 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Gaze Reasoning in Vision Foundation Models for Gaze Following
May 21, 2026Gaze following requires both scene understanding and gaze reasoning to localize the gaze target of an in-scene person. Recently, vision foundation models (VFMs) have demonstrated strong performance on this task, enabling simpler architectures while outperforming prior methods. However, we observe a key limitation of VFM-based approaches: while VFMs substantially improve scene understanding, they contribute little to gaze reasoning. As a result, existing methods often rely on semantically salient objects rather than true gaze cues, leading to degraded performance when targets are not salient. To address this, we propose a novel training mechanism to enhance gaze reasoning in VFMs for gaze following. Our method includes: (1) a head-conditioned local LoRA, which enables localized adaptation to preserve scene token learning while improving head token learning for gaze reasoning; and (2) an out-of-cone penalty, which injects gaze cues into head tokens while aligning them with scene tokens. Experiments on the GazeFollow and VAT datasets demonstrate that our method achieves state-of-the-art performance, with particularly strong improvements when gaze targets are not semantically salient. Our findings offer valuable insights for advancing future gaze following research. We will release the code once the paper is accepted.
FoSS: Modeling Long Range Dependencies and Multimodal Uncertainty in Trajectory Prediction via Fourier State Space Integration
Mar 01, 2026Accurate trajectory prediction is vital for safe autonomous driving, yet existing approaches struggle to balance modeling power and computational efficiency. Attention-based architectures incur quadratic complexity with increasing agents, while recurrent models struggle to capture long-range dependencies and fine-grained local dynamics. Building upon this, we present FoSS, a dual-branch framework that unifies frequency-domain reasoning with linear-time sequence modeling. The frequency-domain branch performs a discrete Fourier transform to decompose trajectories into amplitude components encoding global intent and phase components capturing local variations, followed by a progressive helix reordering module that preserves spectral order; two selective state-space submodules, Coarse2Fine-SSM and SpecEvolve-SSM, refine spectral features with O(N) complexity. In parallel, a time-domain dynamic selective SSM reconstructs self-attention behavior in linear time to retain long-range temporal context. A cross-attention layer fuses temporal and spectral representations, while learnable queries generate multiple candidate trajectories, and a weighted fusion head expresses motion uncertainty. Experiments on Argoverse 1 and Argoverse 2 benchmarks demonstrate that FoSS achieves state-of-the-art accuracy while reducing computation by 22.5% and parameters by over 40%. Comprehensive ablations confirm the necessity of each component.
VL4Gaze: Unleashing Vision-Language Models for Gaze Following
Dec 23, 2025Human gaze provides essential cues for interpreting attention, intention, and social interaction in visual scenes, yet gaze understanding remains largely unexplored in current vision-language models (VLMs). While recent VLMs achieve strong scene-level reasoning across a range of visual tasks, there exists no benchmark that systematically evaluates or trains them for gaze interpretation, leaving open the question of whether gaze understanding can emerge from general-purpose vision-language pre-training. To address this gap, we introduce VL4Gaze, the first large-scale benchmark designed to investigate, evaluate, and unlock the potential of VLMs for gaze understanding. VL4Gaze contains 489K automatically generated question-answer pairs across 124K images and formulates gaze understanding as a unified VQA problem through four