 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass
Jan 03, 2026We present UniSH, a unified, feed-forward framework for joint metric-scale 3D scene and human reconstruction. A key challenge in this domain is the scarcity of large-scale, annotated real-world data, forcing a reliance on synthetic datasets. This reliance introduces a significant sim-to-real domain gap, leading to poor generalization, low-fidelity human geometry, and poor alignment on in-the-wild videos. To address this, we propose an innovative training paradigm that effectively leverages unlabeled in-the-wild data. Our framework bridges strong, disparate priors from scene reconstruction and HMR, and is trained with two core components: (1) a robust distillation strategy to refine human surface details by distilling high-frequency details from an expert depth model, and (2) a two-stage supervision scheme, which first learns coarse localization on synthetic data, then fine-tunes on real data by directly optimizing the geometric correspondence between the SMPL mesh and the human point cloud. This approach enables our feed-forward model to jointly recover high-fidelity scene geometry, human point clouds, camera parameters, and coherent, metric-scale SMPL bodies, all in a single forward pass. Extensive experiments demonstrate that our model achieves state-of-the-art performance on human-centric scene reconstruction and delivers highly competitive results on global human motion estimation, comparing favorably against both optimization-based frameworks and HMR-only methods. Project page: https://murphylmf.github.io/UniSH/
Co$^{3}$Gesture: Towards Coherent Concurrent Co-speech 3D Gesture Generation with Interactive Diffusion
May 03, 2025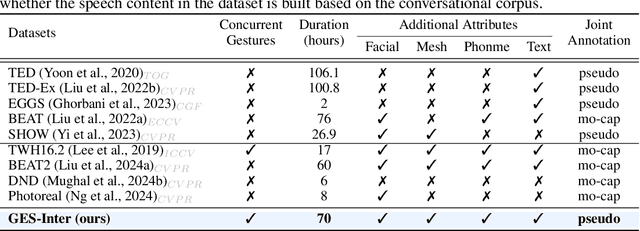

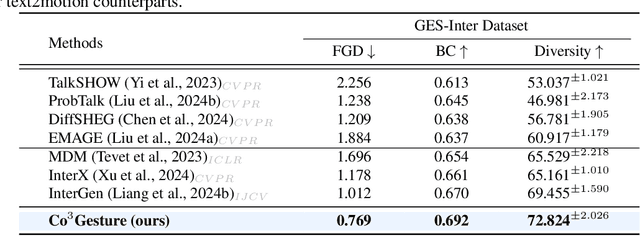
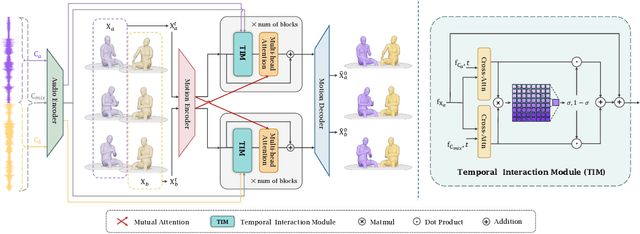
Generating gestures from human speech has gained tremendous progress in animating virtual avatars. While the existing methods enable synthesizing gestures cooperated by individual self-talking, they overlook the practicality of concurrent gesture modeling with two-person interactive conversations. Moreover, the lack of high-quality datasets with concurrent co-speech gestures also limits handling this issue. To fulfill this goal, we first construct a large-scale concurrent co-speech gesture dataset that contains more than 7M frames for diverse two-person interactive posture sequences, dubbed GES-Inter. Additionally, we propose Co$^3$Gesture, a novel framework that enables coherent concurrent co-speech gesture synthesis including two-person interactive movements. Considering the asymmetric body dynamics of two speakers, our framework is built upon two cooperative generation branches conditioned on separated speaker audio. Specifically, to enhance the coordination of human postures with respect to corresponding speaker audios while interacting with the conversational partner, we present a Temporal Interaction Module (TIM). TIM can effectively model the temporal association representation between two speakers' gesture sequences as interaction guidance and fuse it into the concurrent gesture generation. Then, we devise a mutual attention mechanism to further holistically boost learning dependencies of interacted concurrent motions, thereby enabling us to generate vivid and coherent gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected GES-Inter dataset. The dataset and source code are publicly available at \href{https://mattie-e.github.io/Co3/}{\textit{https://mattie-e.github.io/Co3/}}.
VividListener: Expressive and Controllable Listener Dynamics Modeling for Multi-Modal Responsive Interaction
Apr 30, 2025



