 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Workload-Router-Pool Architecture for LLM Inference Optimization: A Vision Paper from the vLLM Semantic Router Project
Mar 22, 2026Over the past year, the vLLM Semantic Router project has released a series of work spanning: (1) core routing mechanisms -- signal-driven routing, context-length pool routing, router performance engineering, policy conflict detection, low-latency embedding models, category-aware semantic caching, user-feedback-driven routing adaptation, hallucination detection, and hierarchical content-safety classification for privacy and jailbreak protection; (2) fleet optimization -- fleet provisioning and energy-efficiency analysis; (3) agentic and multimodal routing -- multimodal agent routing, tool selection, CUA security, and multi-turn context memory and safety; (4) governance and standards -- inference routing protocols and multi-provider API extensions. Each paper tackled a specific problem in LLM inference, but the problems are not independent; for example, fleet provisioning depends on the routing policy, which depends on the workload mix, shifting as organizations adopt agentic and multimodal workloads. This paper distills those results into the Workload-Router-Pool (WRP) architecture, a three-dimensional framework for LLM inference optimization. Workload characterizes what the fleet serves (chat vs. agent, single-turn vs. multi-turn, warm vs. cold, prefill-heavy vs. decode-heavy). Router determines how each request is dispatched (static semantic rules, online bandit adaptation, RL-based model selection, quality-aware cascading). Pool defines where inference runs (homogeneous vs. heterogeneous GPU, disaggregated prefill/decode, KV-cache topology). We map our prior work onto a 3x3 WRP interaction matrix, identify which cells we have covered and which remain open, and propose twenty-one concrete research directions at the intersections, each grounded in our prior measurements, tiered by maturity from engineering-ready to open research.
Outcome-Aware Tool Selection for Semantic Routers: Latency-Constrained Learning Without LLM Inference
Mar 13, 2026Semantic routers in LLM inference gateways select tools in the critical request path, where every millisecond of added latency compounds across millions of requests. We propose Outcome-Aware Tool Selection (OATS), which interpolates tool embeddings toward the centroid of queries where they historically succeed -- an offline process that adds no parameters, latency, or GPU cost at serving time. On MetaTool (199~tools, 4,287~queries), this improves NDCG@5 from 0.869 to 0.940; on ToolBench (2,413~APIs), from 0.834 to 0.848. We also evaluate two learned extensions: a 2,625-parameter MLP re-ranker and a 197K-parameter contrastive adapter. The MLP re-ranker hurts or matches baseline when outcome data is sparse relative to the tool set; the contrastive adapter provides comparable gains on MetaTool (NDCG@5: 0.931). All methods are evaluated on the same held-out 30\% test split. The practical takeaway is to start with the zero-cost refinement and add learned components only when data density warrants it. All mechanisms run within single-digit millisecond CPU budgets.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025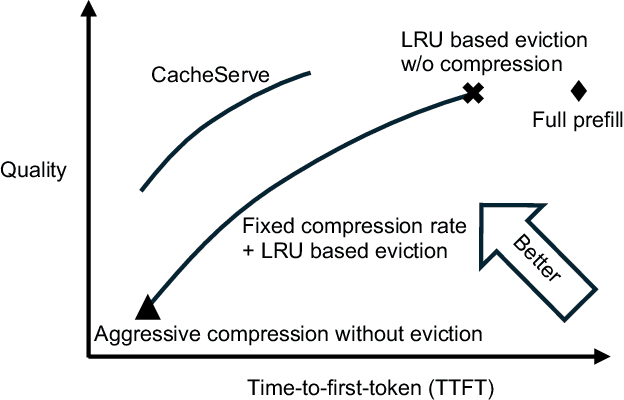
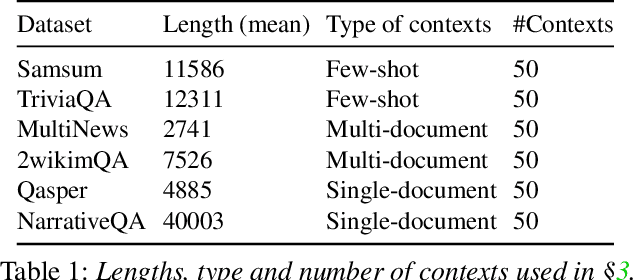
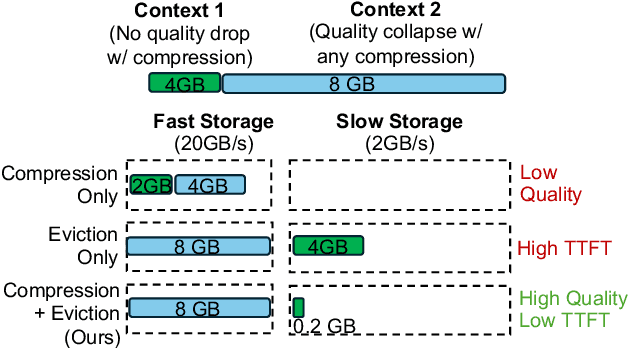
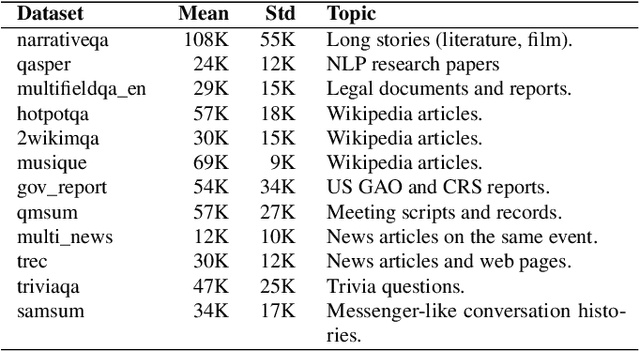
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
RAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
Dec 13, 2024



RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
LLMSteer: Improving Long-Context LLM Inference by Steering Attention on Reused Contexts
Nov 21, 2024

As large language models (LLMs) show impressive performance on complex tasks, they still struggle with longer contextual understanding and high computational costs. To balance efficiency and quality, we introduce LLMSteer, a fine-tuning-free framework that enhances LLMs through query-independent attention steering. Tested on popular LLMs and datasets, LLMSteer narrows the performance gap with baselines by 65.9% and reduces the runtime delay by up to 4.8x compared to recent attention steering methods.
DroidSpeak: Enhancing Cross-LLM Communication
Nov 05, 2024



In multi-agent systems utilizing Large Language Models (LLMs), communication between agents traditionally relies on natural language. This communication often includes the full context of the query so far, which can introduce significant prefill-phase latency, especially with long contexts. We introduce DroidSpeak, a novel framework to target this cross-LLM communication by leveraging the reuse of intermediate data, such as input embeddings (E-cache) and key-value caches (KV-cache). We efficiently bypass the need to reprocess entire contexts for fine-tuned versions of the same foundational model. This approach allows faster context integration while maintaining the quality of task performance. Experimental evaluations demonstrate DroidSpeak's ability to significantly accelerate inter-agent communication, achieving up to a 2.78x speedup in prefill latency with negligible loss in accuracy. Our findings underscore the potential to create more efficient and scalable multi-agent systems.
SwiftQueue: Optimizing Low-Latency Applications with Swift Packet Queuing
Oct 08, 2024



Low Latency, Low Loss, and Scalable Throughput (L4S), as an emerging router-queue management technique, has seen steady deployment in the industry. An L4S-enabled router assigns each packet to the queue based on the packet header marking. Currently, L4S employs per-flow queue selection, i.e. all packets of a flow are marked the same way and thus use the same queues, even though each packet is marked separately. However, this may hurt tail latency and latency-sensitive applications because transient congestion and queue buildups may only affect a fraction of packets in a flow. We present SwiftQueue, a new L4S queue-selection strategy in which a sender uses a novel per-packet latency predictor to pinpoint which packets likely have latency spikes or drops. The insight is that many packet-level latency variations result from complex interactions among recent packets at shared router queues. Yet, these intricate packet-level latency patterns are hard to learn efficiently by traditional models. Instead, SwiftQueue uses a custom Transformer, which is well-studied for its expressiveness on sequential patterns, to predict the next packet's latency based on the latencies of recently received ACKs. Based on the predicted latency of each outgoing packet, SwiftQueue's sender dynamically marks the L4S packet header to assign packets to potentially different queues, even within the same flow. Using real network traces, we show that SwiftQueue is 45-65% more accurate in predicting latency and its variations than state-of-art methods. Based on its latency prediction, SwiftQueue reduces the tail latency for L4S-enabled flows by 36-45%, compared with the existing L4S queue-selection method.
CacheBlend: Fast Large Language Model Serving with Cached Knowledge Fusion
May 26, 2024



