 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Cybathlon: On-demand Quadrupedal Assistance for People with Limited Mobility
Mar 17, 2026Background: Assistance robots have the potential to increase the independence of people who need daily care due to limited mobility or being wheelchair-bound. Current solutions of attaching robotic arms to motorized wheelchairs offer limited additional mobility at the cost of increased size and reduced wheelchair maneuverability. Methods: We present an on-demand quadrupedal assistance robot system controlled via a shared autonomy approach, which combines semi-autonomous task execution with human teleoperation. Due to the mobile nature of the system it can assist the operator whenever needed and perform autonomous tasks independently, without otherwise restricting their mobility. We automate pick-and-place tasks, as well as robot movement through the environment with semantic, collision-aware navigation. For teleoperation, we present a mouth-level joystick interface that enables an operator with reduced mobility to control the robot's end effector for precision manipulation. Results: We showcase our system in the \textit{Cybathlon 2024 Assistance Robot Race}, and validate it in an at-home experimental setup, where we measure task completion times and user satisfaction. We find our system capable of assisting in a broad variety of tasks, including those that require dexterous manipulation. The user study confirms the intuition that increased robot autonomy alleviates the operator's mental load. Conclusions: We present a flexible system that has the potential to help people in wheelchairs maintain independence in everyday life by enabling them to solve mobile manipulation problems without external support. We achieve results comparable to previous state-of-the-art on subjective metrics while allowing for more autonomy of the operator and greater agility for manipulation.
Latent Forcing: Reordering the Diffusion Trajectory for Pixel-Space Image Generation
Feb 11, 2026Latent diffusion models excel at generating high-quality images but lose the benefits of end-to-end modeling. They discard information during image encoding, require a separately trained decoder, and model an auxiliary distribution to the raw data. In this paper, we propose Latent Forcing, a simple modification to existing architectures that achieves the efficiency of latent diffusion while operating on raw natural images. Our approach orders the denoising trajectory by jointly processing latents and pixels with separately tuned noise schedules. This allows the latents to act as a scratchpad for intermediate computation before high-frequency pixel features are generated. We find that the order of conditioning signals is critical, and we analyze this to explain differences between REPA distillation in the tokenizer and the diffusion model, conditional versus unconditional generation, and how tokenizer reconstruction quality relates to diffusability. Applied to ImageNet, Latent Forcing achieves a new state-of-the-art for diffusion transformer-based pixel generation at our compute scale.
Less Is More: Scalable Visual Navigation from Limited Data
Jan 25, 2026Imitation learning provides a powerful framework for goal-conditioned visual navigation in mobile robots, enabling obstacle avoidance while respecting human preferences and social norms. However, its effectiveness depends critically on the quality and diversity of training data. In this work, we show how classical geometric planners can be leveraged to generate synthetic trajectories that complement costly human demonstrations. We train Less is More (LiMo), a transformer-based visual navigation policy that predicts goal-conditioned SE(2) trajectories from a single RGB observation, and find that augmenting limited expert demonstrations with planner-generated supervision yields substantial performance gains. Through ablations and complementary qualitative and quantitative analyses, we characterize how dataset scale and diversity affect planning performance. We demonstrate real-robot deployment and argue that robust visual navigation is enabled not by simply collecting more demonstrations, but by strategically curating diverse, high-quality datasets. Our results suggest that scalable, embodiment-specific geometric supervision is a practical path toward data-efficient visual navigation.
ViBES: A Conversational Agent with Behaviorally-Intelligent 3D Virtual Body
Dec 16, 2025



Human communication is inherently multimodal and social: words, prosody, and body language jointly carry intent. Yet most prior systems model human behavior as a translation task co-speech gesture or text-to-motion that maps a fixed utterance to motion clips-without requiring agentic decision-making about when to move, what to do, or how to adapt across multi-turn dialogue. This leads to brittle timing, weak social grounding, and fragmented stacks where speech, text, and motion are trained or inferred in isolation. We introduce ViBES (Voice in Behavioral Expression and Synchrony), a conversational 3D agent that jointly plans language and movement and executes dialogue-conditioned body actions. Concretely, ViBES is a speech-language-behavior (SLB) model with a mixture-of-modality-experts (MoME) backbone: modality-partitioned transformer experts for speech, facial expression, and body motion. The model processes interleaved multimodal token streams with hard routing by modality (parameters are split per expert), while sharing information through cross-expert attention. By leveraging strong pretrained speech-language models, the agent supports mixed-initiative interaction: users can speak, type, or issue body-action directives mid-conversation, and the system exposes controllable behavior hooks for streaming responses. We further benchmark on multi-turn conversation with automatic metrics of dialogue-motion alignment and behavior quality, and observe consistent gains over strong co-speech and text-to-motion baselines. ViBES goes beyond "speech-conditioned motion generation" toward agentic virtual bodies where language, prosody, and movement are jointly generated, enabling controllable, socially competent 3D interaction. Code and data will be made available at: ai.stanford.edu/~juze/ViBES/
BAgger: Backwards Aggregation for Mitigating Drift in Autoregressive Video Diffusion Models
Dec 12, 2025



