa tasks are difficult due to the large action space of the robot and the common multi-objective nature of the task, e.g., efficiently reaching a goal while avoiding obstacles. Current approaches often segregate tasks into navigation without manipulation and stationary manipulation without locomotion by manually matching parts of the action space to MoMa sub-objectives (e.g. base actions for locomotion objectives and arm actions for manipulation). This solution prevents simultaneous combinations of locomotion and interaction degrees of freedom and requires human domain knowledge for both partitioning the action space and matching the action parts to the sub-objectives. In this paper, we introduce Causal MoMa, a new framework to train policies for typical MoMa tasks that makes use of the most favorable subspace of the robot's action space to address each sub-objective. Causal MoMa automatically discovers the causal dependencies between actions and terms of the reward function and exploits these dependencies in a causal policy learning procedure that reduces gradient variance compared to previous state-of-the-art policy gradient algorithms, improving convergence and results. We evaluate the performance of Causal MoMa on three types of simulated robots across different MoMa tasks and demonstrate success in transferring the policies trained in simulation directly to a real robot, where our agent is able to follow moving goals and react to dynamic obstacles while simultaneously and synergistically controlling the whole-body: base, arm, and head. More information at https://sites.google.com/view/causal-moma.
Procedure-Aware Pretraining for Instructional Video Understanding
Mar 31, 2023



Our goal is to learn a video representation that is useful for downstream procedure understanding tasks in instructional videos. Due to the small amount of available annotations, a key challenge in procedure understanding is to be able to extract from unlabeled videos the procedural knowledge such as the identity of the task (e.g., 'make latte'), its steps (e.g., 'pour milk'), or the potential next steps given partial progress in its execution. Our main insight is that instructional videos depict sequences of steps that repeat between instances of the same or different tasks, and that this structure can be well represented by a Procedural Knowledge Graph (PKG), where nodes are discrete steps and edges connect steps that occur sequentially in the instructional activities. This graph can then be used to generate pseudo labels to train a video representation that encodes the procedural knowledge in a more accessible form to generalize to multiple procedure understanding tasks. We build a PKG by combining information from a text-based procedural knowledge database and an unlabeled instructional video corpus and then use it to generate training pseudo labels with four novel pre-training objectives. We call this PKG-based pre-training procedure and the resulting model Paprika, Procedure-Aware PRe-training for Instructional Knowledge Acquisition. We evaluate Paprika on COIN and CrossTask for procedure understanding tasks such as task recognition, step recognition, and step forecasting. Paprika yields a video representation that improves over the state of the art: up to 11.23% gains in accuracy in 12 evaluation settings. Implementation is available at https://github.com/salesforce/paprika.
Model-Agnostic Hierarchical Attention for 3D Object Detection
Jan 06, 2023



Transformers as versatile network architectures have recently seen great success in 3D point cloud object detection. However, the lack of hierarchy in a plain transformer makes it difficult to learn features at different scales and restrains its ability to extract localized features. Such limitation makes them have imbalanced performance on objects of different sizes, with inferior performance on smaller ones. In this work, we propose two novel attention mechanisms as modularized hierarchical designs for transformer-based 3D detectors. To enable feature learning at different scales, we propose Simple Multi-Scale Attention that builds multi-scale tokens from a single-scale input feature. For localized feature aggregation, we propose Size-Adaptive Local Attention with adaptive attention ranges for every bounding box proposal. Both of our attention modules are model-agnostic network layers that can be plugged into existing point cloud transformers for end-to-end training. We evaluate our method on two widely used indoor 3D point cloud object detection benchmarks. By plugging our proposed modules into the state-of-the-art transformer-based 3D detector, we improve the previous best results on both benchmarks, with the largest improvement margin on small objects.
ULIP: Learning Unified Representation of Language, Image and Point Cloud for 3D Understanding
Dec 10, 2022