Generating responsive listener head dynamics with nuanced emotions and expressive reactions is crucial for practical dialogue modeling in various virtual avatar animations. Previous studies mainly focus on the direct short-term production of listener behavior. They overlook the fine-grained control over motion variations and emotional intensity, especially in long-sequence modeling. Moreover, the lack of long-term and large-scale paired speaker-listener corpora including head dynamics and fine-grained multi-modality annotations (e.g., text-based expression descriptions, emotional intensity) also limits the application of dialogue modeling.Therefore, we first newly collect a large-scale multi-turn dataset of 3D dyadic conversation containing more than 1.4M valid frames for multi-modal responsive interaction, dubbed ListenerX. Additionally, we propose VividListener, a novel framework enabling fine-grained, expressive and controllable listener dynamics modeling. This framework leverages multi-modal conditions as guiding principles for fostering coherent interactions between speakers and listeners.Specifically, we design the Responsive Interaction Module (RIM) to adaptively represent the multi-modal interactive embeddings. RIM ensures the listener dynamics achieve fine-grained semantic coordination with textual descriptions and adjustments, while preserving expressive reaction with speaker behavior. Meanwhile, we design the Emotional Intensity Tags (EIT) for emotion intensity editing with multi-modal information integration, applying to both text descriptions and listener motion amplitude.Extensive experiments conducted on our newly collected ListenerX dataset demonstrate that VividListener achieves state-of-the-art performance, realizing expressive and controllable listener dynamics.
VFX Creator: Animated Visual Effect Generation with Controllable Diffusion Transformer
Feb 09, 2025Crafting magic and illusions is one of the most thrilling aspects of filmmaking, with visual effects (VFX) serving as the powerhouse behind unforgettable cinematic experiences. While recent advances in generative artificial intelligence have driven progress in generic image and video synthesis, the domain of controllable VFX generation remains relatively underexplored. In this work, we propose a novel paradigm for animated VFX generation as image animation, where dynamic effects are generated from user-friendly textual descriptions and static reference images. Our work makes two primary contributions: (i) Open-VFX, the first high-quality VFX video dataset spanning 15 diverse effect categories, annotated with textual descriptions, instance segmentation masks for spatial conditioning, and start-end timestamps for temporal control. (ii) VFX Creator, a simple yet effective controllable VFX generation framework based on a Video Diffusion Transformer. The model incorporates a spatial and temporal controllable LoRA adapter, requiring minimal training videos. Specifically, a plug-and-play mask control module enables instance-level spatial manipulation, while tokenized start-end motion timestamps embedded in the diffusion process, alongside the text encoder, allow precise temporal control over effect timing and pace. Extensive experiments on the Open-VFX test set demonstrate the superiority of the proposed system in generating realistic and dynamic effects, achieving state-of-the-art performance and generalization ability in both spatial and temporal controllability. Furthermore, we introduce a specialized metric to evaluate the precision of temporal control. By bridging traditional VFX techniques with generative approaches, VFX Creator unlocks new possibilities for efficient and high-quality video effect generation, making advanced VFX accessible to a broader audience.
Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control
Jan 07, 2025



Diffusion models have demonstrated impressive performance in generating high-quality videos from text prompts or images. However, precise control over the video generation process, such as camera manipulation or content editing, remains a significant challenge. Existing methods for controlled video generation are typically limited to a single control type, lacking the flexibility to handle diverse control demands. In this paper, we introduce Diffusion as Shader (DaS), a novel approach that supports multiple video control tasks within a unified architecture. Our key insight is that achieving versatile video control necessitates leveraging 3D control signals, as videos are fundamentally 2D renderings of dynamic 3D content. Unlike prior methods limited to 2D control signals, DaS leverages 3D tracking videos as control inputs, making the video diffusion process inherently 3D-aware. This innovation allows DaS to achieve a wide range of video controls by simply manipulating the 3D tracking videos. A further advantage of using 3D tracking videos is their ability to effectively link frames, significantly enhancing the temporal consistency of the generated videos. With just 3 days of fine-tuning on 8 H800 GPUs using less than 10k videos, DaS demonstrates strong control capabilities across diverse tasks, including mesh-to-video generation, camera control, motion transfer, and object manipulation.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024



Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
PSHuman: Photorealistic Single-view Human Reconstruction using Cross-Scale Diffusion
Sep 16, 2024