complementary tasks: (1) gaze object description, (2) gaze direction description, (3) gaze point location, and (4) ambiguous question recognition. We comprehensively evaluate both commercial and open-source VLMs under in-context learning and fine-tuning settings. The results show that even large-scale VLMs struggle to reliably infer gaze semantics and spatial localization without task-specific supervision. In contrast, training on VL4Gaze brings substantial and consistent improvements across all tasks, highlighting the importance of targeted multi-task supervision for developing gaze understanding capabilities in VLMs. We will release the dataset and code to support further research and development in this direction.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025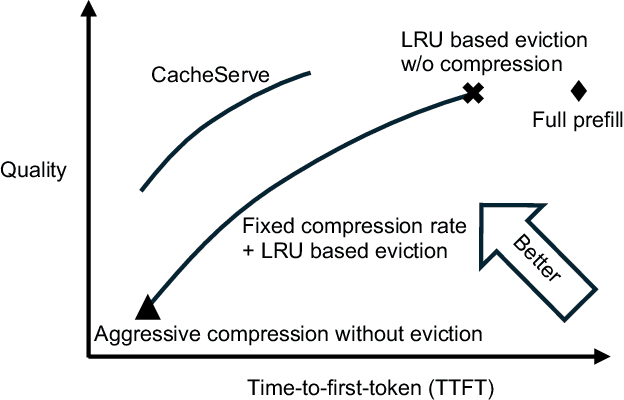
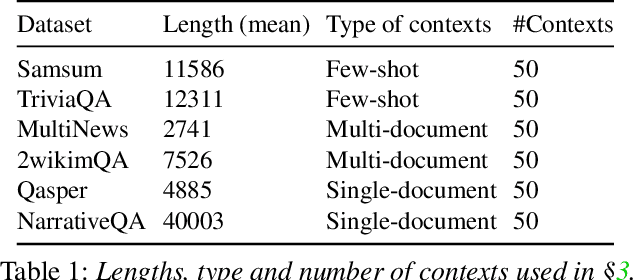
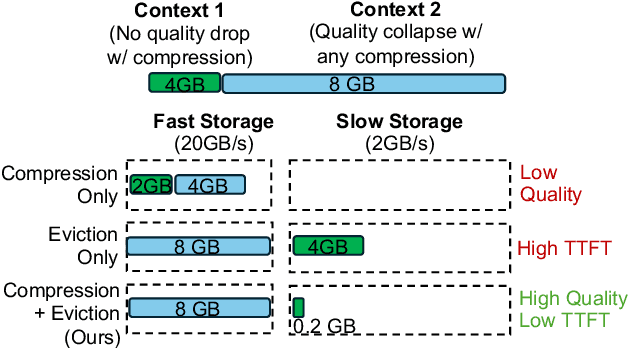
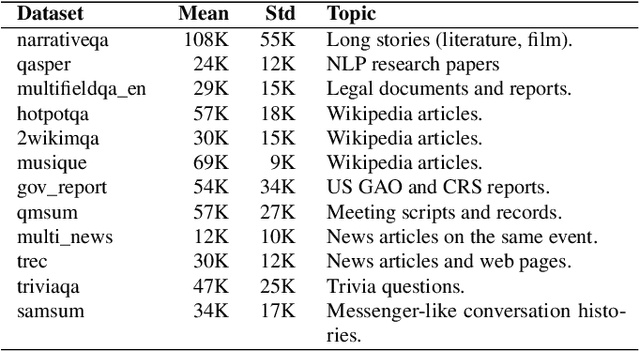
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
RTGaze: Real-Time 3D-Aware Gaze Redirection from a Single Image
Nov 14, 2025Gaze redirection methods aim to generate realistic human face images with controllable eye movement. However, recent methods often struggle with 3D consistency, efficiency, or quality, limiting their practical applications. In this work, we propose RTGaze, a real-time and high-quality gaze redirection method. Our approach learns a gaze-controllable facial representation from face images and gaze prompts, then decodes this representation via neural rendering for gaze redirection. Additionally, we distill face geometric priors from a pretrained 3D portrait generator to enhance generation quality. We evaluate RTGaze both qualitatively and quantitatively, demonstrating state-of-the-art performance in efficiency, redirection accuracy, and image quality across multiple datasets. Our system achieves real-time, 3D-aware gaze redirection with a feedforward network (~0.06 sec/image), making it 800x faster than the previous state-of-the-art 3D-aware methods.
Excavate the potential of Single-Scale Features: A Decomposition Network for Water-Related Optical Image Enhancement
Aug 06, 2025Underwater image enhancement (UIE) techniques aim to improve visual quality of images captured in aquatic environments by addressing degradation issues caused by light absorption and scattering effects, including color distortion, blurring, and low contrast. Current mainstream solutions predominantly employ multi-scale feature extraction (MSFE) mechanisms to enhance reconstruction quality through multi-resolution feature fusion. However, our extensive experiments demonstrate that high-quality image reconstruction does not necessarily rely on multi-scale feature fusion. Contrary to popular belief, our experiments show that single-scale feature extraction alone can match or surpass the performance of multi-scale methods, significantly reducing complexity. To comprehensively explore single-scale feature potential in underwater enhancement, we propose an innovative Single-Scale Decomposition Network (SSD-Net). This architecture introduces an asymmetrical decomposition mechanism that disentangles input image into clean layer along with degradation layer. The former contains scene-intrinsic information and the latter encodes medium-induced interference. It uniquely combines CNN's local feature extraction capabilities with Transformer's global modeling strengths through two core modules: 1) Parallel Feature Decomposition Block (PFDB), implementing dual-branch feature space decoupling via efficient attention operations and adaptive sparse transformer; 2) Bidirectional Feature Communication Block (BFCB), enabling cross-layer residual interactions for complementary feature mining and fusion. This synergistic design preserves feature decomposition independence while establishing dynamic cross-layer information pathways, effectively enhancing degradation decoupling capacity.
