 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Speech Representation Better Matches Text-Native Reasoning? A Study of Speech-Text Alignment on Frame Rate and Representation
Jun 10, 2026Spoken dialogue models typically start from text LLM backbones, yet reasoning often degrades when conditioning on speech instead of text. We attribute part of this modality gap to a temporal-granularity mismatch: speech tokens are temporally redundant and far longer than text under matched semantics, diluting per-token semantic density and weakening text-native reasoning dynamics. We study speech token design as a representation selection problem and sweep frame rates under a frozen LLM backbone with a fixed information rate. To make low frame rates feasible, we introduce factorized FSQ and a lightweight non-autoregressive audio LM head, scaling capacity to nearly 300\,bits/frame without sacrificing efficient prediction. With the bottleneck removed, we sweep frame rates (50$\rightarrow$2.08\,Hz) and alignment depth, and observe a consistent best regime for speech QA at 4.17\,Hz with intermediate-layer representation alignment.
Talker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
Apr 26, 2026Joint audio-video generation models have shown that unified generation yields stronger cross-modal coherence than cascaded approaches. However, existing models couple modalities throughout denoising via pervasive attention, treating high-level semantics and low-level details in a fully entangled manner. This is suboptimal for talking head synthesis: while audio and facial motion are semantically correlated, their low-level realizations (acoustic signals and visual textures) follow distinct rendering processes. Enforcing joint modeling across all levels causes unnecessary entanglement and reduces efficiency. We propose Talker-T2AV, an autoregressive diffusion framework where high-level cross-modal modeling occurs in a shared backbone, while low-level refinement uses modality-specific decoders. A shared autoregressive language model jointly reasons over audio and video in a unified patch-level token space. Two lightweight diffusion transformer heads decode the hidden states into frame-level audio and video latents. Experiments on talking portrait benchmarks show Talker-T2AV outperforms dual-branch baselines in lip-sync accuracy, video quality, and audio quality, achieving stronger cross-modal consistency than cascaded pipelines.
A Graph-Enhanced Defense Framework for Explainable Fake News Detection with LLM
Apr 08, 2026Explainable fake news detection aims to assess the veracity of news claims while providing human-friendly explanations. Existing methods incorporating investigative journalism are often inefficient and struggle with breaking news. Recent advances in large language models (LLMs) enable leveraging externally retrieved reports as evidence for detection and explanation generation, but unverified reports may introduce inaccuracies. Moreover, effective explainable fake news detection should provide a comprehensible explanation for all aspects of a claim to assist the public in verifying its accuracy. To address these challenges, we propose a graph-enhanced defense framework (G-Defense) that provides fine-grained explanations based solely on unverified reports. Specifically, we construct a claim-centered graph by decomposing the news claim into several sub-claims and modeling their dependency relationships. For each sub-claim, we use the retrieval-augmented generation (RAG) technique to retrieve salient evidence and generate competing explanations. We then introduce a defense-like inference module based on the graph to assess the overall veracity. Finally, we prompt an LLM to generate an intuitive explanation graph. Experimental results demonstrate that G-Defense achieves state-of-the-art performance in both veracity detection and the quality of its explanations.
Probabilistic Concept Graph Reasoning for Multimodal Misinformation Detection
Mar 26, 2026Multimodal misinformation poses an escalating challenge that often evades traditional detectors, which are opaque black boxes and fragile against new manipulation tactics. We present Probabilistic Concept Graph Reasoning (PCGR), an interpretable and evolvable framework that reframes multimodal misinformation detection (MMD) as structured and concept-based reasoning. PCGR follows a build-then-infer paradigm, which first constructs a graph of human-understandable concept nodes, including novel high-level concepts automatically discovered and validated by multimodal large language models (MLLMs), and then applies hierarchical attention over this concept graph to infer claim veracity. This design produces interpretable reasoning chains linking evidence to conclusions. Experiments demonstrate that PCGR achieves state-of-the-art MMD accuracy and robustness to emerging manipulation types, outperforming prior methods in both coarse detection and fine-grained manipulation recognition.
