 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEEK: Context Map as an Orientation Cache for Long-Context LLM Agents
May 19, 2026Large language model (LLM) agents increasingly operate over long and recurring external contexts, like document corpora and code repositories. Across invocations, existing approaches preserve either the agent's trajectory, passive access to raw material, or task-level strategies. None of them preserves what we argue is most needed for repeated same-context workloads: reusable orientation knowledge (e.g., what the context contains, how it is organized, and which entities, constants, and schemas have historically been useful) about the recurring context itself. We introduce PEEK, a system that caches and maintains this orientation knowledge as a context map: a small, constant-sized artifact in the agent's prompt that gives it a persistent peek into the external context. The map is maintained by a programmable cache policy with three modules: a Distiller that extracts transferable knowledge from inference-time signals, a Cartographer that translates it into structured edits, and a priority-based Evictor that enforces a fixed token budget. On long-context reasoning and information aggregation, PEEK improves over strong baselines by 6.3-34.0% while using 93-145 fewer iterations and incurring 1.7-5.8x lower cost than the state-of-the-art prompt-learning framework, ACE. On context learning, PEEK improves solving rate and rubric accuracy by 6.0-14.0% and 7.8-12.1%, respectively, at 1.4x lower cost than ACE. These gains generalize across LMs and agent architectures, including OpenAI Codex, a production-grade coding agent. Together, these results show that a context map helps long-context LLM agents interact with recurring external contexts more accurately and efficiently.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025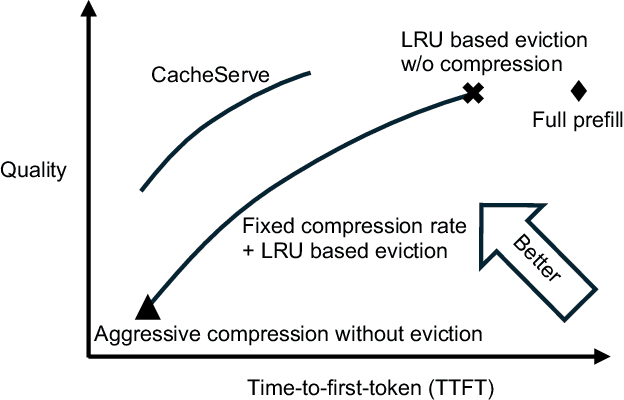
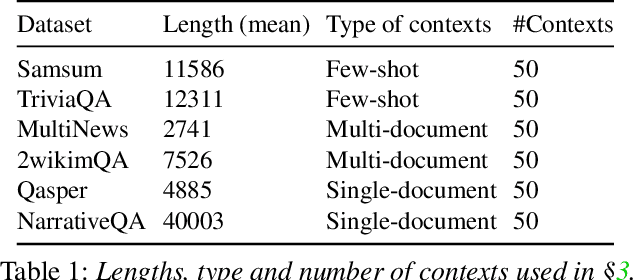
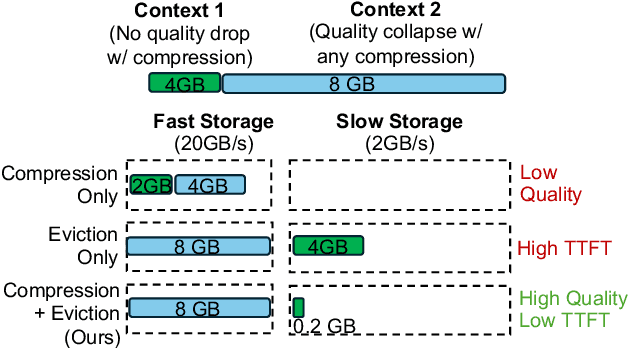
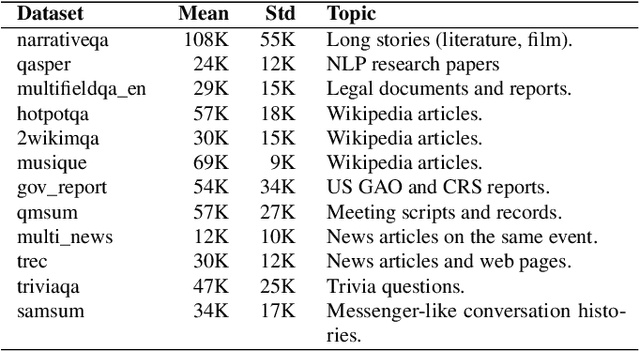
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
RAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
Dec 13, 2024



RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
LLMSteer: Improving Long-Context LLM Inference by Steering Attention on Reused Contexts
Nov 21, 2024

As large language models (LLMs) show impressive performance on complex tasks, they still struggle with longer contextual understanding and high computational costs. To balance efficiency and quality, we introduce LLMSteer, a fine-tuning-free framework that enhances LLMs through query-independent attention steering. Tested on popular LLMs and datasets, LLMSteer narrows the performance gap with baselines by 65.9% and reduces the runtime delay by up to 4.8x compared to recent attention steering methods.