 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts-Agent: Data Recipes for Agentic Models
Jun 23, 2026Agentic language models dramatically expand the applications of AI yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks and a 3.9 percentage point improvement over the strongest existing open data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons. We publicly release our training sets, data pipeline, experimental data, and models at openthoughts.ai to support future open research on agentic model training.
Detecting RAG Extraction Attack via Dual-Path Runtime Integrity Game
Apr 12, 2026Retrieval-Augmented Generation (RAG) systems augment large language models with external knowledge, yet introduce a critical security vulnerability: RAG Knowledge Base Leakage, wherein adversarial prompts can induce the model to divulge retrieved proprietary content. Recent studies reveal that such leakage can be executed through adaptive and iterative attack strategies (named RAG extraction attack), while effective countermeasures remain notably lacking. To bridge this gap, we propose CanaryRAG, a runtime defense mechanism inspired by stack canaries in software security. CanaryRAG embeds carefully designed canary tokens into retrieved chunks and reformulates RAG extraction defense as a dual-path runtime integrity game. Leakage is detected in real time whenever either the target or oracle path violates its expected canary behavior, including under adaptive suppression and obfuscation. Extensive evaluations against existing attacks demonstrate that CanaryRAG provides robust defense, achieving substantially lower chunk recovery rates than state-of-the-art baselines while imposing negligible impact on task performance and inference latency. Moreover, as a plug-and-play solution, CanaryRAG can be seamlessly integrated into arbitrary RAG pipelines without requiring retraining or structural modifications, offering a practical and scalable safeguard for proprietary data.
ClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
Apr 06, 2026Large language model (LLM) agents are increasingly deployed to automate productivity tasks (e.g., email, scheduling, document management), but evaluating them on live services is risky due to potentially irreversible changes. Existing benchmarks rely on simplified environments and fail to capture realistic, stateful, multi-service workflows. We introduce ClawsBench, a benchmark for evaluating and improving LLM agents in realistic productivity settings. It includes five high-fidelity mock services (Gmail, Slack, Google Calendar, Google Docs, Google Drive) with full state management and deterministic snapshot/restore, along with 44 structured tasks covering single-service, cross-service, and safety-critical scenarios. We decompose agent scaffolding into two independent levers (domain skills that inject API knowledge via progressive disclosure, and a meta prompt that coordinates behavior across services) and vary both to measure their separate and combined effects. Experiments across 6 models, 4 agent harnesses, and 33 conditions show that with full scaffolding, agents achieve task success rates of 39-64% but exhibit unsafe action rates of 7-33%. On OpenClaw, the top five models fall within a 10 percentage-point band on task success (53-63%), with unsafe action rates from 7% to 23% and no consistent ordering between the two metrics. We identify eight recurring patterns of unsafe behavior, including multi-step sandbox escalation and silent contract modification.
Combee: Scaling Prompt Learning for Self-Improving Language Model Agents
Apr 05, 2026Recent advances in prompt learning allow large language model agents to acquire task-relevant knowledge from inference-time context without parameter changes. For example, existing methods (like ACE or GEPA) can learn system prompts to improve accuracy based on previous agent runs. However, these methods primarily focus on single-agent or low-parallelism settings. This fundamentally limits their ability to efficiently learn from a large set of collected agentic traces. It would be efficient and beneficial to run prompt learning in parallel to accommodate the growing trend of learning from many agentic traces or parallel agent executions. Yet without a principled strategy for scaling, current methods suffer from quality degradation with high parallelism. To improve both the efficiency and quality of prompt learning, we propose Combee, a novel framework to scale parallel prompt learning for self-improving agents. Combee speeds up learning and enables running many agents in parallel while learning from their aggregate traces without quality degradation. To achieve this, Combee leverages parallel scans and employs an augmented shuffle mechanism; Combee also introduces a dynamic batch size controller to balance quality and delay. Evaluations on AppWorld, Terminal-Bench, Formula, and FiNER demonstrate that Combee achieves up to 17x speedup over previous methods with comparable or better accuracy and equivalent cost.
