 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Apr 02, 2026Large language model (LLM)-based evolution is a promising approach for open-ended discovery, where progress requires sustained search and knowledge accumulation. Existing methods still rely heavily on fixed heuristics and hard-coded exploration rules, which limit the autonomy of LLM agents. We present CORAL, the first framework for autonomous multi-agent evolution on open-ended problems. CORAL replaces rigid control with long-running agents that explore, reflect, and collaborate through shared persistent memory, asynchronous multi-agent execution, and heartbeat-based interventions. It also provides practical safeguards, including isolated workspaces, evaluator separation, resource management, and agent session and health management. Evaluated on diverse mathematical, algorithmic, and systems optimization tasks, CORAL sets new state-of-the-art results on 10 tasks, achieving 3-10 times higher improvement rates with far fewer evaluations than fixed evolutionary search baselines across tasks. On Anthropic's kernel engineering task, four co-evolving agents improve the best known score from 1363 to 1103 cycles. Mechanistic analyses further show how these gains arise from knowledge reuse and multi-agent exploration and communication. Together, these results suggest that greater agent autonomy and multi-agent evolution can substantially improve open-ended discovery. Code is available at https://github.com/Human-Agent-Society/CORAL.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Oct 06, 2025



Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
Synthetic Document Question Answering in Hungarian
May 29, 2025Modern VLMs have achieved near-saturation accuracy in English document visual question-answering (VQA). However, this task remains challenging in lower resource languages due to a dearth of suitable training and evaluation data. In this paper we present scalable methods for curating such datasets by focusing on Hungarian, approximately the 17th highest resource language on the internet. Specifically, we present HuDocVQA and HuDocVQA-manual, document VQA datasets that modern VLMs significantly underperform on compared to English DocVQA. HuDocVQA-manual is a small manually curated dataset based on Hungarian documents from Common Crawl, while HuDocVQA is a larger synthetically generated VQA data set from the same source. We apply multiple rounds of quality filtering and deduplication to HuDocVQA in order to match human-level quality in this dataset. We also present HuCCPDF, a dataset of 117k pages from Hungarian Common Crawl PDFs along with their transcriptions, which can be used for training a model for Hungarian OCR. To validate the quality of our datasets, we show how finetuning on a mixture of these datasets can improve accuracy on HuDocVQA for Llama 3.2 11B Instruct by +7.2%. Our datasets and code will be released to the public to foster further research in multilingual DocVQA.
Training Domain Draft Models for Speculative Decoding: Best Practices and Insights
Mar 10, 2025

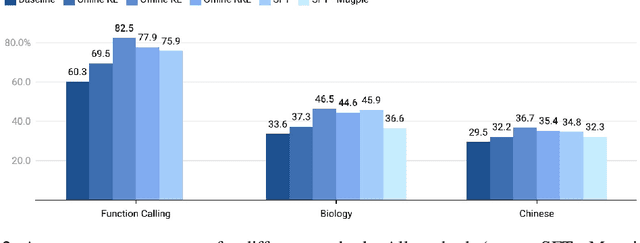

Speculative decoding is an effective method for accelerating inference of large language models (LLMs) by employing a small draft model to predict the output of a target model. However, when adapting speculative decoding to domain-specific target models, the acceptance rate of the generic draft model drops significantly due to domain shift. In this work, we systematically investigate knowledge distillation techniques for training domain draft models to improve their speculation accuracy. We compare white-box and black-box distillation approaches and explore their effectiveness in various data accessibility scenarios, including historical user queries, curated domain data, and synthetically generated alignment data. Our experiments across Function Calling, Biology, and Chinese domains show that offline distillation consistently outperforms online distillation by 11% to 25%, white-box distillation surpasses black-box distillation by 2% to 10%, and data scaling trends hold across domains. Additionally, we find that synthetic data can effectively align draft models and achieve 80% to 93% of the performance of training on historical user queries. These findings provide practical guidelines for training domain-specific draft models to improve speculative decoding efficiency.
On the Tool Manipulation Capability of Open-source Large Language Models
May 25, 2023



Recent studies on software tool manipulation with large language models (LLMs) mostly rely on closed model APIs. The industrial adoption of these models is substantially constrained due to the security and robustness risks in exposing information to closed LLM API services. In this paper, we ask can we enhance open-source LLMs to be competitive to leading closed LLM APIs in tool manipulation, with practical amount of human supervision. By analyzing common tool manipulation failures, we first demonstrate that open-source LLMs may require training with usage examples, in-context demonstration and generation style regulation to resolve failures. These insights motivate us to revisit classical methods in LLM literature, and demonstrate that we can adapt them as model alignment with programmatic data generation, system prompts and in-context demonstration retrievers to enhance open-source LLMs for tool manipulation. To evaluate these techniques, we create the ToolBench, a tool manipulation benchmark consisting of diverse software tools for real-world tasks. We demonstrate that our techniques can boost leading open-source LLMs by up to 90% success rate, showing capabilities competitive to OpenAI GPT-4 in 4 out of 8 ToolBench tasks. We show that such enhancement typically requires about one developer day to curate data for each tool, rendering a recipe with practical amount of human supervision.