Autoregressive video models are promising for world modeling via next-frame prediction, but they suffer from exposure bias: a mismatch between training on clean contexts and inference on self-generated frames, causing errors to compound and quality to drift over time. We introduce Backwards Aggregation (BAgger), a self-supervised scheme that constructs corrective trajectories from the model's own rollouts, teaching it to recover from its mistakes. Unlike prior approaches that rely on few-step distillation and distribution-matching losses, which can hurt quality and diversity, BAgger trains with standard score or flow matching objectives, avoiding large teachers and long-chain backpropagation through time. We instantiate BAgger on causal diffusion transformers and evaluate on text-to-video, video extension, and multi-prompt generation, observing more stable long-horizon motion and better visual consistency with reduced drift.
Experience is the Best Teacher: Grounding VLMs for Robotics through Self-Generated Memory
Jul 22, 2025Vision-language models (VLMs) have been widely adopted in robotics to enable autonomous planning. However, grounding VLMs, originally trained on internet data, to diverse real-world robots remains a challenge. This paper presents ExpTeach, a framework that grounds VLMs to physical robots by building a self-generated memory of real-world experiences. In ExpTeach, the VLM autonomously plans actions, verifies outcomes, reflects on failures, and adapts robot behaviors in a closed loop. The self-generated experiences during this process are then summarized into a long-term memory, enabling retrieval of learned knowledge to guide future tasks via retrieval-augmented generation (RAG). Additionally, ExpTeach enhances the spatial understanding of VLMs with an on-demand image annotation module. In experiments, we show that reflection improves success rates from 36% to 84% on four challenging robotic tasks and observe the emergence of intelligent object interactions, including creative tool use. Across extensive tests on 12 real-world scenarios (including eight unseen ones), we find that grounding with long-term memory boosts single-trial success rates from 22% to 80%, demonstrating the effectiveness and generalizability of ExpTeach.
Interspatial Attention for Efficient 4D Human Video Generation
May 21, 2025



Generating photorealistic videos of digital humans in a controllable manner is crucial for a plethora of applications. Existing approaches either build on methods that employ template-based 3D representations or emerging video generation models but suffer from poor quality or limited consistency and identity preservation when generating individual or multiple digital humans. In this paper, we introduce a new interspatial attention (ISA) mechanism as a scalable building block for modern diffusion transformer (DiT)--based video generation models. ISA is a new type of cross attention that uses relative positional encodings tailored for the generation of human videos. Leveraging a custom-developed video variation autoencoder, we train a latent ISA-based diffusion model on a large corpus of video data. Our model achieves state-of-the-art performance for 4D human video synthesis, demonstrating remarkable motion consistency and identity preservation while providing precise control of the camera and body poses. Our code and model are publicly released at https://dsaurus.github.io/isa4d/.
Learning Activity View-invariance Under Extreme Viewpoint Changes via Curriculum Knowledge Distillation
Apr 07, 2025
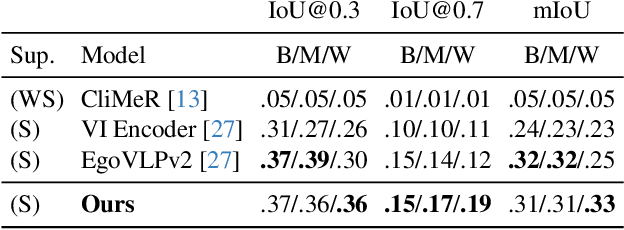

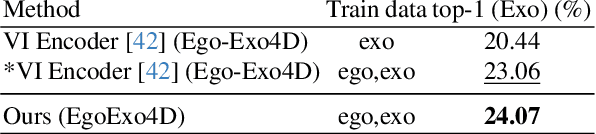
Traditional methods for view-invariant learning from video rely on controlled multi-view settings with minimal scene clutter. However, they struggle with in-the-wild videos that exhibit extreme viewpoint differences and share little visual content. We introduce a method for learning rich video representations in the presence of such severe view-occlusions. We first define a geometry-based metric that ranks views at a fine-grained temporal scale by their likely occlusion level. Then, using those rankings, we formulate a knowledge distillation objective that preserves action-centric semantics with a novel curriculum learning procedure that pairs incrementally more challenging views over time, thereby allowing smooth adaptation to extreme viewpoint differences. We evaluate our approach on two tasks, outperforming SOTA models on both temporal keystep grounding and fine-grained keystep recognition benchmarks - particularly on views that exhibit severe occlusion.
SocialGen: Modeling Multi-Human Social Interaction with Language Models
Mar 28, 2025Human interactions in everyday life are inherently social, involving engagements with diverse individuals across various contexts. Modeling these social interactions is fundamental to a wide range of real-world applications. In this paper, we introduce SocialGen, the first unified motion-language model capable of modeling interaction behaviors among varying numbers of individuals, to address this crucial yet challenging problem. Unlike prior methods that are limited to two-person interactions, we propose a novel social motion representation that supports tokenizing the motions of an arbitrary number of individuals and aligning them with the language space. This alignment enables the model to leverage rich, pretrained linguistic knowledge to better understand and reason about human social behaviors. To tackle the challenges of data scarcity, we curate a comprehensive multi-human interaction dataset, SocialX, enriched with textual annotations. Leveraging this dataset, we establish the first comprehensive benchmark for multi-human interaction tasks. Our method achieves state-of-the-art performance across motion-language tasks, setting a new standard for multi-human interaction modeling.
The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
Dec 13, 2024Human communication is inherently multimodal, involving a combination of verbal and non-verbal cues such as speech, facial expressions, and body gestures. Modeling these behaviors is essential for understanding human interaction and for creating virtual characters that can communicate naturally in applications like games, films, and virtual reality. However, existing motion generation models are typically limited to specific input modalities -- either speech, text, or motion data -- and cannot fully leverage the diversity of available data. In this paper, we propose a novel framework that unifies verbal and non-verbal language using multimodal language models for human motion understanding and generation. This model is flexible in taking text, speech, and motion or any combination of them as input. Coupled with our novel pre-training strategy, our model not only achieves state-of-the-art performance on co-speech gesture generation but also requires much less data for training. Our model also unlocks an array of novel tasks such as editable gesture generation and emotion prediction from motion. We believe unifying the verbal and non-verbal language of human motion is essential for real-world applications, and language models offer a powerful approach to achieving this goal. Project page: languageofmotion.github.io.