 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Harness: End-to-End Optimization of Model Harnesses
Mar 30, 2026The performance of large language model (LLM) systems depends not only on model weights, but also on their harness: the code that determines what information to store, retrieve, and present to the model. Yet harnesses are still designed largely by hand, and existing text optimizers are poorly matched to this setting because they compress feedback too aggressively. We introduce Meta-Harness, an outer-loop system that searches over harness code for LLM applications. It uses an agentic proposer that accesses the source code, scores, and execution traces of all prior candidates through a filesystem. On online text classification, Meta-Harness improves over a state-of-the-art context management system by 7.7 points while using 4x fewer context tokens. On retrieval-augmented math reasoning, a single discovered harness improves accuracy on 200 IMO-level problems by 4.7 points on average across five held-out models. On agentic coding, discovered harnesses surpass the best hand-engineered baselines on TerminalBench-2. Together, these results show that richer access to prior experience can enable automated harness engineering.
Feedback Descent: Open-Ended Text Optimization via Pairwise Comparison
Nov 11, 2025



We introduce \textit{Feedback Descent}, a framework that optimizes text artifacts -- prompts, code, and molecules -- through structured textual feedback, rather than relying solely on scalar rewards. By preserving detailed critiques instead of compressing them to binary preferences, Feedback Descent widens the information bottleneck in preference learning, enabling directed optimization in text space rather than weight space. We show that in-context learning can transform structured feedback into gradient-like directional information, enabling targeted edits. Unlike prior approaches that collapse judgments into single bits, our evaluators pair each comparison with textual feedback, which functions as high-bandwidth supervision. The iteration loop is done purely at inference time, without modifying any model weights, and is task-agnostic. We evaluate Feedback Descent on three diverse domains and find that it outperforms state-of-the-art prompt optimization (GEPA), reinforcement learning methods (GRPO, REINVENT), and even specialized graph-based molecular optimizers. In the DOCKSTRING molecule discovery benchmark, Feedback Descent identifies novel drug-like molecules surpassing the $99.9$th percentile of a database with more than $260{,}000$ compounds across six protein targets.
RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems
Oct 02, 2025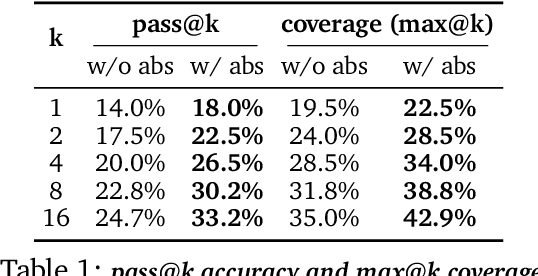
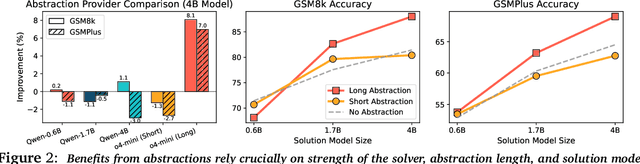
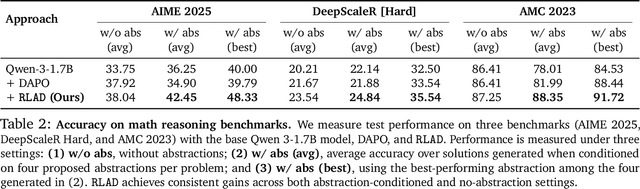
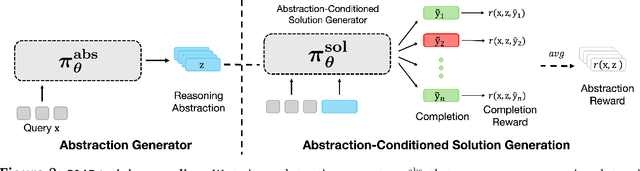
Reasoning requires going beyond pattern matching or memorization of solutions to identify and implement "algorithmic procedures" that can be used to deduce answers to hard problems. Doing so requires realizing the most relevant primitives, intermediate results, or shared procedures, and building upon them. While RL post-training on long chains of thought ultimately aims to uncover this kind of algorithmic behavior, most reasoning traces learned by large models fail to consistently capture or reuse procedures, instead drifting into verbose and degenerate exploration. To address more effective reasoning, we introduce reasoning abstractions: concise natural language descriptions of procedural and factual knowledge that guide the model toward learning successful reasoning. We train models to be capable of proposing multiple abstractions given a problem, followed by RL that incentivizes building a solution while using the information provided by these abstractions. This results in a two-player RL training paradigm, abbreviated as RLAD, that jointly trains an abstraction generator and a solution generator. This setup effectively enables structured exploration, decouples learning signals of abstraction proposal and solution generation, and improves generalization to harder problems. We also show that allocating more test-time compute to generating abstractions is more beneficial for performance than generating more solutions at large test budgets, illustrating the role of abstractions in guiding meaningful exploration.
Subgraph Federated Learning for Local Generalization
Mar 06, 2025