The understanding capabilities of current state-of-the-art 3D models are limited by datasets with a small number of annotated data and a pre-defined set of categories. In its 2D counterpart, recent advances have shown that similar problems can be significantly alleviated by employing knowledge from other modalities, such as language. Inspired by this, leveraging multimodal information for 3D modality could be promising to improve 3D understanding under the restricted data regime, but this line of research is not well studied. Therefore, we introduce ULIP to learn a unified representation of image, text, and 3D point cloud by pre-training with object triplets from the three modalities. To overcome the shortage of training triplets, ULIP leverages a pre-trained vision-language model that has already learned a common visual and textual space by training with massive image-text pairs. Then, ULIP learns a 3D representation space aligned with the common image-text space, using a small number of automatically synthesized triplets. ULIP is agnostic to 3D backbone networks and can easily be integrated into any 3D architecture. Experiments show that ULIP effectively improves the performance of multiple recent 3D backbones by simply pre-training them on ShapeNet55 using our framework, achieving state-of-the-art performance in both standard 3D classification and zero-shot 3D classification on ModelNet40 and ScanObjectNN. ULIP also improves the performance of PointMLP by around 3% in 3D classification on ScanObjectNN, and outperforms PointCLIP by 28.8% on top-1 accuracy for zero-shot 3D classification on ModelNet40. Our code and pre-trained models will be released.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

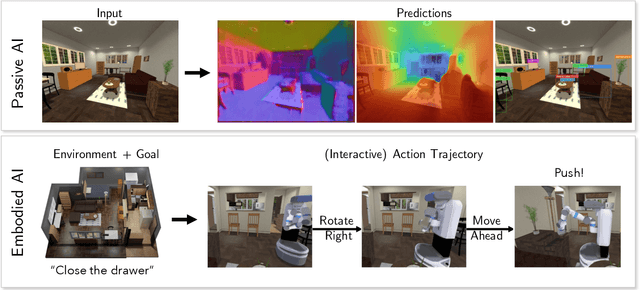
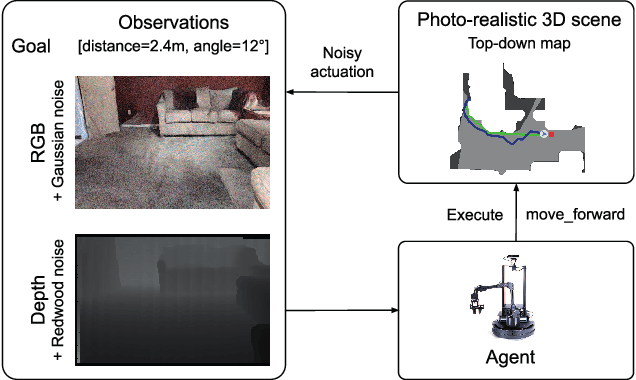
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
MaskViT: Masked Visual Pre-Training for Video Prediction
Jun 23, 2022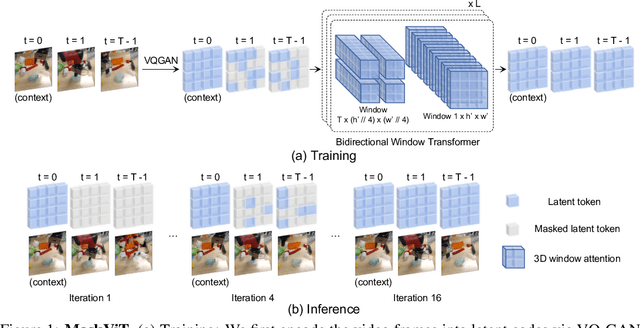
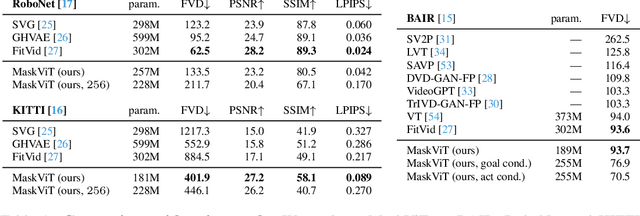
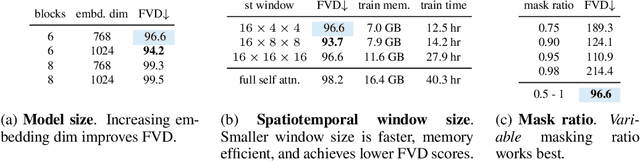

