 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
Dec 13, 2024



RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
SwiftQueue: Optimizing Low-Latency Applications with Swift Packet Queuing
Oct 08, 2024



Low Latency, Low Loss, and Scalable Throughput (L4S), as an emerging router-queue management technique, has seen steady deployment in the industry. An L4S-enabled router assigns each packet to the queue based on the packet header marking. Currently, L4S employs per-flow queue selection, i.e. all packets of a flow are marked the same way and thus use the same queues, even though each packet is marked separately. However, this may hurt tail latency and latency-sensitive applications because transient congestion and queue buildups may only affect a fraction of packets in a flow. We present SwiftQueue, a new L4S queue-selection strategy in which a sender uses a novel per-packet latency predictor to pinpoint which packets likely have latency spikes or drops. The insight is that many packet-level latency variations result from complex interactions among recent packets at shared router queues. Yet, these intricate packet-level latency patterns are hard to learn efficiently by traditional models. Instead, SwiftQueue uses a custom Transformer, which is well-studied for its expressiveness on sequential patterns, to predict the next packet's latency based on the latencies of recently received ACKs. Based on the predicted latency of each outgoing packet, SwiftQueue's sender dynamically marks the L4S packet header to assign packets to potentially different queues, even within the same flow. Using real network traces, we show that SwiftQueue is 45-65% more accurate in predicting latency and its variations than state-of-art methods. Based on its latency prediction, SwiftQueue reduces the tail latency for L4S-enabled flows by 36-45%, compared with the existing L4S queue-selection method.
CacheBlend: Fast Large Language Model Serving with Cached Knowledge Fusion
May 26, 2024



Large language models (LLMs) often incorporate multiple text chunks in their inputs to provide the necessary contexts. To speed up the prefill of the long LLM inputs, one can pre-compute the KV cache of a text and re-use the KV cache when the context is reused as the prefix of another LLM input. However, the reused text chunks are not always the input prefix, and when they are not, their precomputed KV caches cannot be directly used since they ignore the text's cross-attention with the preceding text in the LLM input. Thus, the benefits of reusing KV caches remain largely unrealized. This paper tackles just one question: when an LLM input contains multiple text chunks, how to quickly combine their precomputed KV caches in order to achieve the same generation quality as the expensive full prefill (i.e., without reusing KV cache)? We present CacheBlend, a scheme that reuses the pre-computed KV caches, regardless prefix or not, and selectively recomputes the KV values of a small subset of tokens to partially update each reused KV cache. In the meantime,the small extra delay for recomputing some tokens can be pipelined with the retrieval of KV caches within the same job,allowing CacheBlend to store KV caches in slower devices with more storage capacity while retrieving them without increasing the inference delay. By comparing CacheBlend with the state-of-the-art KV cache reusing schemes on three open-source LLMs of various sizes and four popular benchmark datasets of different tasks, we show that CacheBlend reduces time-to-first-token (TTFT) by 2.2-3.3X and increases the inference throughput by 2.8-5X, compared with full KV recompute, without compromising generation quality or incurring more storage cost.
Chatterbox: Robust Transport for LLM Token Streaming under Unstable Network
Jan 23, 2024