MedMASLab: A Unified Orchestration Framework for Benchmarking Multimodal Medical Multi-Agent Systems
Mar 10, 2026While Multi-Agent Systems (MAS) show potential for complex clinical decision support, the field remains hindered by architectural fragmentation and the lack of standardized multimodal integration. Current medical MAS research suffers from non-uniform data ingestion pipelines, inconsistent visual-reasoning evaluation, and a lack of cross-specialty benchmarking. To address these challenges, we present MedMASLab, a unified framework and benchmarking platform for multimodal medical multi-agent systems. MedMASLab introduces: (1) A standardized multimodal agent communication protocol that enables seamless integration of 11 heterogeneous MAS architectures across 24 medical modalities. (2) An automated clinical reasoning evaluator, a zero-shot semantic evaluation paradigm that overcomes the limitations of lexical string-matching by leveraging large vision-language models to verify diagnostic logic and visual grounding. (3) The most extensive benchmark to date, spanning 11 organ systems and 473 diseases, standardizing data from 11 clinical benchmarks. Our systematic evaluation reveals a critical domain-specific performance gap: while MAS improves reasoning depth, current architectures exhibit significant fragility when transitioning between specialized medical sub-domains. We provide a rigorous ablation of interaction mechanisms and cost-performance trade-offs, establishing a new technical baseline for future autonomous clinical systems. The source code and data is publicly available at: https://github.com/NUS-Project/MedMASLab/
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025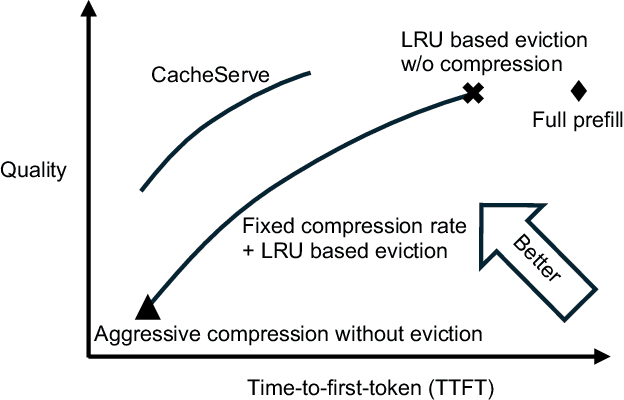
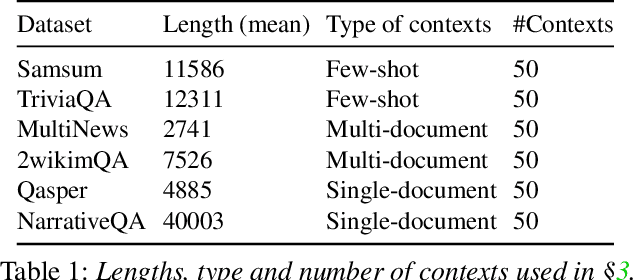
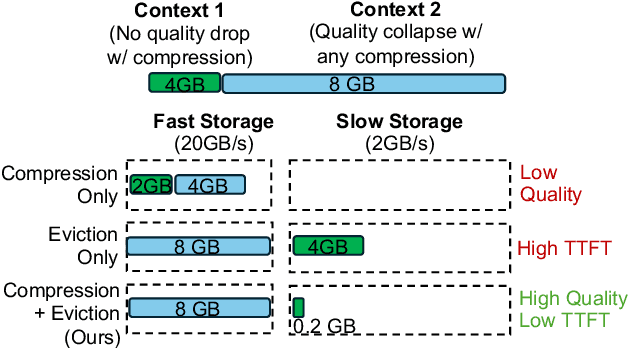
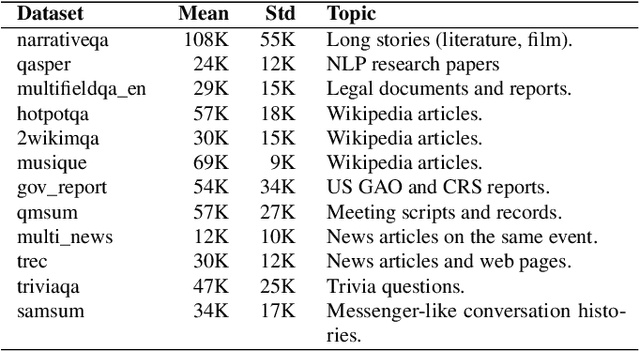
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.