DiffCoT: Diffusion-styled Chain-of-Thought Reasoning in LLMs
Jan 07, 2026Chain-of-Thought (CoT) reasoning improves multi-step mathematical problem solving in large language models but remains vulnerable to exposure bias and error accumulation, as early mistakes propagate irreversibly through autoregressive decoding. In this work, we propose DiffCoT, a diffusion-styled CoT framework that reformulates CoT reasoning as an iterative denoising process. DiffCoT integrates diffusion principles at the reasoning-step level via a sliding-window mechanism, enabling unified generation and retrospective correction of intermediate steps while preserving token-level autoregression. To maintain causal consistency, we further introduce a causal diffusion noise schedule that respects the temporal structure of reasoning chains. Extensive experiments on three multi-step CoT reasoning benchmarks across diverse model backbones demonstrate that DiffCoT consistently outperforms existing CoT preference optimization methods, yielding improved robustness and error-correction capability in CoT reasoning.
Towards Comprehensive Stage-wise Benchmarking of Large Language Models in Fact-Checking
Jan 06, 2026Large Language Models (LLMs) are increasingly deployed in real-world fact-checking systems, yet existing evaluations focus predominantly on claim verification and overlook the broader fact-checking workflow, including claim extraction and evidence retrieval. This narrow focus prevents current benchmarks from revealing systematic reasoning failures, factual blind spots, and robustness limitations of modern LLMs. To bridge this gap, we present FactArena, a fully automated arena-style evaluation framework that conducts comprehensive, stage-wise benchmarking of LLMs across the complete fact-checking pipeline. FactArena integrates three key components: (i) an LLM-driven fact-checking process that standardizes claim decomposition, evidence retrieval via tool-augmented interactions, and justification-based verdict prediction; (ii) an arena-styled judgment mechanism guided by consolidated reference guidelines to ensure unbiased and consistent pairwise comparisons across heterogeneous judge agents; and (iii) an arena-driven claim-evolution module that adaptively generates more challenging and semantically controlled claims to probe LLMs' factual robustness beyond fixed seed data. Across 16 state-of-the-art LLMs spanning seven model families, FactArena produces stable and interpretable rankings. Our analyses further reveal significant discrepancies between static claim-verification accuracy and end-to-end fact-checking competence, highlighting the necessity of holistic evaluation. The proposed framework offers a scalable and trustworthy paradigm for diagnosing LLMs' factual reasoning, guiding future model development, and advancing the reliable deployment of LLMs in safety-critical fact-checking applications.
Explainable Ethical Assessment on Human Behaviors by Generating Conflicting Social Norms