Learning Velocity and Acceleration: Self-Supervised Motion Consistency for Pedestrian Trajectory Prediction
Mar 31, 2025Understanding human motion is crucial for accurate pedestrian trajectory prediction. Conventional methods typically rely on supervised learning, where ground-truth labels are directly optimized against predicted trajectories. This amplifies the limitations caused by long-tailed data distributions, making it difficult for the model to capture abnormal behaviors. In this work, we propose a self-supervised pedestrian trajectory prediction framework that explicitly models position, velocity, and acceleration. We leverage velocity and acceleration information to enhance position prediction through feature injection and a self-supervised motion consistency mechanism. Our model hierarchically injects velocity features into the position stream. Acceleration features are injected into the velocity stream. This enables the model to predict position, velocity, and acceleration jointly. From the predicted position, we compute corresponding pseudo velocity and acceleration, allowing the model to learn from data-generated pseudo labels and thus achieve self-supervised learning. We further design a motion consistency evaluation strategy grounded in physical principles; it selects the most reasonable predicted motion trend by comparing it with historical dynamics and uses this trend to guide and constrain trajectory generation. We conduct experiments on the ETH-UCY and Stanford Drone datasets, demonstrating that our method achieves state-of-the-art performance on both datasets.
Trajectory Mamba: Efficient Attention-Mamba Forecasting Model Based on Selective SSM
Mar 13, 2025Motion prediction is crucial for autonomous driving, as it enables accurate forecasting of future vehicle trajectories based on historical inputs. This paper introduces Trajectory Mamba, a novel efficient trajectory prediction framework based on the selective state-space model (SSM). Conventional attention-based models face the challenge of computational costs that grow quadratically with the number of targets, hindering their application in highly dynamic environments. In response, we leverage the SSM to redesign the self-attention mechanism in the encoder-decoder architecture, thereby achieving linear time complexity. To address the potential reduction in prediction accuracy resulting from modifications to the attention mechanism, we propose a joint polyline encoding strategy to better capture the associations between static and dynamic contexts, ultimately enhancing prediction accuracy. Additionally, to balance prediction accuracy and inference speed, we adopted the decoder that differs entirely from the encoder. Through cross-state space attention, all target agents share the scene context, allowing the SSM to interact with the shared scene representation during decoding, thus inferring different trajectories over the next prediction steps. Our model achieves state-of-the-art results in terms of inference speed and parameter efficiency on both the Argoverse 1 and Argoverse 2 datasets. It demonstrates a four-fold reduction in FLOPs compared to existing methods and reduces parameter count by over 40% while surpassing the performance of the vast majority of previous methods. These findings validate the effectiveness of Trajectory Mamba in trajectory prediction tasks.
PersonaBooth: Personalized Text-to-Motion Generation
Mar 10, 2025



This paper introduces Motion Personalization, a new task that generates personalized motions aligned with text descriptions using several basic motions containing Persona. To support this novel task, we introduce a new large-scale motion dataset called PerMo (PersonaMotion), which captures the unique personas of multiple actors. We also propose a multi-modal finetuning method of a pretrained motion diffusion model called PersonaBooth. PersonaBooth addresses two main challenges: i) A significant distribution gap between the persona-focused PerMo dataset and the pretraining datasets, which lack persona-specific data, and ii) the difficulty of capturing a consistent persona from the motions vary in content (action type). To tackle the dataset distribution gap, we introduce a persona token to accept new persona features and perform multi-modal adaptation for both text and visuals during finetuning. To capture a consistent persona, we incorporate a contrastive learning technique to enhance intra-cohesion among samples with the same persona. Furthermore, we introduce a context-aware fusion mechanism to maximize the integration of persona cues from multiple input motions. PersonaBooth outperforms state-of-the-art motion style transfer methods, establishing a new benchmark for motion personalization.
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
Feb 06, 20253D and 2D gaze estimation share the fundamental objective of capturing eye movements but are traditionally treated as two distinct research domains. In this paper, we introduce a novel cross-task few-shot 2D gaze estimation approach, aiming to adapt a pre-trained 3D gaze estimation network for 2D gaze prediction on unseen devices using only a few training images. This task is highly challenging due to the domain gap between 3D and 2D gaze, unknown screen poses, and limited training data. To address these challenges, we propose a novel framework that bridges the gap between 3D and 2D gaze. Our framework contains a physics-based differentiable projection module with learnable parameters to model screen poses and project 3D gaze into 2D gaze. The framework is fully differentiable and can integrate into existing 3D gaze networks without modifying their original architecture. Additionally, we introduce a dynamic pseudo-labelling strategy for flipped images, which is particularly challenging for 2D labels due to unknown screen poses. To overcome this, we reverse the projection process by converting 2D labels to 3D space, where flipping is performed. Notably, this 3D space is not aligned with the camera coordinate system, so we learn a dynamic transformation matrix to compensate for this misalignment. We evaluate our method on MPIIGaze, EVE, and GazeCapture datasets, collected respectively on laptops, desktop computers, and mobile devices. The superior performance highlights the effectiveness of our approach, and demonstrates its strong potential for real-world applications.