Large language models (LLMs) often incorporate multiple text chunks in their inputs to provide the necessary contexts. To speed up the prefill of the long LLM inputs, one can pre-compute the KV cache of a text and re-use the KV cache when the context is reused as the prefix of another LLM input. However, the reused text chunks are not always the input prefix, and when they are not, their precomputed KV caches cannot be directly used since they ignore the text's cross-attention with the preceding text in the LLM input. Thus, the benefits of reusing KV caches remain largely unrealized. This paper tackles just one question: when an LLM input contains multiple text chunks, how to quickly combine their precomputed KV caches in order to achieve the same generation quality as the expensive full prefill (i.e., without reusing KV cache)? We present CacheBlend, a scheme that reuses the pre-computed KV caches, regardless prefix or not, and selectively recomputes the KV values of a small subset of tokens to partially update each reused KV cache. In the meantime,the small extra delay for recomputing some tokens can be pipelined with the retrieval of KV caches within the same job,allowing CacheBlend to store KV caches in slower devices with more storage capacity while retrieving them without increasing the inference delay. By comparing CacheBlend with the state-of-the-art KV cache reusing schemes on three open-source LLMs of various sizes and four popular benchmark datasets of different tasks, we show that CacheBlend reduces time-to-first-token (TTFT) by 2.2-3.3X and increases the inference throughput by 2.8-5X, compared with full KV recompute, without compromising generation quality or incurring more storage cost.
Large Language Model Adaptation for Networking
Feb 04, 2024Many networking tasks now employ deep learning (DL) to solve complex prediction and system optimization problems. However, current design philosophy of DL-based algorithms entails intensive engineering overhead due to the manual design of deep neural networks (DNNs) for different networking tasks. Besides, DNNs tend to achieve poor generalization performance on unseen data distributions/environments. Motivated by the recent success of large language models (LLMs), for the first time, this work studies the LLM adaptation for networking to explore a more sustainable design philosophy. With the massive pre-trained knowledge and powerful inference ability, LLM can serve as the foundation model, and is expected to achieve "one model for all" with even better performance and stronger generalization for various tasks. In this paper, we present NetLLM, the first LLM adaptation framework that efficiently adapts LLMs to solve networking problems. NetLLM addresses many practical challenges in LLM adaptation, from how to process task-specific information with LLMs, to how to improve the efficiency of answer generation and acquiring domain knowledge for networking. Across three networking-related use cases - viewport prediction (VP), adaptive bitrate streaming (ABR) and cluster job scheduling (CJS), we showcase the effectiveness of NetLLM in LLM adaptation for networking. Results show that the adapted LLM surpasses state-of-the-art algorithms by 10.1-36.6% for VP, 14.5-36.6% for ABR, 6.8-41.3% for CJS, and also achieves superior generalization performance.
Chatterbox: Robust Transport for LLM Token Streaming under Unstable Network
Jan 23, 2024



To render each generated token in real time, the LLM server generates response tokens one by one and streams each generated token (or group of a few tokens) through the network to the user right after it is generated, which we refer to as LLM token streaming. However, under unstable network conditions, the LLM token streaming experience could suffer greatly from stalls since one packet loss could block the rendering of tokens contained in subsequent packets even if they arrive on time. With a real-world measurement study, we show that current applications including ChatGPT, Claude, and Bard all suffer from increased stall under unstable network. For this emerging token streaming problem in LLM Chatbots, we propose a novel transport layer scheme, called Chatterbox, which puts new generated tokens as well as currently unacknowledged tokens in the next outgoing packet. This ensures that each packet contains some new tokens and can be independently rendered when received, thus avoiding aforementioned stalls caused by missing packets. Through simulation under various network conditions, we show Chatterbox reduces stall ratio (proportion of token rendering wait time) by 71.0% compared to the token streaming method commonly used by real chatbot applications and by 31.6% compared to a custom packet duplication scheme. By tailoring Chatterbox to fit the token-by-token generation of LLM, we enable the Chatbots to respond like an eloquent speaker for users to better enjoy pervasive AI.