Federated Learning (FL) on graphs enables collaborative model training to enhance performance without compromising the privacy of each client. However, existing methods often overlook the mutable nature of graph data, which frequently introduces new nodes and leads to shifts in label distribution. Since they focus solely on performing well on each client's local data, they are prone to overfitting to their local distributions (i.e., local overfitting), which hinders their ability to generalize to unseen data with diverse label distributions. In contrast, our proposed method, FedLoG, effectively tackles this issue by mitigating local overfitting. Our model generates global synthetic data by condensing the reliable information from each class representation and its structural information across clients. Using these synthetic data as a training set, we alleviate the local overfitting problem by adaptively generalizing the absent knowledge within each local dataset. This enhances the generalization capabilities of local models, enabling them to handle unseen data effectively. Our model outperforms baselines in our proposed experimental settings, which are designed to measure generalization power to unseen data in practical scenarios. Our code is available at https://github.com/sung-won-kim/FedLoG
Test-Time Alignment via Hypothesis Reweighting
Dec 11, 2024Large pretrained models often struggle with underspecified tasks -- situations where the training data does not fully define the desired behavior. For example, chatbots must handle diverse and often conflicting user preferences, requiring adaptability to various user needs. We propose a novel framework to address the general challenge of aligning models to test-time user intent, which is rarely fully specified during training. Our approach involves training an efficient ensemble, i.e., a single neural network with multiple prediction heads, each representing a different function consistent with the training data. Our main contribution is HyRe, a simple adaptation technique that dynamically reweights ensemble members at test time using a small set of labeled examples from the target distribution, which can be labeled in advance or actively queried from a larger unlabeled pool. By leveraging recent advances in scalable ensemble training, our method scales to large pretrained models, with computational costs comparable to fine-tuning a single model. We empirically validate HyRe in several underspecified scenarios, including personalization tasks and settings with distribution shifts. Additionally, with just five preference pairs from each target distribution, the same ensemble adapted via HyRe outperforms the prior state-of-the-art 2B-parameter reward model accuracy across 18 evaluation distributions.
Calibrating Language Models with Adaptive Temperature Scaling
Sep 29, 2024



The effectiveness of large language models (LLMs) is not only measured by their ability to generate accurate outputs but also by their calibration-how well their confidence scores reflect the probability of their outputs being correct. While unsupervised pre-training has been shown to yield LLMs with well-calibrated conditional probabilities, recent studies have shown that after fine-tuning with reinforcement learning from human feedback (RLHF), the calibration of these models degrades significantly. In this work, we introduce Adaptive Temperature Scaling (ATS), a post-hoc calibration method that predicts a temperature scaling parameter for each token prediction. The predicted temperature values adapt based on token-level features and are fit over a standard supervised fine-tuning (SFT) dataset. The adaptive nature of ATS addresses the varying degrees of calibration shift that can occur after RLHF fine-tuning. ATS improves calibration by over 10-50% across three downstream natural language evaluation benchmarks compared to prior calibration methods and does not impede performance improvements from RLHF.
Bidirectional Decoding: Improving Action Chunking via Closed-Loop Resampling
Aug 30, 2024