To render each generated token in real time, the LLM server generates response tokens one by one and streams each generated token (or group of a few tokens) through the network to the user right after it is generated, which we refer to as LLM token streaming. However, under unstable network conditions, the LLM token streaming experience could suffer greatly from stalls since one packet loss could block the rendering of tokens contained in subsequent packets even if they arrive on time. With a real-world measurement study, we show that current applications including ChatGPT, Claude, and Bard all suffer from increased stall under unstable network. For this emerging token streaming problem in LLM Chatbots, we propose a novel transport layer scheme, called Chatterbox, which puts new generated tokens as well as currently unacknowledged tokens in the next outgoing packet. This ensures that each packet contains some new tokens and can be independently rendered when received, thus avoiding aforementioned stalls caused by missing packets. Through simulation under various network conditions, we show Chatterbox reduces stall ratio (proportion of token rendering wait time) by 71.0% compared to the token streaming method commonly used by real chatbot applications and by 31.6% compared to a custom packet duplication scheme. By tailoring Chatterbox to fit the token-by-token generation of LLM, we enable the Chatbots to respond like an eloquent speaker for users to better enjoy pervasive AI.
A new hope for network model generalization
Jul 12, 2022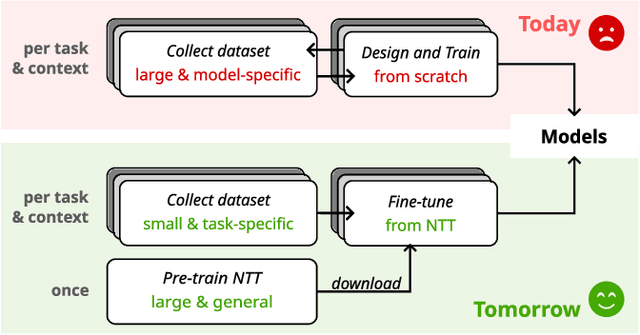
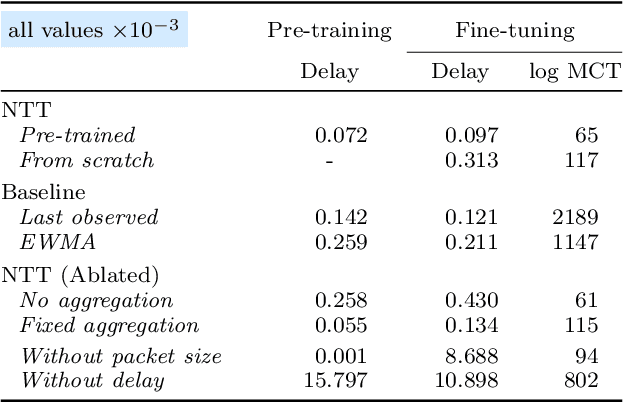
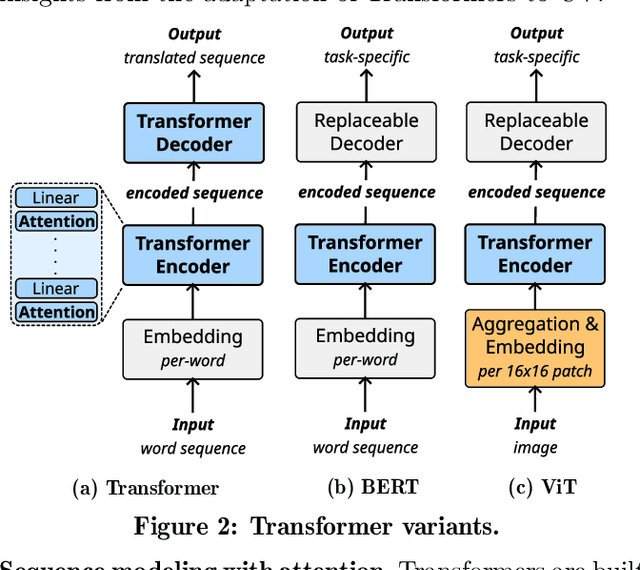
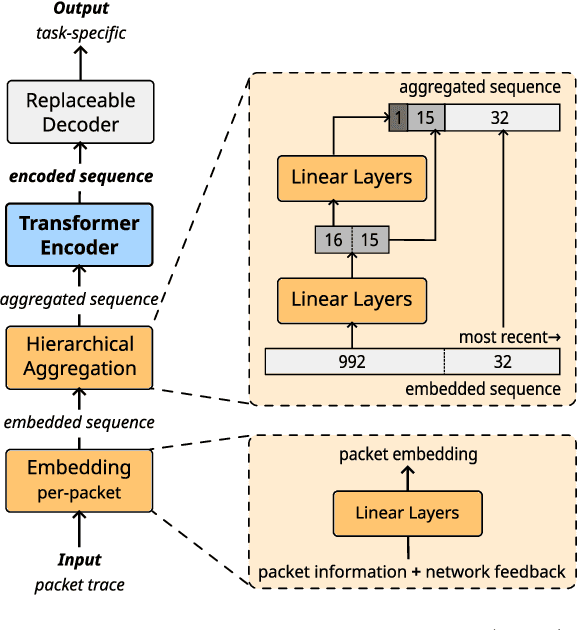
Generalizing machine learning (ML) models for network traffic dynamics tends to be considered a lost cause. Hence, for every new task, we often resolve to design new models and train them on model-specific datasets collected, whenever possible, in an environment mimicking the model's deployment. This approach essentially gives up on generalization. Yet, an ML architecture called_Transformer_ has enabled previously unimaginable generalization in other domains. Nowadays, one can download a model pre-trained on massive datasets and only fine-tune it for a specific task and context with comparatively little time and data. These fine-tuned models are now state-of-the-art for many benchmarks. We believe this progress could translate to networking and propose a Network Traffic Transformer (NTT), a transformer adapted to learn network dynamics from packet traces. Our initial results are promising: NTT seems able to generalize to new prediction tasks and contexts. This study suggests there is still hope for generalization, though it calls for a lot of future research.