Dec 16, 2025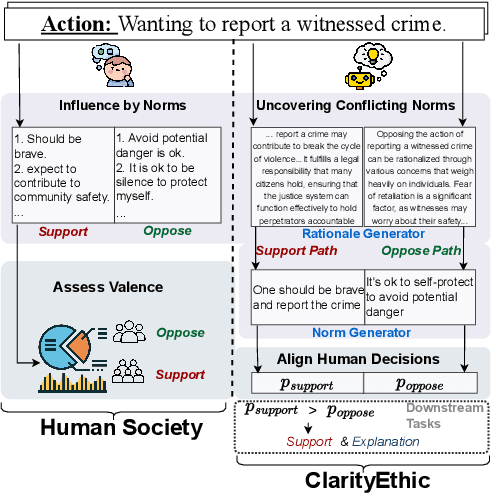
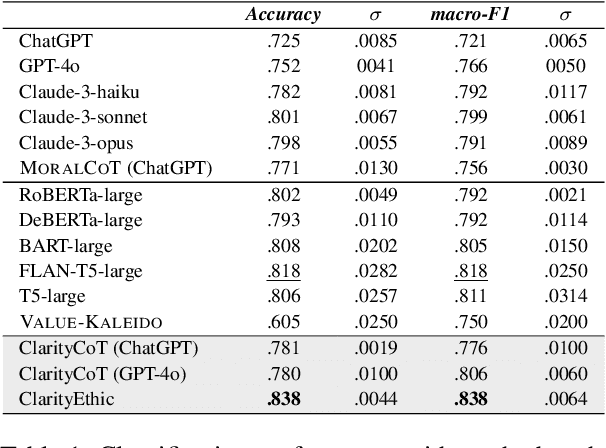
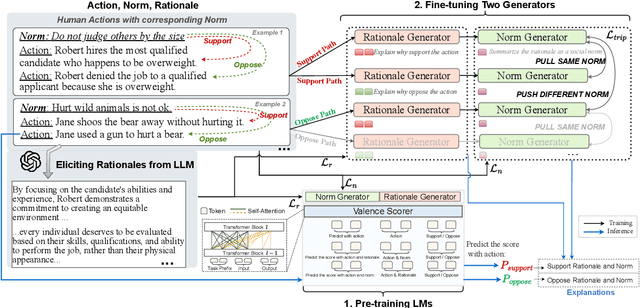
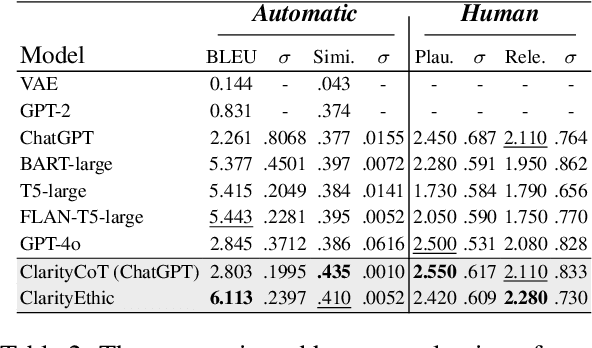
Human behaviors are often guided or constrained by social norms, which are defined as shared, commonsense rules. For example, underlying an action ``\textit{report a witnessed crime}" are social norms that inform our conduct, such as ``\textit{It is expected to be brave to report crimes}''. Current AI systems that assess valence (i.e., support or oppose) of human actions by leveraging large-scale data training not grounded on explicit norms may be difficult to explain, and thus untrustworthy. Emulating human assessors by considering social norms can help AI models better understand and predict valence. While multiple norms come into play, conflicting norms can create tension and directly influence human behavior. For example, when deciding whether to ``\textit{report a witnessed crime}'', one may balance \textit{bravery} against \textit{self-protection}. In this paper, we introduce \textit{ClarityEthic}, a novel ethical assessment approach, to enhance valence prediction and explanation by generating conflicting social norms behind human actions, which strengthens the moral reasoning capabilities of language models by using a contrastive learning strategy. Extensive experiments demonstrate that our method outperforms strong baseline approaches, and human evaluations confirm that the generated social norms provide plausible explanations for the assessment of human behaviors.
MM-CRITIC: A Holistic Evaluation of Large Multimodal Models as Multimodal Critique
Nov 12, 2025



The ability of critique is vital for models to self-improve and serve as reliable AI assistants. While extensively studied in language-only settings, multimodal critique of Large Multimodal Models (LMMs) remains underexplored despite their growing capabilities in tasks like captioning and visual reasoning. In this work, we introduce MM-CRITIC, a holistic benchmark for evaluating the critique ability of LMMs across multiple dimensions: basic, correction, and comparison. Covering 8 main task types and over 500 tasks, MM-CRITIC collects responses from various LMMs with different model sizes and is composed of 4471 samples. To enhance the evaluation reliability, we integrate expert-informed ground answers into scoring rubrics that guide GPT-4o in annotating responses and generating reference critiques, which serve as anchors for trustworthy judgments. Extensive experiments validate the effectiveness of MM-CRITIC and provide a comprehensive assessment of leading LMMs' critique capabilities under multiple dimensions. Further analysis reveals some key insights, including the correlation between response quality and critique, and varying critique difficulty across evaluation dimensions. Our code is available at https://github.com/MichealZeng0420/MM-Critic.