The ability to predict future visual observations conditioned on past observations and motor commands can enable embodied agents to plan solutions to a variety of tasks in complex environments. This work shows that we can create good video prediction models by pre-training transformers via masked visual modeling. Our approach, named MaskViT, is based on two simple design decisions. First, for memory and training efficiency, we use two types of window attention: spatial and spatiotemporal. Second, during training, we mask a variable percentage of tokens instead of a fixed mask ratio. For inference, MaskViT generates all tokens via iterative refinement where we incrementally decrease the masking ratio following a mask scheduling function. On several datasets we demonstrate that MaskViT outperforms prior works in video prediction, is parameter efficient, and can generate high-resolution videos (256x256). Further, we demonstrate the benefits of inference speedup (up to 512x) due to iterative decoding by using MaskViT for planning on a real robot. Our work suggests that we can endow embodied agents with powerful predictive models by leveraging the general framework of masked visual modeling with minimal domain knowledge.
BEHAVIOR in Habitat 2.0: Simulator-Independent Logical Task Description for Benchmarking Embodied AI Agents
Jun 13, 2022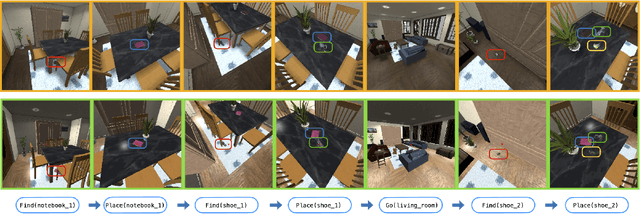
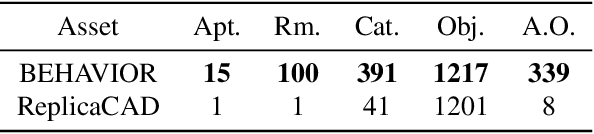
Robots excel in performing repetitive and precision-sensitive tasks in controlled environments such as warehouses and factories, but have not been yet extended to embodied AI agents providing assistance in household tasks. Inspired by the catalyzing effect that benchmarks have played in the AI fields such as computer vision and natural language processing, the community is looking for new benchmarks for embodied AI. Prior work in embodied AI benchmark defines tasks using a different formalism, often specific to one environment, simulator or domain, making it hard to develop general and comparable solutions. In this work, we bring a subset of BEHAVIOR activities into Habitat 2.0 to benefit from its fast simulation speed, as a first step towards demonstrating the ease of adapting activities defined in the logic space into different simulators.
Error-Aware Imitation Learning from Teleoperation Data for Mobile Manipulation
Dec 09, 2021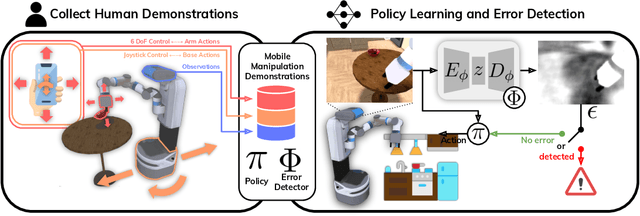
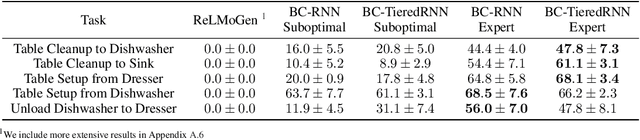

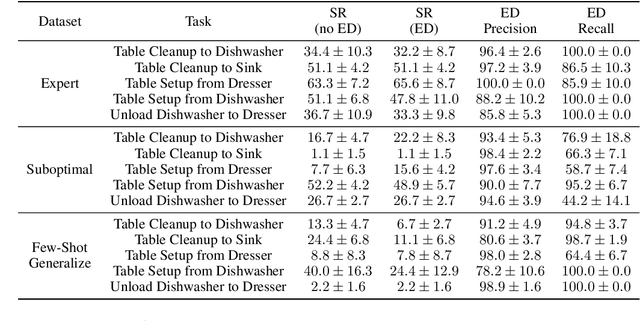
In mobile manipulation (MM), robots can both navigate within and interact with their environment and are thus able to complete many more tasks than robots only capable of navigation or manipulation. In this work, we explore how to apply imitation learning (IL) to learn continuous visuo-motor policies for MM tasks. Much prior work has shown that IL can train visuo-motor policies for either manipulation or navigation domains, but few works have applied IL to the MM domain. Doing this is challenging for two reasons: on the data side, current interfaces make collecting high-quality human demonstrations difficult, and on the learning side, policies trained on limited data can suffer from covariate shift when deployed. To address these problems, we first propose Mobile Manipulation RoboTurk (MoMaRT), a novel teleoperation framework allowing simultaneous navigation and manipulation of mobile manipulators, and collect a first-of-its-kind large scale dataset in a realistic simulated kitchen setting. We then propose a learned error detection system to address the covariate shift by detecting when an agent is in a potential failure state. We train performant IL policies and error detectors from this data, and achieve over 45% task success rate and 85% error detection success rate across multiple multi-stage tasks when trained on expert data. Codebase, datasets, visualization, and more available at https://sites.google.com/view/il-for-mm/home.