Detailed and photorealistic 3D human modeling is essential for various applications and has seen tremendous progress. However, full-body reconstruction from a monocular RGB image remains challenging due to the ill-posed nature of the problem and sophisticated clothing topology with self-occlusions. In this paper, we propose PSHuman, a novel framework that explicitly reconstructs human meshes utilizing priors from the multiview diffusion model. It is found that directly applying multiview diffusion on single-view human images leads to severe geometric distortions, especially on generated faces. To address it, we propose a cross-scale diffusion that models the joint probability distribution of global full-body shape and local facial characteristics, enabling detailed and identity-preserved novel-view generation without any geometric distortion. Moreover, to enhance cross-view body shape consistency of varied human poses, we condition the generative model on parametric models like SMPL-X, which provide body priors and prevent unnatural views inconsistent with human anatomy. Leveraging the generated multi-view normal and color images, we present SMPLX-initialized explicit human carving to recover realistic textured human meshes efficiently. Extensive experimental results and quantitative evaluations on CAPE and THuman2.1 datasets demonstrate PSHumans superiority in geometry details, texture fidelity, and generalization capability.
Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model
Aug 30, 2024



Recent advancements in audio generation have been significantly propelled by the capabilities of Large Language Models (LLMs). The existing research on audio LLM has primarily focused on enhancing the architecture and scale of audio language models, as well as leveraging larger datasets, and generally, acoustic codecs, such as EnCodec, are used for audio tokenization. However, these codecs were originally designed for audio compression, which may lead to suboptimal performance in the context of audio LLM. Our research aims to address the shortcomings of current audio LLM codecs, particularly their challenges in maintaining semantic integrity in generated audio. For instance, existing methods like VALL-E, which condition acoustic token generation on text transcriptions, often suffer from content inaccuracies and elevated word error rates (WER) due to semantic misinterpretations of acoustic tokens, resulting in word skipping and errors. To overcome these issues, we propose a straightforward yet effective approach called X-Codec. X-Codec incorporates semantic features from a pre-trained semantic encoder before the Residual Vector Quantization (RVQ) stage and introduces a semantic reconstruction loss after RVQ. By enhancing the semantic ability of the codec, X-Codec significantly reduces WER in speech synthesis tasks and extends these benefits to non-speech applications, including music and sound generation. Our experiments in text-to-speech, music continuation, and text-to-sound tasks demonstrate that integrating semantic information substantially improves the overall performance of language models in audio generation. Our code and demo are available (Demo: https://x-codec-audio.github.io Code: https://github.com/zhenye234/xcodec)
Importance Weighting Can Help Large Language Models Self-Improve
Aug 19, 2024



Large language models (LLMs) have shown remarkable capability in numerous tasks and applications. However, fine-tuning LLMs using high-quality datasets under external supervision remains prohibitively expensive. In response, LLM self-improvement approaches have been vibrantly developed recently. The typical paradigm of LLM self-improvement involves training LLM on self-generated data, part of which may be detrimental and should be filtered out due to the unstable data quality. While current works primarily employs filtering strategies based on answer correctness, in this paper, we demonstrate that filtering out correct but with high distribution shift extent (DSE) samples could also benefit the results of self-improvement. Given that the actual sample distribution is usually inaccessible, we propose a new metric called DS weight to approximate DSE, inspired by the Importance Weighting methods. Consequently, we integrate DS weight with self-consistency to comprehensively filter the self-generated samples and fine-tune the language model. Experiments show that with only a tiny valid set (up to 5\% size of the training set) to compute DS weight, our approach can notably promote the reasoning ability of current LLM self-improvement methods. The resulting performance is on par with methods that rely on external supervision from pre-trained reward models.
STBLLM: Breaking the 1-Bit Barrier with Structured Binary LLMs
Aug 03, 2024



In this paper, we present STBLLM, the first structural binarization framework for compressing Large Language Models (LLMs) to less than 1-bit precision. LLMs have achieved remarkable performance, but their heavy memory requirements have hindered widespread adoption, particularly on resource-constrained devices. Binarization, which quantifies weights to a mere 1-bit, achieves a milestone in increasing computational efficiency. However, we observe that some weights in binarized LLMs can be randomly flipped without significant performance degradation, indicating the potential for further compression. To exploit this, our STBLLM employs an N:M sparsity to perform structural binarization of the weights. First, we introduce a new Standardized Importance (SI) metric that considers weight magnitude and input feature norm to better evaluate weight significance. Then, we propose a layer-wise approach where different layers of the LLM can be sparsified with varying N:M ratios, balancing compression and accuracy. Finally, we use residual approximation with double binarization to preserve information for salient weights. In addition, we utilize a fine-grained grouping strategy for less important weights that applies different quantization schemes to sparse, intermediate, and dense regions. We conduct extensive experiments on various language models, including the LLaMA-1/2/3, OPT family, and Mistral, to evaluate the effectiveness of STBLLM. The results demonstrate that our approach performs better than other compressed binarization LLM methods while significantly reducing memory requirements.