MemeArena: Automating Context-Aware Unbiased Evaluation of Harmfulness Understanding for Multimodal Large Language Models
Oct 31, 2025The proliferation of memes on social media necessitates the capabilities of multimodal Large Language Models (mLLMs) to effectively understand multimodal harmfulness. Existing evaluation approaches predominantly focus on mLLMs' detection accuracy for binary classification tasks, which often fail to reflect the in-depth interpretive nuance of harmfulness across diverse contexts. In this paper, we propose MemeArena, an agent-based arena-style evaluation framework that provides a context-aware and unbiased assessment for mLLMs' understanding of multimodal harmfulness. Specifically, MemeArena simulates diverse interpretive contexts to formulate evaluation tasks that elicit perspective-specific analyses from mLLMs. By integrating varied viewpoints and reaching consensus among evaluators, it enables fair and unbiased comparisons of mLLMs' abilities to interpret multimodal harmfulness. Extensive experiments demonstrate that our framework effectively reduces the evaluation biases of judge agents, with judgment results closely aligning with human preferences, offering valuable insights into reliable and comprehensive mLLM evaluations in multimodal harmfulness understanding. Our code and data are publicly available at https://github.com/Lbotirx/MemeArena.
EvolProver: Advancing Automated Theorem Proving by Evolving Formalized Problems via Symmetry and Difficulty
Oct 01, 2025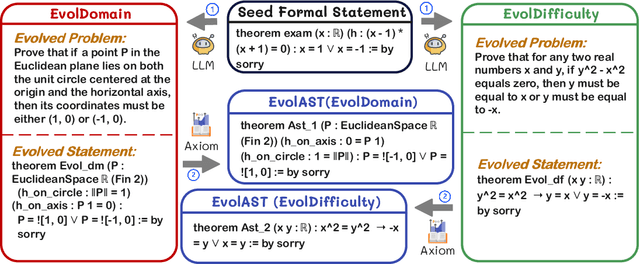
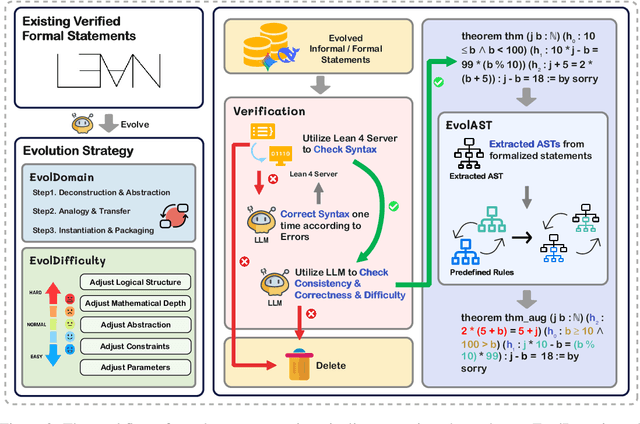
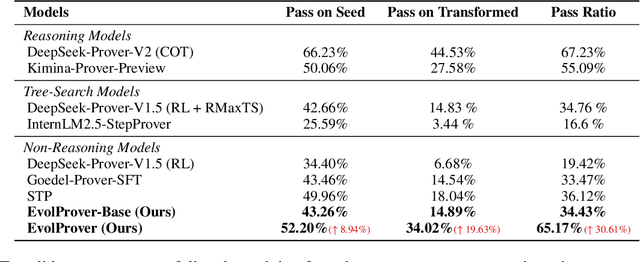

Large Language Models (LLMs) for formal theorem proving have shown significant promise, yet they often lack generalizability and are fragile to even minor transformations of problem statements. To address this limitation, we introduce a novel data augmentation pipeline designed to enhance model robustness from two perspectives: symmetry and difficulty. From the symmetry perspective, we propose two complementary methods: EvolAST, an Abstract Syntax Tree (AST) based approach that targets syntactic symmetry to generate semantically equivalent problem variants, and EvolDomain, which leverages LLMs to address semantic symmetry by translating theorems across mathematical domains. From the difficulty perspective, we propose EvolDifficulty, which uses carefully designed evolutionary instructions to guide LLMs in generating new theorems with a wider range of difficulty. We then use the evolved data to train EvolProver, a 7B-parameter non-reasoning theorem prover. EvolProver establishes a new state-of-the-art (SOTA) on FormalMATH-Lite with a 53.8% pass@32 rate, surpassing all models of comparable size, including reasoning-based models. It also sets new SOTA records for non-reasoning models on MiniF2F-Test (69.8% pass@32), Ineq-Comp-Seed (52.2% pass@32), and Ineq-Comp-Transformed (34.0% pass@32). Ablation studies further confirm our data augmentation pipeline's effectiveness across multiple benchmarks.