Predicting and executing a sequence of actions without intermediate replanning, known as action chunking, is increasingly used in robot learning from human demonstrations. However, its effects on learned policies remain puzzling: some studies highlight its importance for achieving strong performance, while others observe detrimental effects. In this paper, we first dissect the role of action chunking by analyzing the divergence between the learner and the demonstrator. We find that longer action chunks enable a policy to better capture temporal dependencies by taking into account more past states and actions within the chunk. However, this advantage comes at the cost of exacerbating errors in stochastic environments due to fewer observations of recent states. To address this, we propose Bidirectional Decoding (BID), a test-time inference algorithm that bridges action chunking with closed-loop operations. BID samples multiple predictions at each time step and searches for the optimal one based on two criteria: (i) backward coherence, which favors samples aligned with previous decisions, (ii) forward contrast, which favors samples close to outputs of a stronger policy and distant from those of a weaker policy. By coupling decisions within and across action chunks, BID enhances temporal consistency over extended sequences while enabling adaptive replanning in stochastic environments. Experimental results show that BID substantially outperforms conventional closed-loop operations of two state-of-the-art generative policies across seven simulation benchmarks and two real-world tasks.
Self-Explainable Temporal Graph Networks based on Graph Information Bottleneck
Jun 19, 2024



Temporal Graph Neural Networks (TGNN) have the ability to capture both the graph topology and dynamic dependencies of interactions within a graph over time. There has been a growing need to explain the predictions of TGNN models due to the difficulty in identifying how past events influence their predictions. Since the explanation model for a static graph cannot be readily applied to temporal graphs due to its inability to capture temporal dependencies, recent studies proposed explanation models for temporal graphs. However, existing explanation models for temporal graphs rely on post-hoc explanations, requiring separate models for prediction and explanation, which is limited in two aspects: efficiency and accuracy of explanation. In this work, we propose a novel built-in explanation framework for temporal graphs, called Self-Explainable Temporal Graph Networks based on Graph Information Bottleneck (TGIB). TGIB provides explanations for event occurrences by introducing stochasticity in each temporal event based on the Information Bottleneck theory. Experimental results demonstrate the superiority of TGIB in terms of both the link prediction performance and explainability compared to state-of-the-art methods. This is the first work that simultaneously performs prediction and explanation for temporal graphs in an end-to-end manner.
Self-Guided Masked Autoencoders for Domain-Agnostic Self-Supervised Learning
Feb 22, 2024



Self-supervised learning excels in learning representations from large amounts of unlabeled data, demonstrating success across multiple data modalities. Yet, extending self-supervised learning to new modalities is non-trivial because the specifics of existing methods are tailored to each domain, such as domain-specific augmentations which reflect the invariances in the target task. While masked modeling is promising as a domain-agnostic framework for self-supervised learning because it does not rely on input augmentations, its mask sampling procedure remains domain-specific. We present Self-guided Masked Autoencoders (SMA), a fully domain-agnostic masked modeling method. SMA trains an attention based model using a masked modeling objective, by learning masks to sample without any domain-specific assumptions. We evaluate SMA on three self-supervised learning benchmarks in protein biology, chemical property prediction, and particle physics. We find SMA is capable of learning representations without domain-specific knowledge and achieves state-of-the-art performance on these three benchmarks.
Clarify: Improving Model Robustness With Natural Language Corrections
Feb 06, 2024



In supervised learning, models are trained to extract correlations from a static dataset. This often leads to models that rely on high-level misconceptions. To prevent such misconceptions, we must necessarily provide additional information beyond the training data. Existing methods incorporate forms of additional instance-level supervision, such as labels for spurious features or additional labeled data from a balanced distribution. Such strategies can become prohibitively costly for large-scale datasets since they require additional annotation at a scale close to the original training data. We hypothesize that targeted natural language feedback about a model's misconceptions is a more efficient form of additional supervision. We introduce Clarify, a novel interface and method for interactively correcting model misconceptions. Through Clarify, users need only provide a short text description to describe a model's consistent failure patterns. Then, in an entirely automated way, we use such descriptions to improve the training process by reweighting the training data or gathering additional targeted data. Our user studies show that non-expert users can successfully describe model misconceptions via Clarify, improving worst-group accuracy by an average of 17.1% in two datasets. Additionally, we use Clarify to find and rectify 31 novel hard subpopulations in the ImageNet dataset, improving minority-split accuracy from 21.1% to 28.7%.